cc100-documents
收藏Hugging Face2025-11-10 更新2025-11-11 收录
下载链接:
https://huggingface.co/datasets/singletongue/cc100-documents
下载链接
链接失效反馈官方服务:
资源简介:
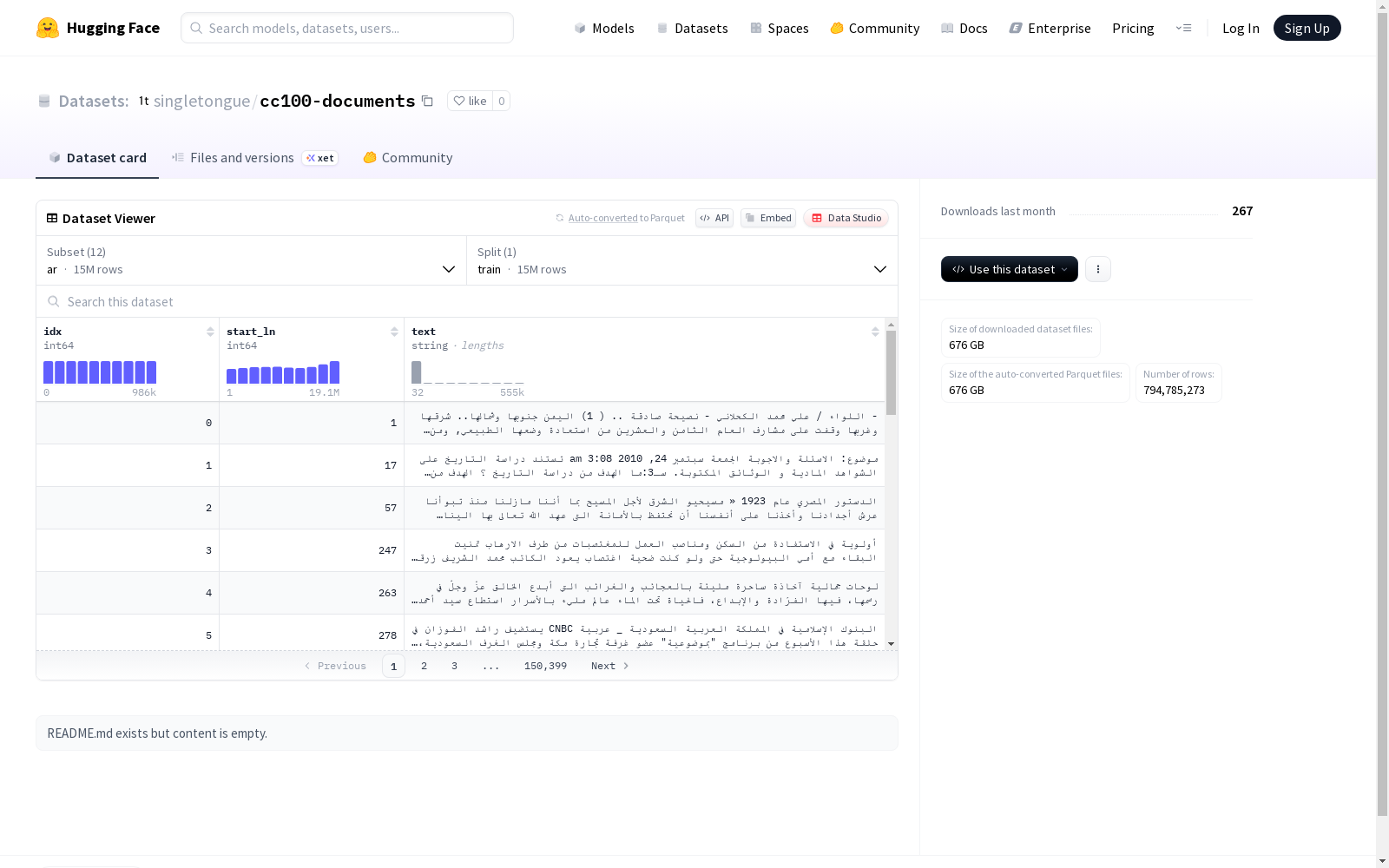
这是一个多语言文本数据集,包含阿拉伯语、德语、英语、西班牙语、法语、意大利语、日语、韩语和葡萄牙语等多种语言的文本数据。每种语言都有单独的训练集,数据集以索引、起始行号和文本内容为特征。数据集规模较大,不同语言配置的训练集大小和示例数量不同。
This is a multilingual text dataset containing text data in multiple languages including Arabic, German, English, Spanish, French, Italian, Japanese, Korean, and Portuguese. Each language has its own separate training set. The dataset is characterized by index, starting line number, and text content. It has a large scale, and the sizes and sample counts of the training sets vary across different languages.
创建时间:
2025-11-10
原始信息汇总
CC100 Documents 数据集概述
数据集基本信息
- 数据集名称: CC100 Documents
- 存储位置: https://huggingface.co/datasets/singletongue/cc100-documents
- 数据格式: 多语言文档数据集
语言配置详情
阿拉伯语 (ar)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 15,039,879
- 数据集大小: 30,345,714,473 字节
- 下载大小: 15,115,802,825 字节
德语 (de)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 69,023,867
- 数据集大小: 72,775,978,455 字节
- 下载大小: 45,855,033,322 字节
英语 (en)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 247,588,106
- 数据集大小: 327,673,321,587 字节
- 下载大小: 206,842,211,484 字节
西班牙语 (es)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 60,542,096
- 数据集大小: 58,353,909,888 字节
- 下载大小: 36,639,924,361 字节
法语 (fr)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 62,112,712
- 数据集大小: 62,167,991,656 字节
- 下载大小: 38,687,566,994 字节
意大利语 (it)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 24,674,591
- 数据集大小: 32,862,817,488 字节
- 下载大小: 20,840,201,122 字节
日语 (ja)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 65,613,665
- 数据集大小: 75,607,021,621 字节
- 下载大小: 43,271,734,711 字节
韩语 (ko)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 35,678,358
- 数据集大小: 58,828,056,524 字节
- 下载大小: 34,859,494,100 字节
葡萄牙语 (pt)
- 特征字段:
- idx (int64)
- start_ln (int64)
- text (string)
- 训练集统计:
- 样本数量: 38,999,388
- 数据集大小: 53,502,662,440 字节
- 下载大小: 33,751,151,154 字节
数据文件结构
所有语言配置均包含单一训练集分割,数据文件路径格式为:{语言代码}/train-*
搜集汇总
数据集介绍
构建方式
在跨语言自然语言处理研究领域,CC100-documents数据集的构建采用了大规模网络文档的自动化采集策略。该数据集从Common Crawl项目中提取原始网页内容,通过语言识别算法将文档按语种分类,并运用去重和清洗流程去除低质量文本。每种语言的文档被独立整理为标准化格式,保留了原始文本的结构特征,形成了覆盖阿拉伯语、德语、英语、西班牙语、法语、意大利语、日语、韩语和葡萄牙语的多语言语料库。
使用方法
研究人员可通过HuggingFace数据集库直接加载CC100-documents,使用标准接口按语言配置名称调用特定语种子集。该数据集适用于跨语言预训练任务,支持基于Transformer架构的神经网络的分布式训练。在具体应用中,用户可通过文本索引字段实现高效的数据切片与批处理,起始行号则为文档级语言建模提供了位置参照。该资源还可服务于多语言词向量学习、语言识别模型构建等下游任务,为自然语言处理研究提供基础数据支撑。
背景与挑战
背景概述
在跨语言自然语言处理研究蓬勃发展的背景下,cc100-documents数据集应运而生,由Facebook AI Research团队于2020年构建完成。该数据集致力于解决多语言文本理解与生成的核心研究问题,涵盖阿拉伯语、德语、英语、西班牙语、法语、意大利语、日语、韩语和葡萄牙语九种语言,总数据量超过700GB。其大规模多语言特性为跨语言预训练模型提供了重要支撑,显著推动了XLM-R等跨语言模型的性能突破,对机器翻译、跨语言信息检索等领域产生深远影响。
当前挑战
多语言文本理解面临的核心挑战在于语言间的语义对齐与表征学习,cc100-documents需解决不同语系语法结构差异、词汇语义不对等等难题。构建过程中遭遇的挑战尤为突出:网络文本质量参差不齐要求设计复杂的过滤机制,数据去重与隐私保护需要精细的预处理流程,九种语言的字符编码与文本规范化处理增加了技术复杂度,同时保持各语种数据规模平衡也面临实际困难。
常用场景
经典使用场景
在跨语言自然语言处理研究中,CC100-documents数据集作为大规模多语言语料库,常被用于预训练语言模型。其涵盖阿拉伯语、德语、英语、西班牙语、法语、意大利语、日语、韩语和葡萄牙语等多种语言,为模型提供丰富的语言多样性数据,支持跨语言迁移学习和语言理解任务的开发。
解决学术问题
该数据集有效解决了多语言自然语言处理中数据稀缺和语言不平衡的学术难题。通过提供大规模、高质量的多语言文本,促进了跨语言词嵌入、机器翻译和语言模型预训练等领域的研究,显著提升了模型在低资源语言上的性能,推动了语言技术在全球范围内的普及。
实际应用
在实际应用中,CC100-documents数据集被广泛用于构建多语言搜索引擎、智能客服系统和内容推荐引擎。其多语言特性支持企业开发全球化产品,例如在电子商务和社交媒体平台中实现跨语言内容理解和生成,提升用户体验并拓展国际市场。
数据集最近研究
最新研究方向
在跨语言自然语言处理领域,CC100-documents凭借其覆盖阿拉伯语、德语、英语等九种语言的文档资源,已成为多语言预训练模型研究的重要基石。当前研究聚焦于探索语言间的隐式语义关联,通过对比学习与跨语言掩码语言建模技术,显著提升了低资源语言的表示能力。随着大语言模型在多语种应用场景的扩展,该数据集在消除文化偏见、构建语言无关的语义空间方面展现出关键价值,为全球化人工智能系统的伦理部署提供了数据支撑。
以上内容由遇见数据集搜集并总结生成


