pii-masking-benchmark
收藏Hugging Face2026-04-27 更新2026-04-28 收录
下载链接:
https://huggingface.co/datasets/piimb/pii-masking-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
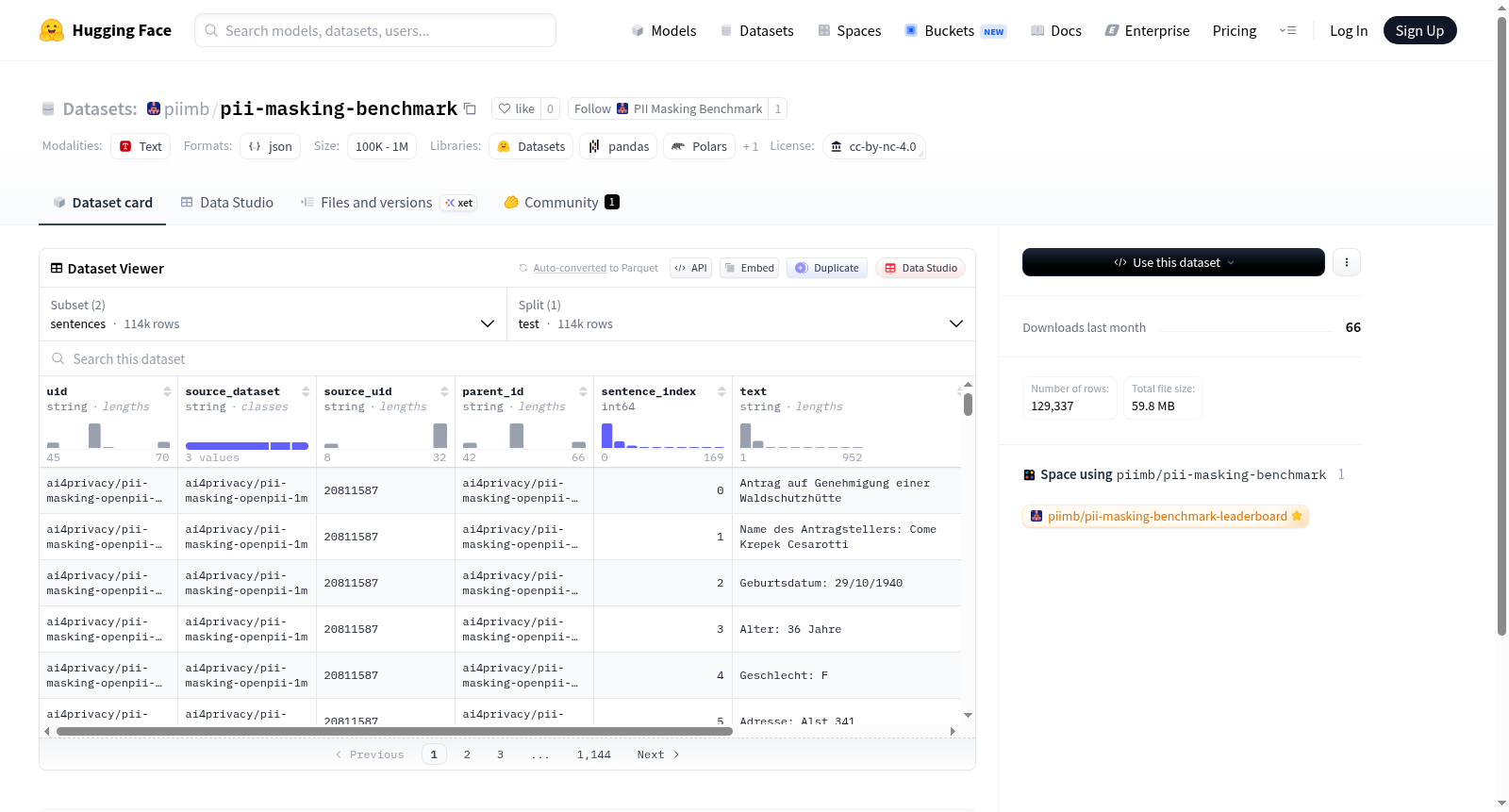
该数据集基于CC BY-NC 4.0许可协议,提供两种配置:full_text和sentences。full_text配置包含存储在data/test.jsonl中的测试集,而默认的sentences配置则包含存储在data/test_sentences.jsonl中的测试集。README未提供数据集的具体目的、内容、结构或预期用例,因此描述仅基于配置和文件存储信息。
This dataset is licensed under CC BY-NC 4.0 and includes two configurations: full_text and sentences. The full_text configuration contains a test set stored in data/test.jsonl, while the default sentences configuration contains a test set stored in data/test_sentences.jsonl. The README does not provide detailed information on the datasets purpose, content, structure, or intended use cases, so the description is based solely on configuration and file storage details.
创建时间:
2026-04-25
原始信息汇总
基于您提供的信息,以下是该数据集的总结:
数据集概述
- 数据集名称: pii-masking-benchmark
- 发布机构: piimb
- 许可证: CC BY-NC 4.0(知识共享-非商业使用 4.0 国际许可协议)
- 数据集地址: https://huggingface.co/datasets/piimb/pii-masking-benchmark
数据集配置
该数据集包含两个配置子集,均仅提供测试集:
- full_text: 数据文件为
data/test.jsonl,提供完整的文本格式数据。 - sentences: 数据文件为
data/test_sentences.jsonl,提供句子级格式的数据。
数据用途
该数据集为PII(个人身份信息)掩码基准测试数据集,主要用于评估或训练模型在文本中识别并掩码敏感个人信息的能力。
注意事项
- 该数据集仅包含测试集,不包含训练或验证集。
- 数据遵循非商业使用许可协议。
搜集汇总
数据集介绍
构建方式
该数据集名为pii-masking-benchmark,旨在评估对个人身份信息(PII)进行掩码处理的能力。构建方式包含两种配置:全文本模式(full_text)和句子模式(sentences)。其中,全文本模式存储于data/test.jsonl文件中,保留了原始文本的完整性;句子模式则基于句子分割后的数据,存放于data/test_sentences.jsonl文件中,便于细粒度分析。默认配置为句子模式,强调了句子级掩码评估的实用性。数据采用JSONL格式组织,每行对应一个独立的数据实例,通过明确的分割标志划分为测试集,支持标准化基准测试。
特点
该数据集的核心特点在于其双重配置设计,能够灵活适应不同粒度的PII掩码任务需求。全文本配置保留了上下文关联性,适合评估模型在完整篇章中的掩码表现;句子配置则将文本细化为独立单元,降低了上下文干扰,利于聚焦于局部PII识别。数据来源未公开,但采用cc-by-nc-4.0许可协议,限制了非商业用途,保障了隐私合规。此外,数据集以测试集形式提供,无训练集分割,凸显其作为基准测试而非训练资源的定位,强调评估的客观性与一致性。
使用方法
使用方法上,用户可通过HuggingFace数据集库直接加载该资源。加载时需指定配置名称,例如使用'sentences'配置时调用load_dataset('pii-masking-benchmark', 'sentences'),默认即采用此模式;若需全文本数据,则指定'full_text'配置。数据以JSONL格式呈现,可轻松转化为DataFrame或列表,便于进行掩码模型评估。建议用户结合隐私保护框架,利用该数据集测试模型在识别并隐藏姓名、地址、身份证号等PII实体上的性能,评估指标可包括掩码准确率与召回率。
背景与挑战
背景概述
pii-masking-benchmark数据集由研究机构于近期创建,旨在评估和提升自然语言处理模型中个人可识别信息(PII)的掩码能力。随着数据隐私法规(如GDPR)的严格实施,如何在文本处理中有效脱敏PII已成为关键研究问题。该数据集包含全文本和句子两种配置,为模型在真实场景下的隐私保护性能提供了标准化测试基准,推动了隐私感知NLP技术的发展。
当前挑战
该数据集面临的挑战包括:1)在领域问题层面,现有PII识别模型常因语境复杂(如缩写、拼写变异或上下文依赖)导致误判,亟需更鲁棒的语义理解;2)构建过程中,标注PII边界需平衡隐私暴露风险与数据可用性,且不同语种、文化下的PII定义差异增加了标注一致性难度,同时需模拟真实分布中的罕见PII类型以增强泛化性。
常用场景
经典使用场景
在自然语言处理领域,隐私保护日益成为研究焦点。pii-masking-benchmark数据集专为评估与优化个人可识别信息(PII)掩码系统而设计,其经典使用场景涵盖从原始文本中精准识别并遮蔽姓名、身份证号、电话号码等敏感信息。研究者借助该数据集,能够系统性地测试不同掩码算法在多样文本语境中的表现,尤其关注掩码后文本语义的完整性保持与隐私泄露风险之间的平衡。这一基准为开发更安全、更鲁棒的文本脱敏技术提供了标准化的评估平台。
解决学术问题
学术界长期面临的一个核心难题是如何在保障文本可用性的前提下,有效消除其中的隐私成分。pii-masking-benchmark数据集通过提供标注精细的测试样本,使得研究人员能够量化评估掩码方法在召回率、精准度及掩码后文本流畅度上的综合效果。它解决了传统评估中缺乏统一对照基准的困境,推动了隐私保护自然语言处理(Privacy-Preserving NLP)领域的标准化进程。其意义在于为后续研究提供了可复现的评测范式,加速了高性能掩码算法的涌现。
衍生相关工作
基于pii-masking-benchmark数据集,研究者已产出多项标志性工作。例如,部分团队利用该基准开发了基于上下文感知的掩码策略,显著优于传统的规则匹配方法;另有工作探索了差分隐私与掩码技术的融合路径,在保障正式指标的同时提升抗推理攻击能力。此外,该数据集催生了针对多语言PII识别的迁移学习研究,推动了跨语言隐私保护模型的泛化。这些衍生工作共同深化了人类对文本隐私边界的理解,也为下一代隐私保护技术奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


