wdndev/webnovel-chinese
收藏Hugging Face2024-04-04 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/wdndev/webnovel-chinese
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- text-generation
language:
- zh
tags:
- llm
- pretrain
size_categories:
- 1B<n<10B
---
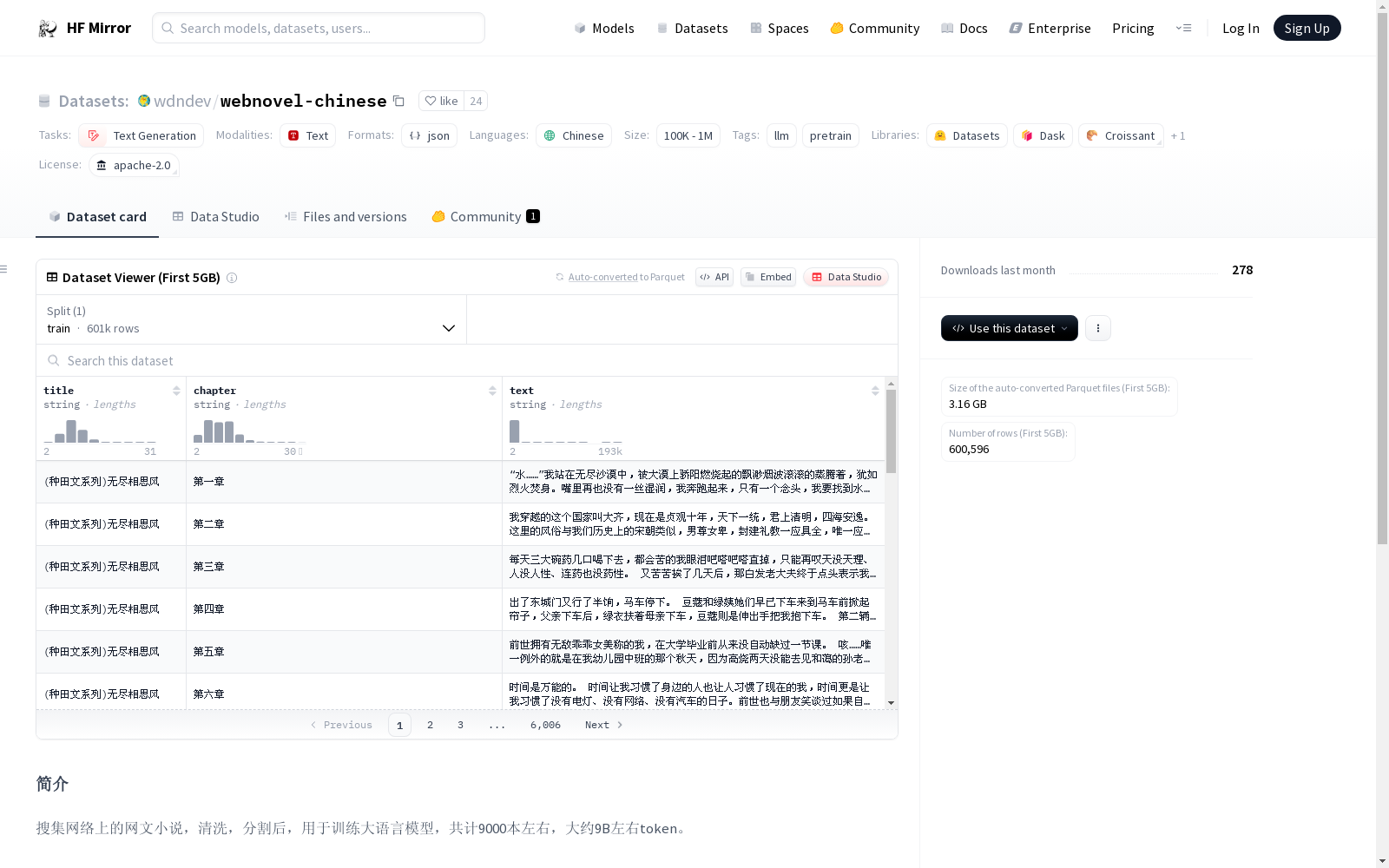
## 简介
搜集网络上的网文小说,清洗,分割后,用于训练大语言模型,共计9000本左右,大约9B左右token。
## 使用
### 格式说明
采用`jsonl`格式存储,分为三个字段:
- `title` :小说名称
- `chapter`:章节
- `text`:正文内容
示例:
```json
{"title": "斗破苍穹", "chapter": " 第一章 陨落的天才", "text": "“斗之力,三段!”\n望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛……\n“萧炎,斗之力,三段!级别:低级!”测验魔石碑之旁,一位中年男子,看了一眼碑上所显示出来的信息,语气漠然的将之公布了出来……\n"}
```
license: apache-2.0
task_categories:
- text-generation
language:
- zh
tags:
- llm
- pretrain
size_categories:
- 1B<n<10B
### Introduction
Collected, cleaned and segmented from online web novels, this dataset is intended for training Large Language Models (LLMs). It contains approximately 9,000 novels and around 9 billion tokens.
### Usage
#### Format Specification
The dataset is stored in `jsonl` format, consisting of three core fields:
- `title`: The name of the novel
- `chapter`: The chapter information
- `text`: The main body content of the chapter
Example:
json
{"title": "斗破苍穹", "chapter": " 第一章 陨落的天才", "text": "“斗之力,三段!”
望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛……
“萧炎,斗之力,三段!级别:低级!”测验魔石碑之旁,一位中年男子,看了一眼碑上所显示出来的信息,语气漠然的将之公布了出来……
"}
提供机构:
wdndev
原始信息汇总
数据集概述
基本信息
- 许可证:Apache-2.0
- 任务类别:文本生成
- 语言:中文
- 标签:大语言模型(LLM)、预训练
- 大小类别:1B<n<10B
数据集内容
- 数据来源:网络上的网文小说
- 处理过程:清洗、分割
- 数据量:约9000本小说,总计约9B token
数据格式
- 存储格式:
jsonl - 字段说明:
title:小说名称chapter:章节text:正文内容
示例数据
json {"title": "斗破苍穹", "chapter": " 第一章 陨落的天才", "text": "“斗之力,三段!” 望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛…… “萧炎,斗之力,三段!级别:低级!”测验魔石碑之旁,一位中年男子,看了一眼碑上所显示出来的信息,语气漠然的将之公布了出来…… "}
搜集汇总
数据集介绍
构建方式
该数据集的构建,始于对网络空间广泛搜集的网文小说资源进行严格筛选与清洗。经过细致的分割处理,最终形成了一个包含约9000本小说,总计约9B token的文本集合,旨在为大规模语言模型的训练提供丰富而多样的文本素材。
使用方法
用户在使用该数据集时,可以轻松地通过其`jsonl`格式进行读取,每个记录包含的`title`、`chapter`和`text`字段使得数据集能够方便地应用于文本生成等任务。用户可以根据具体需求,对数据集进行相应的预处理或后处理,以适应不同的模型训练或文本分析任务。
背景与挑战
背景概述
在自然语言处理领域,语言模型的预训练是提升模型性能的关键步骤。为此,wdndev/webnovel-chinese数据集应运而生,该数据集创建于现代,由wdndev团队搜集并整理。该数据集的核心研究问题是如何通过大规模的中文网络小说语料库,训练出能够理解和生成自然中文的大语言模型。该数据集的构建,为中文语言模型的研究与开发提供了宝贵的资源,对相关领域产生了深远的影响。
当前挑战
数据集在构建过程中遭遇了诸多挑战,如网络小说的版权问题、文本清洗和格式统一的困难等。此外,在所解决的领域问题方面,如何确保训练出的语言模型能够准确捕捉中文网络小说的语言特点,生成符合语境的文本,是一个持续的挑战。同时,由于网络小说内容的多样性和复杂性,对模型的泛化能力提出了更高的要求。
常用场景
经典使用场景
在自然语言处理领域,wdndev/webnovel-chinese数据集以其丰富的文本生成资源而备受青睐。该数据集通常被用于训练大型语言模型,以提升模型在文本生成任务上的表现,如创作小说、生成对话等,为模型提供充足的学习材料,从而使得生成的文本在语言风格、情节连贯性等方面更加贴近真实的网文小说。
解决学术问题
wdndev/webnovel-chinese数据集解决了学术研究中对于大规模中文文本生成数据的需求。在模型训练中,该数据集有助于研究者克服因数据不足导致的模型性能瓶颈,提高模型的泛化能力和生成文本的质量。此外,它也为研究情感分析、主题建模等任务提供了有力支持,对推动相关领域的研究具有重要意义。
实际应用
在实际应用中,wdndev/webnovel-chinese数据集的应用范围广泛,包括但不限于在线内容生成、智能客服、游戏AI等领域。它为这些场景提供了高质量的中文文本,使得AI系统在处理中文对话和内容创作时更加得心应手,极大地提升了用户体验和服务效率。
数据集最近研究
最新研究方向
在自然语言处理领域,wdndev/webnovel-chinese数据集的构建与运用,为文本生成任务提供了宝贵的资源。近期研究集中于深度学习模型,尤其是大型语言模型的预训练和微调,以期在小说创作、故事续写等方面实现更自然、更具创造力的文本输出。该数据集的运用,不仅推动了语言模型在理解复杂文本结构、角色情感和故事逻辑方面的进步,也为文化产品的数字化创作与传播带来了新的视角。在此领域,数据集的研究正与人工智能在文化创意产业中的应用紧密结合,展现出深远的影响力和广阔的应用前景。
以上内容由遇见数据集搜集并总结生成


