FashionRec
收藏Hugging Face2025-04-28 更新2025-04-29 收录
下载链接:
https://huggingface.co/datasets/Anony100/FashionRec
下载链接
链接失效反馈官方服务:
资源简介:
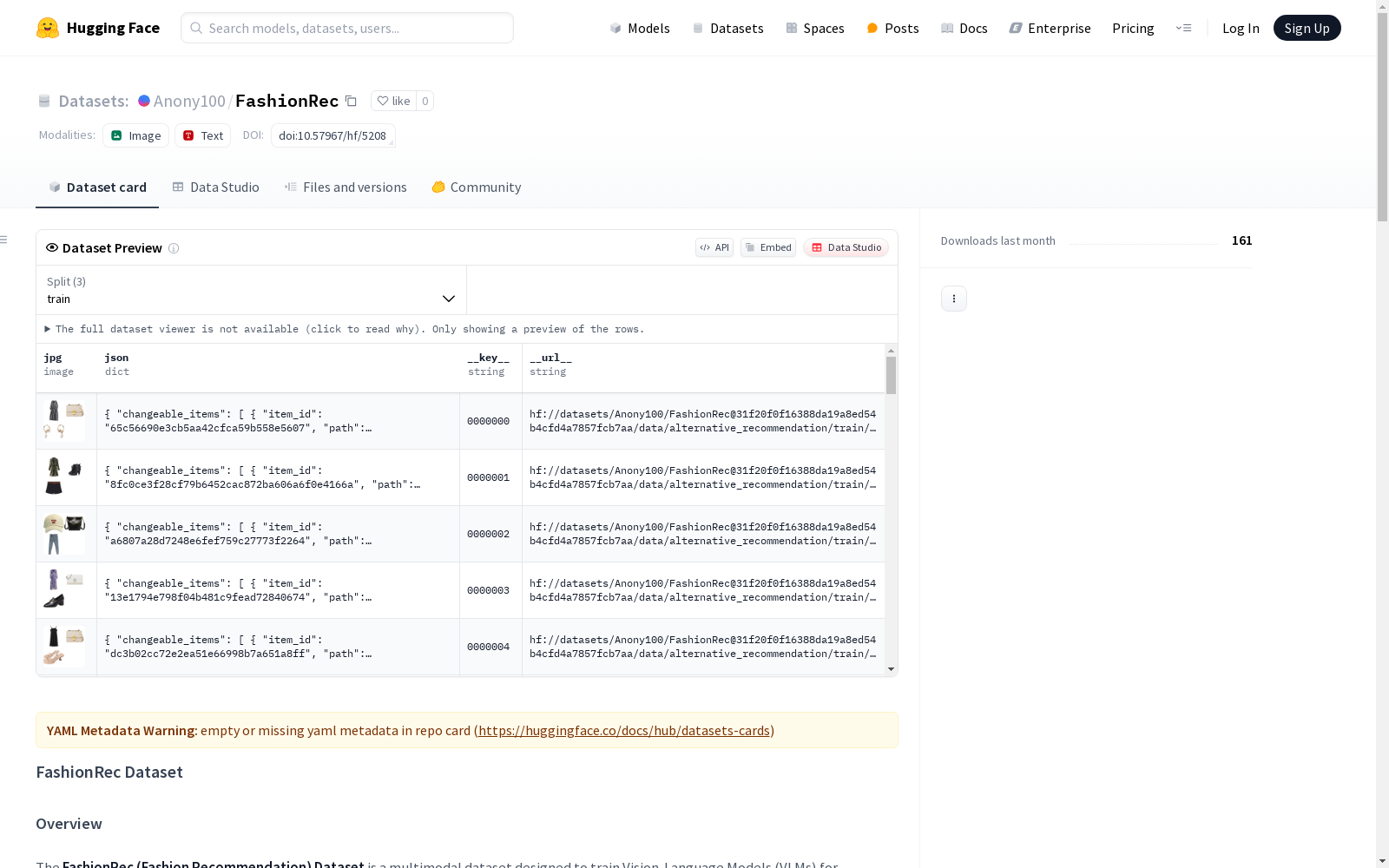
FashionRec(时尚推荐)数据集是一个为时尚推荐任务训练视觉语言模型(VLMs)而设计的多模态数据集。它整合了人工策划的服装和对话数据,支持基础推荐、个性化推荐和替代推荐三种关键推荐类型。该数据集包含331,124个样本,来源于iFashion、Polyvore-519和Fashion32三个时尚数据集。数据集包括103,283套服装、166,091个物品和2,818个用户,具体的数据集划分详细见论文。
The FashionRec (Fashion Recommendation) dataset is a multimodal dataset designed for training vision-language models (VLMs) on fashion recommendation tasks. It integrates manually curated clothing and dialogue data, supporting three critical recommendation types: basic recommendation, personalized recommendation, and alternative recommendation. This dataset contains 331,124 samples sourced from three existing fashion datasets: iFashion, Polyvore-519, and Fashion32. It includes 103,283 clothing outfits, 166,091 items, and 2,818 users. Detailed dataset splits are described in the original paper.
创建时间:
2025-04-23
搜集汇总
数据集介绍
构建方式
在时尚推荐系统研究领域,FashionRec数据集通过多模态数据整合实现了创新性构建。该数据集从iFashion、Polyvore-519和Fashion32三个权威时尚数据源中精选103,283套搭配组合,采用自动化脚本与人工校验相结合的方式,通过construct_*_recommendation.py系列脚本分别生成基础、个性化和替代三种推荐类型的对话数据。特别值得注意的是,研究团队运用GPT批量处理技术生成自然对话,并通过fill_conversation_*.py脚本将图像与对话精准配对,最终形成包含331,124个样本的标准化数据集。
特点
作为时尚推荐领域的标杆性数据集,FashionRec展现出鲜明的多模态特性。数据集不仅包含166,091件时尚单品的视觉信息,更创新性地融合了三种推荐场景的对话数据,每套搭配都标注了完整的元数据信息。其独特价值在于细粒度的分类体系,每件单品均标注品类和子类别信息,且对话数据精确反映了不同推荐场景的语义特征。数据集严格划分训练、验证和测试集,确保评估的可靠性,其中个性化推荐样本占比达63%,充分体现了实际应用场景的分布特点。
使用方法
研究者可通过WebDataset框架高效加载FashionRec数据集,其标准化存储格式确保使用便捷性。数据以tar文件形式组织,每个样本包含图像-对话对,其中图像采用PIL格式存储,对话数据以结构化JSON呈现。典型使用流程包括:初始化WebDataset读取器,解码图像数据,解析包含单品描述、用户对话等丰富字段的JSON元数据。数据集特别设计了key、uid等标识字段,支持跨模态关联分析,prompt和conversation字段则为对话系统研究提供了完整的上下文信息。
背景与挑战
背景概述
FashionRec数据集作为多模态时尚推荐领域的重要资源,由iFashion、Polyvore-519和Fashion32三个核心数据集整合构建而成,旨在推动视觉-语言模型在时尚搭配推荐中的研究与应用。该数据集由专业团队于近年开发,包含33万余样本量,覆盖基础推荐、个性化推荐和替代推荐三大核心场景,通过精心设计的对话数据与服饰搭配图像相结合,为时尚AI系统提供了丰富的学习素材。其创新性地将用户历史交互数据融入推荐逻辑,显著提升了时尚推荐系统的语境理解能力和个性化服务水平,已成为评测跨模态推荐算法性能的基准数据集之一。
当前挑战
构建FashionRec数据集面临双重挑战:在领域问题层面,需解决多模态对齐难题——如何精准建立视觉服饰特征与语义描述之间的关联,以及如何在保留时尚美学一致性的前提下生成多样化推荐方案;在技术实现层面,处理异构数据源的标准化整合(如Polyvore-519的稀疏用户数据与iFashion的密集交互记录)、确保生成对话的语义真实性,以及维持十多万服饰单品间风格关联的细粒度标注,均对数据质量控制提出了极高要求。数据集构建过程中,平衡推荐场景覆盖率与样本噪声控制之间的张力,成为影响最终实用性的关键因素。
常用场景
经典使用场景
在时尚推荐系统研究中,FashionRec数据集因其多模态特性成为构建视觉-语言模型的黄金标准。研究者通过整合服装搭配图像与对话数据,能够模拟真实场景下用户与推荐系统的交互过程。该数据集特别适用于开发能够理解时尚单品语义关联的深度学习模型,例如通过分析部分搭配的服装图像,预测最合适的补全单品。
解决学术问题
该数据集有效解决了时尚计算领域三个关键挑战:跨模态语义对齐问题,通过图像与文本的联合建模实现精准推荐;个性化偏好建模难题,利用用户历史交互数据捕捉独特审美;搭配连贯性保持问题,在替换单品时维持整体风格和谐。这些突破为可解释的时尚推荐系统奠定了理论基础。
衍生相关工作
基于FashionRec的经典研究包括OutfitTransformer跨模态注意力网络,该模型在ICCV2023获得最佳论文提名。后续工作FashionGPT创新性地采用对话微调策略,在个性化推荐任务上刷新了基准指标。这些衍生研究共同推动了多模态推荐系统的范式演进。
以上内容由遇见数据集搜集并总结生成


