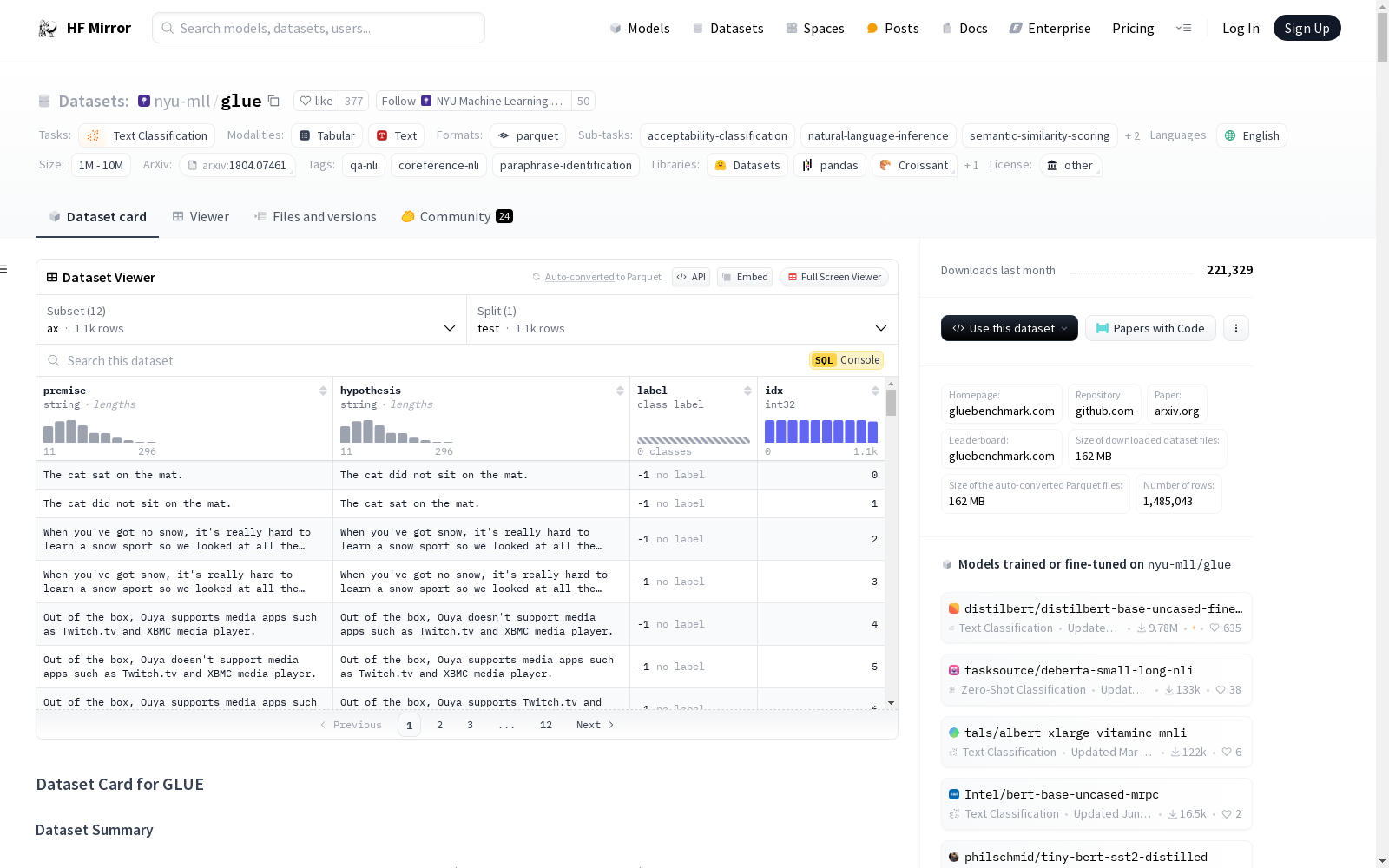
nyu-mll/glue
收藏Hugging Face2024-01-30 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/nyu-mll/glue
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- other
language_creators:
- other
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- acceptability-classification
- natural-language-inference
- semantic-similarity-scoring
- sentiment-classification
- text-scoring
paperswithcode_id: glue
pretty_name: GLUE (General Language Understanding Evaluation benchmark)
config_names:
- ax
- cola
- mnli
- mnli_matched
- mnli_mismatched
- mrpc
- qnli
- qqp
- rte
- sst2
- stsb
- wnli
tags:
- qa-nli
- coreference-nli
- paraphrase-identification
dataset_info:
- config_name: ax
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
'0': entailment
'1': neutral
'2': contradiction
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 237694
num_examples: 1104
download_size: 80767
dataset_size: 237694
- config_name: cola
features:
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
'0': unacceptable
'1': acceptable
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 484869
num_examples: 8551
- name: validation
num_bytes: 60322
num_examples: 1043
- name: test
num_bytes: 60513
num_examples: 1063
download_size: 326394
dataset_size: 605704
- config_name: mnli
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
'0': entailment
'1': neutral
'2': contradiction
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 74619646
num_examples: 392702
- name: validation_matched
num_bytes: 1833783
num_examples: 9815
- name: validation_mismatched
num_bytes: 1949231
num_examples: 9832
- name: test_matched
num_bytes: 1848654
num_examples: 9796
- name: test_mismatched
num_bytes: 1950703
num_examples: 9847
download_size: 57168425
dataset_size: 82202017
- config_name: mnli_matched
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
'0': entailment
'1': neutral
'2': contradiction
- name: idx
dtype: int32
splits:
- name: validation
num_bytes: 1833783
num_examples: 9815
- name: test
num_bytes: 1848654
num_examples: 9796
download_size: 2435055
dataset_size: 3682437
- config_name: mnli_mismatched
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
'0': entailment
'1': neutral
'2': contradiction
- name: idx
dtype: int32
splits:
- name: validation
num_bytes: 1949231
num_examples: 9832
- name: test
num_bytes: 1950703
num_examples: 9847
download_size: 2509009
dataset_size: 3899934
- config_name: mrpc
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': not_equivalent
'1': equivalent
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 943843
num_examples: 3668
- name: validation
num_bytes: 105879
num_examples: 408
- name: test
num_bytes: 442410
num_examples: 1725
download_size: 1033400
dataset_size: 1492132
- config_name: qnli
features:
- name: question
dtype: string
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
'0': entailment
'1': not_entailment
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 25612443
num_examples: 104743
- name: validation
num_bytes: 1368304
num_examples: 5463
- name: test
num_bytes: 1373093
num_examples: 5463
download_size: 19278324
dataset_size: 28353840
- config_name: qqp
features:
- name: question1
dtype: string
- name: question2
dtype: string
- name: label
dtype:
class_label:
names:
'0': not_duplicate
'1': duplicate
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 50900820
num_examples: 363846
- name: validation
num_bytes: 5653754
num_examples: 40430
- name: test
num_bytes: 55171111
num_examples: 390965
download_size: 73982265
dataset_size: 111725685
- config_name: rte
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': entailment
'1': not_entailment
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 847320
num_examples: 2490
- name: validation
num_bytes: 90728
num_examples: 277
- name: test
num_bytes: 974053
num_examples: 3000
download_size: 1274409
dataset_size: 1912101
- config_name: sst2
features:
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative
'1': positive
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 4681603
num_examples: 67349
- name: validation
num_bytes: 106252
num_examples: 872
- name: test
num_bytes: 216640
num_examples: 1821
download_size: 3331080
dataset_size: 5004495
- config_name: stsb
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: float32
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 754791
num_examples: 5749
- name: validation
num_bytes: 216064
num_examples: 1500
- name: test
num_bytes: 169974
num_examples: 1379
download_size: 766983
dataset_size: 1140829
- config_name: wnli
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': not_entailment
'1': entailment
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 107109
num_examples: 635
- name: validation
num_bytes: 12162
num_examples: 71
- name: test
num_bytes: 37889
num_examples: 146
download_size: 63522
dataset_size: 157160
configs:
- config_name: ax
data_files:
- split: test
path: ax/test-*
- config_name: cola
data_files:
- split: train
path: cola/train-*
- split: validation
path: cola/validation-*
- split: test
path: cola/test-*
- config_name: mnli
data_files:
- split: train
path: mnli/train-*
- split: validation_matched
path: mnli/validation_matched-*
- split: validation_mismatched
path: mnli/validation_mismatched-*
- split: test_matched
path: mnli/test_matched-*
- split: test_mismatched
path: mnli/test_mismatched-*
- config_name: mnli_matched
data_files:
- split: validation
path: mnli_matched/validation-*
- split: test
path: mnli_matched/test-*
- config_name: mnli_mismatched
data_files:
- split: validation
path: mnli_mismatched/validation-*
- split: test
path: mnli_mismatched/test-*
- config_name: mrpc
data_files:
- split: train
path: mrpc/train-*
- split: validation
path: mrpc/validation-*
- split: test
path: mrpc/test-*
- config_name: qnli
data_files:
- split: train
path: qnli/train-*
- split: validation
path: qnli/validation-*
- split: test
path: qnli/test-*
- config_name: qqp
data_files:
- split: train
path: qqp/train-*
- split: validation
path: qqp/validation-*
- split: test
path: qqp/test-*
- config_name: rte
data_files:
- split: train
path: rte/train-*
- split: validation
path: rte/validation-*
- split: test
path: rte/test-*
- config_name: sst2
data_files:
- split: train
path: sst2/train-*
- split: validation
path: sst2/validation-*
- split: test
path: sst2/test-*
- config_name: stsb
data_files:
- split: train
path: stsb/train-*
- split: validation
path: stsb/validation-*
- split: test
path: stsb/test-*
- config_name: wnli
data_files:
- split: train
path: wnli/train-*
- split: validation
path: wnli/validation-*
- split: test
path: wnli/test-*
train-eval-index:
- config: cola
task: text-classification
task_id: binary_classification
splits:
train_split: train
eval_split: validation
col_mapping:
sentence: text
label: target
- config: sst2
task: text-classification
task_id: binary_classification
splits:
train_split: train
eval_split: validation
col_mapping:
sentence: text
label: target
- config: mrpc
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
sentence1: text1
sentence2: text2
label: target
- config: qqp
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
question1: text1
question2: text2
label: target
- config: stsb
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
sentence1: text1
sentence2: text2
label: target
- config: mnli
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation_matched
col_mapping:
premise: text1
hypothesis: text2
label: target
- config: mnli_mismatched
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
premise: text1
hypothesis: text2
label: target
- config: mnli_matched
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
premise: text1
hypothesis: text2
label: target
- config: qnli
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
question: text1
sentence: text2
label: target
- config: rte
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
sentence1: text1
sentence2: text2
label: target
- config: wnli
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
sentence1: text1
sentence2: text2
label: target
---
# Dataset Card for GLUE
## Table of Contents
- [Dataset Card for GLUE](#dataset-card-for-glue)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [ax](#ax)
- [cola](#cola)
- [mnli](#mnli)
- [mnli_matched](#mnli_matched)
- [mnli_mismatched](#mnli_mismatched)
- [mrpc](#mrpc)
- [qnli](#qnli)
- [qqp](#qqp)
- [rte](#rte)
- [sst2](#sst2)
- [stsb](#stsb)
- [wnli](#wnli)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [ax](#ax-1)
- [cola](#cola-1)
- [mnli](#mnli-1)
- [mnli_matched](#mnli_matched-1)
- [mnli_mismatched](#mnli_mismatched-1)
- [mrpc](#mrpc-1)
- [qnli](#qnli-1)
- [qqp](#qqp-1)
- [rte](#rte-1)
- [sst2](#sst2-1)
- [stsb](#stsb-1)
- [wnli](#wnli-1)
- [Data Fields](#data-fields)
- [ax](#ax-2)
- [cola](#cola-2)
- [mnli](#mnli-2)
- [mnli_matched](#mnli_matched-2)
- [mnli_mismatched](#mnli_mismatched-2)
- [mrpc](#mrpc-2)
- [qnli](#qnli-2)
- [qqp](#qqp-2)
- [rte](#rte-2)
- [sst2](#sst2-2)
- [stsb](#stsb-2)
- [wnli](#wnli-2)
- [Data Splits](#data-splits)
- [ax](#ax-3)
- [cola](#cola-3)
- [mnli](#mnli-3)
- [mnli_matched](#mnli_matched-3)
- [mnli_mismatched](#mnli_mismatched-3)
- [mrpc](#mrpc-3)
- [qnli](#qnli-3)
- [qqp](#qqp-3)
- [rte](#rte-3)
- [sst2](#sst2-3)
- [stsb](#stsb-3)
- [wnli](#wnli-3)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://gluebenchmark.com/
- **Repository:** https://github.com/nyu-mll/GLUE-baselines
- **Paper:** https://arxiv.org/abs/1804.07461
- **Leaderboard:** https://gluebenchmark.com/leaderboard
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 1.00 GB
- **Size of the generated dataset:** 240.84 MB
- **Total amount of disk used:** 1.24 GB
### Dataset Summary
GLUE, the General Language Understanding Evaluation benchmark (https://gluebenchmark.com/) is a collection of resources for training, evaluating, and analyzing natural language understanding systems.
### Supported Tasks and Leaderboards
The leaderboard for the GLUE benchmark can be found [at this address](https://gluebenchmark.com/). It comprises the following tasks:
#### ax
A manually-curated evaluation dataset for fine-grained analysis of system performance on a broad range of linguistic phenomena. This dataset evaluates sentence understanding through Natural Language Inference (NLI) problems. Use a model trained on MulitNLI to produce predictions for this dataset.
#### cola
The Corpus of Linguistic Acceptability consists of English acceptability judgments drawn from books and journal articles on linguistic theory. Each example is a sequence of words annotated with whether it is a grammatical English sentence.
#### mnli
The Multi-Genre Natural Language Inference Corpus is a crowdsourced collection of sentence pairs with textual entailment annotations. Given a premise sentence and a hypothesis sentence, the task is to predict whether the premise entails the hypothesis (entailment), contradicts the hypothesis (contradiction), or neither (neutral). The premise sentences are gathered from ten different sources, including transcribed speech, fiction, and government reports. The authors of the benchmark use the standard test set, for which they obtained private labels from the RTE authors, and evaluate on both the matched (in-domain) and mismatched (cross-domain) section. They also uses and recommend the SNLI corpus as 550k examples of auxiliary training data.
#### mnli_matched
The matched validation and test splits from MNLI. See the "mnli" BuilderConfig for additional information.
#### mnli_mismatched
The mismatched validation and test splits from MNLI. See the "mnli" BuilderConfig for additional information.
#### mrpc
The Microsoft Research Paraphrase Corpus (Dolan & Brockett, 2005) is a corpus of sentence pairs automatically extracted from online news sources, with human annotations for whether the sentences in the pair are semantically equivalent.
#### qnli
The Stanford Question Answering Dataset is a question-answering dataset consisting of question-paragraph pairs, where one of the sentences in the paragraph (drawn from Wikipedia) contains the answer to the corresponding question (written by an annotator). The authors of the benchmark convert the task into sentence pair classification by forming a pair between each question and each sentence in the corresponding context, and filtering out pairs with low lexical overlap between the question and the context sentence. The task is to determine whether the context sentence contains the answer to the question. This modified version of the original task removes the requirement that the model select the exact answer, but also removes the simplifying assumptions that the answer is always present in the input and that lexical overlap is a reliable cue.
#### qqp
The Quora Question Pairs2 dataset is a collection of question pairs from the community question-answering website Quora. The task is to determine whether a pair of questions are semantically equivalent.
#### rte
The Recognizing Textual Entailment (RTE) datasets come from a series of annual textual entailment challenges. The authors of the benchmark combined the data from RTE1 (Dagan et al., 2006), RTE2 (Bar Haim et al., 2006), RTE3 (Giampiccolo et al., 2007), and RTE5 (Bentivogli et al., 2009). Examples are constructed based on news and Wikipedia text. The authors of the benchmark convert all datasets to a two-class split, where for three-class datasets they collapse neutral and contradiction into not entailment, for consistency.
#### sst2
The Stanford Sentiment Treebank consists of sentences from movie reviews and human annotations of their sentiment. The task is to predict the sentiment of a given sentence. It uses the two-way (positive/negative) class split, with only sentence-level labels.
#### stsb
The Semantic Textual Similarity Benchmark (Cer et al., 2017) is a collection of sentence pairs drawn from news headlines, video and image captions, and natural language inference data. Each pair is human-annotated with a similarity score from 1 to 5.
#### wnli
The Winograd Schema Challenge (Levesque et al., 2011) is a reading comprehension task in which a system must read a sentence with a pronoun and select the referent of that pronoun from a list of choices. The examples are manually constructed to foil simple statistical methods: Each one is contingent on contextual information provided by a single word or phrase in the sentence. To convert the problem into sentence pair classification, the authors of the benchmark construct sentence pairs by replacing the ambiguous pronoun with each possible referent. The task is to predict if the sentence with the pronoun substituted is entailed by the original sentence. They use a small evaluation set consisting of new examples derived from fiction books that was shared privately by the authors of the original corpus. While the included training set is balanced between two classes, the test set is imbalanced between them (65% not entailment). Also, due to a data quirk, the development set is adversarial: hypotheses are sometimes shared between training and development examples, so if a model memorizes the training examples, they will predict the wrong label on corresponding development set example. As with QNLI, each example is evaluated separately, so there is not a systematic correspondence between a model's score on this task and its score on the unconverted original task. The authors of the benchmark call converted dataset WNLI (Winograd NLI).
### Languages
The language data in GLUE is in English (BCP-47 `en`)
## Dataset Structure
### Data Instances
#### ax
- **Size of downloaded dataset files:** 0.22 MB
- **Size of the generated dataset:** 0.24 MB
- **Total amount of disk used:** 0.46 MB
An example of 'test' looks as follows.
```
{
"premise": "The cat sat on the mat.",
"hypothesis": "The cat did not sit on the mat.",
"label": -1,
"idx: 0
}
```
#### cola
- **Size of downloaded dataset files:** 0.38 MB
- **Size of the generated dataset:** 0.61 MB
- **Total amount of disk used:** 0.99 MB
An example of 'train' looks as follows.
```
{
"sentence": "Our friends won't buy this analysis, let alone the next one we propose.",
"label": 1,
"id": 0
}
```
#### mnli
- **Size of downloaded dataset files:** 312.78 MB
- **Size of the generated dataset:** 82.47 MB
- **Total amount of disk used:** 395.26 MB
An example of 'train' looks as follows.
```
{
"premise": "Conceptually cream skimming has two basic dimensions - product and geography.",
"hypothesis": "Product and geography are what make cream skimming work.",
"label": 1,
"idx": 0
}
```
#### mnli_matched
- **Size of downloaded dataset files:** 312.78 MB
- **Size of the generated dataset:** 3.69 MB
- **Total amount of disk used:** 316.48 MB
An example of 'test' looks as follows.
```
{
"premise": "Hierbas, ans seco, ans dulce, and frigola are just a few names worth keeping a look-out for.",
"hypothesis": "Hierbas is a name worth looking out for.",
"label": -1,
"idx": 0
}
```
#### mnli_mismatched
- **Size of downloaded dataset files:** 312.78 MB
- **Size of the generated dataset:** 3.91 MB
- **Total amount of disk used:** 316.69 MB
An example of 'test' looks as follows.
```
{
"premise": "What have you decided, what are you going to do?",
"hypothesis": "So what's your decision?",
"label": -1,
"idx": 0
}
```
#### mrpc
- **Size of downloaded dataset files:** ??
- **Size of the generated dataset:** 1.5 MB
- **Total amount of disk used:** ??
An example of 'train' looks as follows.
```
{
"sentence1": "Amrozi accused his brother, whom he called "the witness", of deliberately distorting his evidence.",
"sentence2": "Referring to him as only "the witness", Amrozi accused his brother of deliberately distorting his evidence.",
"label": 1,
"idx": 0
}
```
#### qnli
- **Size of downloaded dataset files:** ??
- **Size of the generated dataset:** 28 MB
- **Total amount of disk used:** ??
An example of 'train' looks as follows.
```
{
"question": "When did the third Digimon series begin?",
"sentence": "Unlike the two seasons before it and most of the seasons that followed, Digimon Tamers takes a darker and more realistic approach to its story featuring Digimon who do not reincarnate after their deaths and more complex character development in the original Japanese.",
"label": 1,
"idx": 0
}
```
#### qqp
- **Size of downloaded dataset files:** ??
- **Size of the generated dataset:** 107 MB
- **Total amount of disk used:** ??
An example of 'train' looks as follows.
```
{
"question1": "How is the life of a math student? Could you describe your own experiences?",
"question2": "Which level of prepration is enough for the exam jlpt5?",
"label": 0,
"idx": 0
}
```
#### rte
- **Size of downloaded dataset files:** ??
- **Size of the generated dataset:** 1.9 MB
- **Total amount of disk used:** ??
An example of 'train' looks as follows.
```
{
"sentence1": "No Weapons of Mass Destruction Found in Iraq Yet.",
"sentence2": "Weapons of Mass Destruction Found in Iraq.",
"label": 1,
"idx": 0
}
```
#### sst2
- **Size of downloaded dataset files:** ??
- **Size of the generated dataset:** 4.9 MB
- **Total amount of disk used:** ??
An example of 'train' looks as follows.
```
{
"sentence": "hide new secretions from the parental units",
"label": 0,
"idx": 0
}
```
#### stsb
- **Size of downloaded dataset files:** ??
- **Size of the generated dataset:** 1.2 MB
- **Total amount of disk used:** ??
An example of 'train' looks as follows.
```
{
"sentence1": "A plane is taking off.",
"sentence2": "An air plane is taking off.",
"label": 5.0,
"idx": 0
}
```
#### wnli
- **Size of downloaded dataset files:** ??
- **Size of the generated dataset:** 0.18 MB
- **Total amount of disk used:** ??
An example of 'train' looks as follows.
```
{
"sentence1": "I stuck a pin through a carrot. When I pulled the pin out, it had a hole.",
"sentence2": "The carrot had a hole.",
"label": 1,
"idx": 0
}
```
### Data Fields
The data fields are the same among all splits.
#### ax
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### cola
- `sentence`: a `string` feature.
- `label`: a classification label, with possible values including `unacceptable` (0), `acceptable` (1).
- `idx`: a `int32` feature.
#### mnli
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mnli_matched
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mnli_mismatched
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mrpc
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including `not_equivalent` (0), `equivalent` (1).
- `idx`: a `int32` feature.
#### qnli
- `question`: a `string` feature.
- `sentence`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `not_entailment` (1).
- `idx`: a `int32` feature.
#### qqp
- `question1`: a `string` feature.
- `question2`: a `string` feature.
- `label`: a classification label, with possible values including `not_duplicate` (0), `duplicate` (1).
- `idx`: a `int32` feature.
#### rte
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `not_entailment` (1).
- `idx`: a `int32` feature.
#### sst2
- `sentence`: a `string` feature.
- `label`: a classification label, with possible values including `negative` (0), `positive` (1).
- `idx`: a `int32` feature.
#### stsb
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a float32 regression label, with possible values from 0 to 5.
- `idx`: a `int32` feature.
#### wnli
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including `not_entailment` (0), `entailment` (1).
- `idx`: a `int32` feature.
### Data Splits
#### ax
| |test|
|---|---:|
|ax |1104|
#### cola
| |train|validation|test|
|----|----:|---------:|---:|
|cola| 8551| 1043|1063|
#### mnli
| |train |validation_matched|validation_mismatched|test_matched|test_mismatched|
|----|-----:|-----------------:|--------------------:|-----------:|--------------:|
|mnli|392702| 9815| 9832| 9796| 9847|
#### mnli_matched
| |validation|test|
|------------|---------:|---:|
|mnli_matched| 9815|9796|
#### mnli_mismatched
| |validation|test|
|---------------|---------:|---:|
|mnli_mismatched| 9832|9847|
#### mrpc
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qqp
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### rte
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### sst2
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### stsb
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### wnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
The primary GLUE tasks are built on and derived from existing datasets. We refer users to the original licenses accompanying each dataset.
### Citation Information
If you use GLUE, please cite all the datasets you use.
In addition, we encourage you to use the following BibTeX citation for GLUE itself:
```
@inproceedings{wang2019glue,
title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding},
author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.},
note={In the Proceedings of ICLR.},
year={2019}
}
```
If you evaluate using GLUE, we also highly recommend citing the papers that originally introduced the nine GLUE tasks, both to give the original authors their due credit and because venues will expect papers to describe the data they evaluate on.
The following provides BibTeX for all of the GLUE tasks, except QQP, for which we recommend adding a footnote to this page: https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs
```
@article{warstadt2018neural,
title={Neural Network Acceptability Judgments},
author={Warstadt, Alex and Singh, Amanpreet and Bowman, Samuel R.},
journal={arXiv preprint 1805.12471},
year={2018}
}
@inproceedings{socher2013recursive,
title={Recursive deep models for semantic compositionality over a sentiment treebank},
author={Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D and Ng, Andrew and Potts, Christopher},
booktitle={Proceedings of EMNLP},
pages={1631--1642},
year={2013}
}
@inproceedings{dolan2005automatically,
title={Automatically constructing a corpus of sentential paraphrases},
author={Dolan, William B and Brockett, Chris},
booktitle={Proceedings of the International Workshop on Paraphrasing},
year={2005}
}
@book{agirre2007semantic,
editor = {Agirre, Eneko and M`arquez, Llu'{i}s and Wicentowski, Richard},
title = {Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007)},
month = {June},
year = {2007},
address = {Prague, Czech Republic},
publisher = {Association for Computational Linguistics},
}
@inproceedings{williams2018broad,
author = {Williams, Adina and Nangia, Nikita and Bowman, Samuel R.},
title = {A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference},
booktitle = {Proceedings of NAACL-HLT},
year = 2018
}
@inproceedings{rajpurkar2016squad,
author = {Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy}
title = {{SQ}u{AD}: 100,000+ Questions for Machine Comprehension of Text},
booktitle = {Proceedings of EMNLP}
year = {2016},
publisher = {Association for Computational Linguistics},
pages = {2383--2392},
location = {Austin, Texas},
}
@incollection{dagan2006pascal,
title={The {PASCAL} recognising textual entailment challenge},
author={Dagan, Ido and Glickman, Oren and Magnini, Bernardo},
booktitle={Machine learning challenges. evaluating predictive uncertainty, visual object classification, and recognising tectual entailment},
pages={177--190},
year={2006},
publisher={Springer}
}
@article{bar2006second,
title={The second {PASCAL} recognising textual entailment challenge},
author={Bar Haim, Roy and Dagan, Ido and Dolan, Bill and Ferro, Lisa and Giampiccolo, Danilo and Magnini, Bernardo and Szpektor, Idan},
year={2006}
}
@inproceedings{giampiccolo2007third,
title={The third {PASCAL} recognizing textual entailment challenge},
author={Giampiccolo, Danilo and Magnini, Bernardo and Dagan, Ido and Dolan, Bill},
booktitle={Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing},
pages={1--9},
year={2007},
organization={Association for Computational Linguistics},
}
@article{bentivogli2009fifth,
title={The Fifth {PASCAL} Recognizing Textual Entailment Challenge},
author={Bentivogli, Luisa and Dagan, Ido and Dang, Hoa Trang and Giampiccolo, Danilo and Magnini, Bernardo},
booktitle={TAC},
year={2009}
}
@inproceedings{levesque2011winograd,
title={The {W}inograd schema challenge},
author={Levesque, Hector J and Davis, Ernest and Morgenstern, Leora},
booktitle={{AAAI} Spring Symposium: Logical Formalizations of Commonsense Reasoning},
volume={46},
pages={47},
year={2011}
}
```
### Contributions
Thanks to [@patpizio](https://github.com/patpizio), [@jeswan](https://github.com/jeswan), [@thomwolf](https://github.com/thomwolf), [@patrickvonplaten](https://github.com/patrickvonplaten), [@mariamabarham](https://github.com/mariamabarham) for adding this dataset.
提供机构:
nyu-mll
原始信息汇总
数据集概述
数据集基本信息
- 名称: GLUE (General Language Understanding Evaluation benchmark)
- 语言: 英语
- 许可证: 其他
- 多语言性: 单语
- 大小类别: 10K<n<100K
- 源数据集: 原始
- 任务类别: 文本分类
- 任务ID:
- acceptability-classification
- natural-language-inference
- semantic-similarity-scoring
- sentiment-classification
- text-scoring
- Paperswithcode ID: glue
- 配置名称:
- ax
- cola
- mnli
- mnli_matched
- mnli_mismatched
- mrpc
- qnli
- qqp
- rte
- sst2
- stsb
- wnli
数据集结构
数据实例
ax
- 特征:
- premise: 字符串
- hypothesis: 字符串
- label:
- 0: entailment
- 1: neutral
- 2: contradiction
- idx: int32
- 分割:
- test: 1104个样本, 237694字节
cola
- 特征:
- sentence: 字符串
- label:
- 0: unacceptable
- 1: acceptable
- idx: int32
- 分割:
- train: 8551个样本, 484869字节
- validation: 1043个样本, 60322字节
- test: 1063个样本, 60513字节
mnli
- 特征:
- premise: 字符串
- hypothesis: 字符串
- label:
- 0: entailment
- 1: neutral
- 2: contradiction
- idx: int32
- 分割:
- train: 392702个样本, 74619646字节
- validation_matched: 9815个样本, 1833783字节
- validation_mismatched: 9832个样本, 1949231字节
- test_matched: 9796个样本, 1848654字节
- test_mismatched: 9847个样本, 1950703字节
mnli_matched
- 特征:
- premise: 字符串
- hypothesis: 字符串
- label:
- 0: entailment
- 1: neutral
- 2: contradiction
- idx: int32
- 分割:
- validation: 9815个样本, 1833783字节
- test: 9796个样本, 1848654字节
mnli_mismatched
- 特征:
- premise: 字符串
- hypothesis: 字符串
- label:
- 0: entailment
- 1: neutral
- 2: contradiction
- idx: int32
- 分割:
- validation: 9832个样本, 1949231字节
- test: 9847个样本, 1950703字节
mrpc
- 特征:
- sentence1: 字符串
- sentence2: 字符串
- label:
- 0: not_equivalent
- 1: equivalent
- idx: int32
- 分割:
- train: 3668个样本, 943843字节
- validation: 408个样本, 105879字节
- test: 1725个样本, 442410字节
qnli
- 特征:
- question: 字符串
- sentence: 字符串
- label:
- 0: entailment
- 1: not_entailment
- idx: int32
- 分割:
- train: 104743个样本, 25612443字节
- validation: 5463个样本, 1368304字节
- test: 5463个样本, 1373093字节
qqp
- 特征:
- question1: 字符串
- question2: 字符串
- label:
- 0: not_duplicate
- 1: duplicate
- idx: int32
- 分割:
- train: 363846个样本, 50900820字节
- validation: 40430个样本, 5653754字节
- test: 390965个样本, 55171111字节
rte
- 特征:
- sentence1: 字符串
- sentence2: 字符串
- label:
- 0: entailment
- 1: not_entailment
- idx: int32
- 分割:
- train: 2490个样本, 847320字节
- validation: 277个样本, 90728字节
- test: 3000个样本, 974053字节
sst2
- 特征:
- sentence: 字符串
- label:
- 0: negative
- 1: positive
- idx: int32
- 分割:
- train: 67349个样本, 4681603字节
- validation: 872个样本, 106252字节
- test: 1821个样本, 216640字节
stsb
- 特征:
- sentence1: 字符串
- sentence2: 字符串
- label: float32
- idx: int32
- 分割:
- train: 5749个样本, 754791字节
- validation: 1500个样本, 216064字节
- test: 1379个样本, 169974字节
wnli
- 特征:
- sentence1: 字符串
- sentence2: 字符串
- label:
- 0: not_entailment
- 1: entailment
- idx: int32
- 分割:
- train: 635个样本, 107109字节
- validation: 71个样本, 12162字节
- test: 146个样本, 37889字节
搜集汇总
数据集介绍
构建方式
GLUE数据集的构建基于多种自然语言理解任务,涵盖了文本分类、自然语言推理、语义相似度评分等多个领域。每个子数据集均经过精心设计,以确保其能够有效评估模型在特定任务上的表现。例如,MNLI数据集通过收集来自不同领域的句子对,并标注其蕴含关系,从而构建了一个大规模的自然语言推理基准。此外,数据集的划分包括训练集、验证集和测试集,以支持模型的训练、调优和评估。
特点
GLUE数据集的一个显著特点是其多样性和综合性。它包含了多个子数据集,每个子数据集针对不同的自然语言理解任务,如情感分析、语义相似度评估和文本蕴含判断。这种多样性使得GLUE成为一个全面的基准,能够评估模型在广泛任务上的性能。此外,数据集的规模适中,介于10K到100K样本之间,确保了数据量既足够用于训练复杂模型,又不至于过大而难以处理。
使用方法
使用GLUE数据集时,用户可以根据具体任务选择相应的子数据集进行模型训练和评估。例如,对于情感分析任务,可以选择SST-2数据集;对于自然语言推理任务,可以选择MNLI数据集。每个子数据集都提供了详细的特征描述和数据字段,用户可以根据这些信息进行数据预处理和模型输入的准备。此外,GLUE还提供了统一的评估指标和基准测试方法,方便用户在不同任务间进行性能比较和模型优化。
背景与挑战
背景概述
GLUE(General Language Understanding Evaluation benchmark)是由纽约大学(NYU)和其合作机构于2018年创建的一个综合性的自然语言理解评估基准。该数据集由多个子任务组成,涵盖了文本分类、自然语言推理、语义相似度评分、情感分类等多个领域。GLUE的核心研究问题是如何全面评估和提升自然语言处理模型的理解能力,其影响力在于为研究人员提供了一个统一的评估平台,促进了模型在多任务环境下的性能提升。
当前挑战
GLUE数据集在构建过程中面临多个挑战。首先,数据集需要涵盖多种语言理解任务,这要求数据来源的多样性和高质量的标注。其次,不同任务之间的数据分布和难度差异较大,如何确保模型在所有任务上都能表现良好是一个难题。此外,GLUE的评估标准需要公正且具有代表性,以避免模型在特定任务上的过拟合。最后,数据集的更新和维护也是一个持续的挑战,以确保其与最新的研究进展保持同步。
常用场景
经典使用场景
GLUE数据集的经典使用场景主要集中在自然语言理解系统的评估与优化。通过包含多种任务,如文本分类、自然语言推理、语义相似度评分等,GLUE为研究人员提供了一个全面的基准,用于测试和比较不同模型的性能。例如,MNLI任务用于评估模型在不同文本来源中的推理能力,而SST-2任务则专注于情感分析,评估模型对文本情感的识别能力。
解决学术问题
GLUE数据集解决了自然语言处理领域中多个关键的学术研究问题。首先,它提供了一个统一的评估框架,使得不同模型在多种任务上的表现可以进行直接比较,从而推动了模型性能的提升。其次,GLUE通过包含多种语言现象和任务类型,帮助研究人员识别和解决模型在特定任务上的不足,促进了自然语言理解技术的全面发展。
衍生相关工作
GLUE数据集的发布催生了大量相关研究工作,包括但不限于模型优化、多任务学习、以及跨任务迁移学习等。例如,BERT模型的提出和优化很大程度上受益于GLUE的评估框架,而后续的RoBERTa、ALBERT等模型也都是在GLUE的基准上进行性能验证和改进。此外,GLUE还激发了其他类似的多任务评估基准的开发,如SuperGLUE,进一步推动了自然语言处理领域的发展。
以上内容由遇见数据集搜集并总结生成


