Bekbolat/gun-detection-paligemma_29samples
收藏Hugging Face2024-06-19 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/Bekbolat/gun-detection-paligemma_29samples
下载链接
链接失效反馈官方服务:
资源简介:
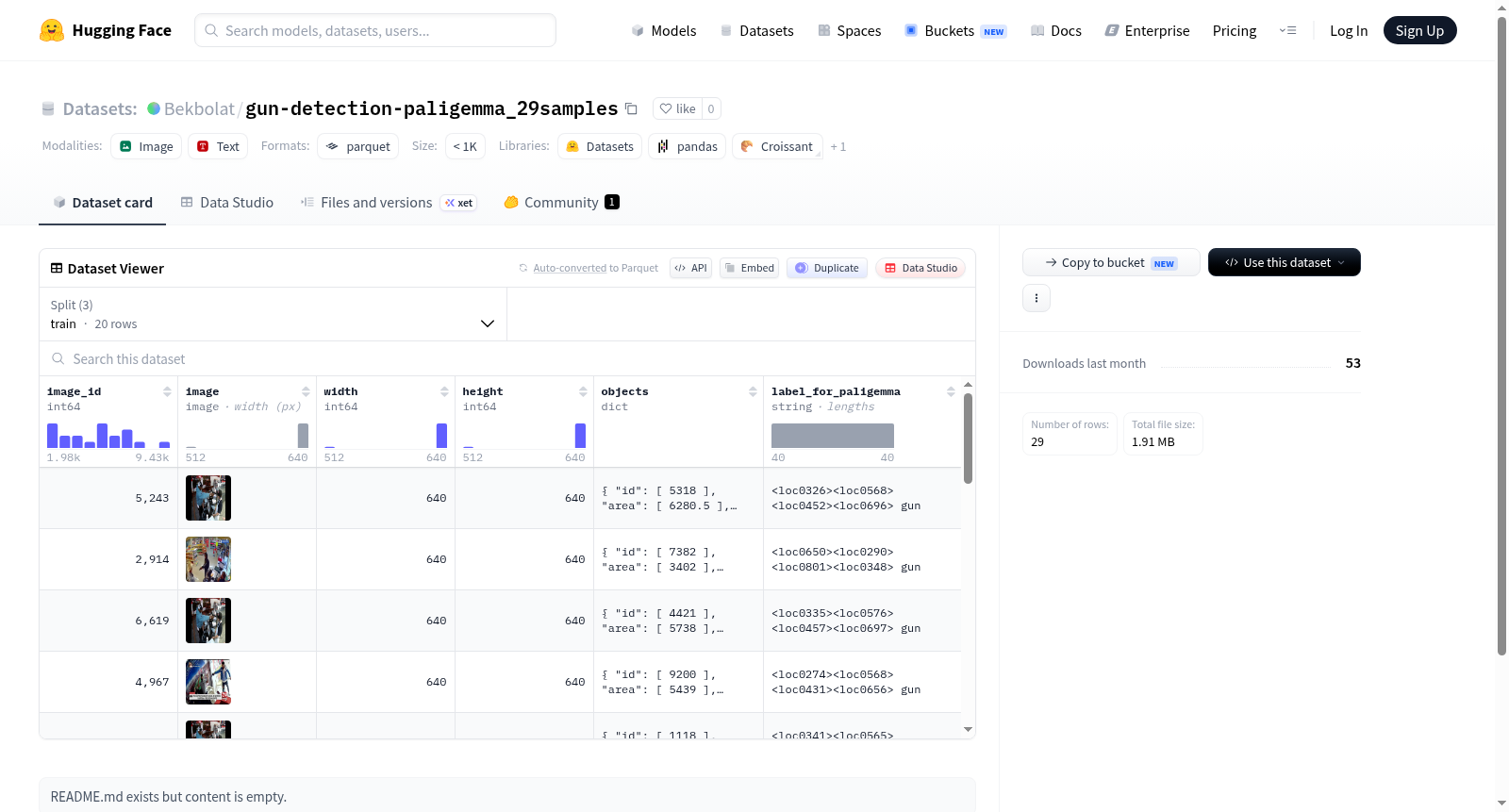
该数据集包含图像数据及其相关元数据,特征包括图像ID、图像本身、图像的宽度和高度、对象信息(包括对象的ID、面积、边界框和类别),以及用于Paligemma模型的标签。数据集分为训练集、验证集和测试集,分别包含20、4和5个样本。数据集的下载大小为1905302字节,总大小为1888013字节。
This dataset contains image data and related metadata. The features include image ID, the image itself, image width and height, object information (including object ID, area, bounding box, and category), and labels for the Paligemma model. The dataset is divided into training, validation, and test sets, containing 20, 4, and 5 samples respectively. The download size of the dataset is 1905302 bytes, and the total size is 1888013 bytes.
提供机构:
Bekbolat
原始信息汇总
数据集概述
数据集特征
- image_id: 图像ID,数据类型为
int64。 - image: 图像数据,数据类型为
image。 - width: 图像宽度,数据类型为
int64。 - height: 图像高度,数据类型为
int64。 - objects: 对象信息,包含以下子特征:
- id: 对象ID,数据类型为
int64列表。 - area: 对象面积,数据类型为
float32列表。 - bbox: 对象边界框,数据类型为
float32列表的列表。 - category: 对象类别,数据类型为
int64列表。
- id: 对象ID,数据类型为
- label_for_paligemma: 标签,数据类型为
string。
数据集划分
- train: 训练集,包含20个样本,大小为1290347.0字节。
- validation: 验证集,包含4个样本,大小为247932.0字节。
- test: 测试集,包含5个样本,大小为349734.0字节。
数据集大小
- 下载大小: 1905302字节。
- 数据集大小: 1888013.0字节。
配置信息
- config_name:
default- data_files:
- train: 路径为
data/train-*。 - validation: 路径为
data/validation-*。 - test: 路径为
data/test-*。
- train: 路径为
- data_files:
搜集汇总
数据集介绍
构建方式
在公共安全与智能监控领域,目标检测数据集是模型训练的基础。Bekbolat/gun-detection-paligemma_29samples数据集专为枪支检测任务而构建,其规模虽小但结构严谨。该数据集共包含29个样本,被划分为训练集(20例)、验证集(4例)和测试集(5例),以支持模型的训练与评估。每张图像均标注了丰富的元信息,包括图像标识符、尺寸以及对象级注释,如边界框坐标、面积和目标类别,并特别设计了适用于PaliGemma模型的标签字段,便于直接用于多模态指令微调。数据以标准格式存储,通过HuggingFace Datasets库可便捷加载。
特点
该数据集的核心特点在于其高度针对性与简洁性。它聚焦于单一类别——枪支的检测,样本数量虽少,但注释详尽,包含每个目标的唯一ID、面积及归一化的边界框,为小样本学习或模型原型验证提供了理想资源。尤为突出的是,数据集中预置了为PaliGemma模型定制的文本标签,使得该数据集能够无缝对接多模态大语言模型的微调流程,降低了数据预处理的门槛。这种设计兼顾了专业性与易用性,适合快速迭代与概念验证场景。
使用方法
使用该数据集时,推荐通过HuggingFace Datasets库加载,指定配置名称'default'并选择对应拆分(train、validation或test)即可获取图像与注释。加载后的数据可直接用于训练目标检测模型或微调PaliGemma多模态模型。对于目标检测任务,可利用'objects'字段中的边界框和类别信息构建损失函数;若用于多模态学习,则'label_for_paligemma'字段提供了现成的文本监督信号。数据集体积小巧,便于在资源受限的环境中进行实验,是快速测试检测算法或验证多模态框架兼容性的高效工具。
背景与挑战
背景概述
在公共安全与智能监控领域,枪械检测作为一项关键任务,旨在从图像或视频流中快速、准确地识别出枪支的存在,以预防暴力事件并辅助执法决策。Bekbolat/gun-detection-paligemma_29samples数据集由研究者Bekbolat等人创建,聚焦于利用PaliGemma模型进行少样本枪械检测。该数据集于近期发布,包含29个经过精细标注的样本,划分为训练集(20例)、验证集(4例)和测试集(5例),每个样本均提供图像、边界框、类别及专为PaliGemma设计的文本标签。其核心研究问题在于探索如何在数据极度稀缺的场景下,借助多模态大语言模型实现高效的枪械目标检测,为资源受限环境下的安全监控系统提供新的解决思路。该数据集虽规模微小,却对推动少样本学习与多模态融合在安防领域的应用具有示范意义。
当前挑战
该数据集面临的核心挑战源于其极小的样本量(仅29例),这直接制约了模型的泛化能力与鲁棒性。首先,在领域问题层面,枪械检测任务本身对误报和漏报容忍度极低,而少样本条件使得模型难以学习到枪支在不同光照、角度、遮挡及背景下的多样视觉特征,易导致过拟合或识别失败。其次,构建过程中,数据标注需兼顾边界框的精确性与PaliGemma文本标签的语义一致性,而样本数量稀少意味着任何标注误差都会对模型训练产生不成比例的负面影响。此外,数据集的规模限制了其作为基准的可重复性评估,难以全面衡量不同少样本学习策略的优劣,且缺乏对复杂现实场景(如拥挤人群或低分辨率图像)的覆盖,进一步增加了实际部署的难度。
常用场景
经典使用场景
在计算机视觉与公共安全交叉领域,Bekbolat/gun-detection-paligemma_29samples数据集为细粒度目标检测任务提供了精炼的标注样本。其经典使用场景聚焦于训练轻量级模型以识别图像中的枪械目标,通过提供边界框、类别标签及适配PaliGemma架构的文本提示,研究者可高效构建从图像到结构化检测结果的端到端推理流程。该数据集虽样本量有限,却精准锚定了高危物品实时监控的核心需求,成为验证小样本学习策略与迁移学习范式的理想测试床。
衍生相关工作
该数据集催生了多项经典工作,包括面向小样本目标检测的元学习框架、基于视觉-语言提示的零样本枪械识别模型,以及结合注意力机制的轻量化检测网络。研究者还以其为基准,开发了针对PaliGemma架构的微调策略,通过对比不同文本提示模板对检测精度的影响,揭示了多模态对齐在敏感物品任务中的关键作用。这些工作共同推动了安全视觉领域从封闭集检测向开放世界理解的范式演进。
数据集最近研究
最新研究方向
在当前公共安全与智能监控技术迅猛发展的背景下,基于视觉的目标检测成为防范暴力事件的关键技术。Bekbolat/gun-detection-paligemma_29samples数据集聚焦于枪械这一高危物体的检测,其设计紧密结合了PaliGemma多模态模型的微调需求,为小样本学习与边缘场景下的实时预警提供了高质量训练资源。该数据集包含29个标注样本,划分了训练、验证与测试集,并提供了适配PaliGemma的标签格式,推动了轻量化、高精度枪械检测模型在安防摄像头、无人机巡检等受限环境中的部署。这一方向不仅响应了全球对公共场所枪支管控的迫切需求,也为多模态大模型在特定安全任务上的高效迁移学习树立了典范,具有显著的社会价值与技术前瞻性。
以上内容由遇见数据集搜集并总结生成


