---
pretty_name: InpaintCOCO
language:
- en
size_categories:
- 1K<n<10K
task_categories:
- image-to-text
- text-to-image
- image-classification
task_ids:
- image-captioning
tags:
- coco
- image-captioning
- inpainting
- multimodel-understanding
dataset_info:
features:
- name: concept
dtype: string
- name: coco_caption
dtype: string
- name: coco_image
dtype: image
- name: inpaint_caption
dtype: string
- name: inpaint_image
dtype: image
- name: mask
dtype: image
- name: worker
dtype: string
- name: coco_details
struct:
- name: captions
sequence: string
- name: coco_url
dtype: string
- name: date_captured
dtype: string
- name: flickr_url
dtype: string
- name: height
dtype: int64
- name: id
dtype: int64
- name: image_license
dtype: string
- name: text_license
dtype: string
- name: width
dtype: int64
- name: inpaint_details
struct:
- name: duration
dtype: int64
- name: guidance_scale
dtype: float64
- name: num_inference_steps
dtype: int64
- name: prompt
dtype: string
- name: prompts_used
dtype: int64
- name: quality
dtype: string
- name: mask_details
struct:
- name: height_factor
dtype: int64
- name: prompt
dtype: string
- name: prompts_used
dtype: int64
- name: width_factor
dtype: int64
splits:
- name: test
num_bytes: 1062104623.5
num_examples: 1260
download_size: 1055968442
dataset_size: 1062104623.5
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
# InpaintCOCO - Fine-grained multimodal concept understanding (for color, size, and COCO objects)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
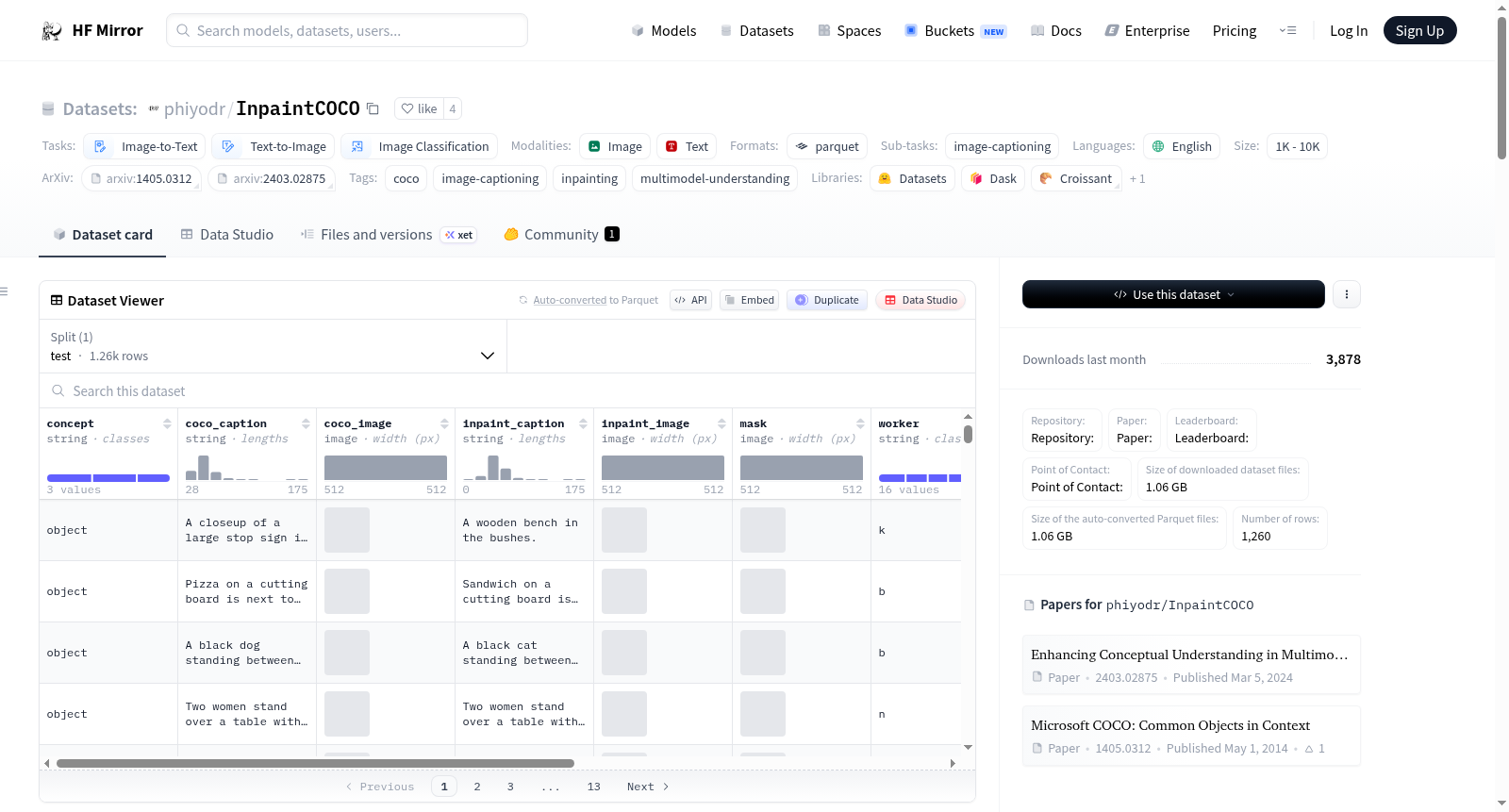
A data sample contains 2 images and 2 corresponding captions that differ only in one object, the color of an object, or the size of an object.
> Many multimodal tasks, such as Vision-Language Retrieval and Visual Question Answering, present results in terms of overall performance.
> Unfortunately, this approach overlooks more nuanced concepts, leaving us unaware of which specific concepts contribute to the success of current models and which are ignored.
> In response to this limitation, more recent benchmarks attempt to assess particular aspects of vision-language models.
> Some existing datasets focus on linguistic concepts utilizing one image paired with multiple captions; others adopt a visual or cross-modal perspective.
> In this study, we are particularly interested in fine-grained visual concept understanding, which we believe is not covered in existing benchmarks in sufficient isolation.
> Therefore, we create the InpaintCOCO dataset which consists of image pairs with minimum differences that lead to changes in the captions.
Download the dataset:
```python
from datasets import load_dataset
dataset = load_dataset("phiyodr/inpaintCOCO")
```
### Supported Tasks and Leaderboards
InpaintCOCO is a benchmark to understand fine-grained concepts in multimodal models (vision-language) similar to [Winoground](https://huggingface.co/datasets/facebook/winoground).
To our knowledge InpaintCOCO is the first benchmark, which consists of image pairs with minimum differences, so that the *visual* representation can be analyzed in a more standardized setting.
### Languages
All texts are in English.
## Dataset Structure
```python
DatasetDict({
test: Dataset({
features: ['concept', 'coco_caption', 'coco_image',
'inpaint_caption', 'inpaint_image',
'mask', 'worker', 'coco_details', 'inpaint_details', 'mask_details'],
num_rows: 1260
})
})
```
### Data Instances
An example looks as follows:
```python
{'concept': 'object',
'coco_caption': 'A closeup of a large stop sign in the bushes.',
'coco_image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=512x512>,
'inpaint_caption': 'A wooden bench in the bushes.',
'inpaint_image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=512x512>,
'mask': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=512x512>,
'worker': 'k',
'coco_details': {'captions': ['A stop sign is shown among foliage and grass.',
'A close up of a Stop sign near woods. ',
'A closeup of a large stop sign in the bushes.',
'A large oval Stop sign near some trees.',
'a close up of a stop sign with trees in the background'],
'coco_url': 'http://images.cocodataset.org/val2017/000000252332.jpg',
'date_captured': '2013-11-17 08:29:48',
'flickr_url': 'http://farm6.staticflickr.com/5261/5836914735_bef9249442_z.jpg',
'height': 480,
'id': 252332,
'image_license': 'https://creativecommons.org/licenses/by/2.0/',
'text_license': 'https://creativecommons.org/licenses/by/4.0/legalcode',
'width': 640},
'inpaint_details': {'duration': 18,
'guidance_scale': 7.5,
'num_inference_steps': 100,
'prompt': 'wooden bench',
'prompts_used': 2,
'quality': 'very good'},
'mask_details': {'height_factor': 25,
'prompt': 'stop sign',
'prompts_used': 1,
'width_factor': 25}}
```
## Dataset Creation
> The challenge set was created by undergraduate student workers. They were provided with an interactive Python environment with which they interacted via various prompts and inputs.
> The annotation proceeds as follows: The annotators are provided with an image and decide if the image is suitable for editing. If yes, they input the prompt for the object that should be replaced.
Using the open vocabulary segmentation model [CLIPSeg](https://huggingface.co/CIDAS/clipseg-rd64-refined) ([Lüddecke and Ecker, 2022](https://openaccess.thecvf.com/content/CVPR2022/html/Luddecke_Image_Segmentation_Using_Text_and_Image_Prompts_CVPR_2022_paper.html)) we obtain a mask for our object of interest (i.e., "fire hydrant"). Then, the annotator inputs a prompt for [Stable Diffusion v2 Inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) ([Rombach et al., 2022](https://ommer-lab.com/research/latent-diffusion-models/)) (e.g. with the prompt "yellow fire hydrant"), which shows three candidate images.
The annotators can try new prompts or skip the current image if the result is insufficient. Finally, the annotator enters a new caption that matches the edited image.
#### Source Data
InpaintCOCO is based on MS COCO 2017 validation set ([image](http://images.cocodataset.org/zips/val2017.zip), [annotations](http://images.cocodataset.org/annotations/annotations_trainval2014.zip)).
```
@misc{lin2015microsoft,
title={Microsoft COCO: Common Objects in Context},
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
year={2015},
eprint={1405.0312},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Limitations
> The images in the COCO dataset come from Flickr from 2014; therefore, they reflect the Flickr user structure at that time, i.e., the images mostly show the Western world and/or other countries from the Western perspective. The captions are in English. Thus, the model we developed does not generalize well beyond the Western world
## Licensing Information
* Images come with individual licenses (`image_license`) based on their Flickr source. The possible licenses are
* [CC BY-NC-SA 2.0 Deed](https://creativecommons.org/licenses/by-nc-sa/2.0/),
* [CC BY-NC 2.0 Deed](https://creativecommons.org/licenses/by-nc/2.0/),
* [CC BY 2.0 Deed](https://creativecommons.org/licenses/by/2.0/), and
* [CC BY-SA 2.0 Deed](https://creativecommons.org/licenses/by-sa/2.0/).
* The remaining work comes with the [CC BY 4.0 Legal Code](https://creativecommons.org/licenses/by/4.0/legalcode) license.
## Citation Information
Our InpaintCOCO dataset:
```
@misc{roesch2024enhancing,
title={Enhancing Conceptual Understanding in Multimodal Contrastive Learning through Hard Negative Samples},
author={Philipp J. Rösch and Norbert Oswald and Michaela Geierhos and Jindřich Libovický},
year={2024},
eprint={2403.02875},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
For the MS COCO dataset please see above.