swap-uniba/ETCII
收藏Hugging Face2026-05-09 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/swap-uniba/ETCII
下载链接
链接失效反馈官方服务:
资源简介:
ETCII(以文本为中心的意大利图像评估)是一个基准数据集,用于评估大型视觉语言模型在包含意大利文本的图像上进行视觉问答(VQA)的能力。数据集包含三种问题类别:幻觉(询问特定单词是否存在于图像中)、推理(需要基于图像内容进行常识推理)和知识(需要外部知识来回答问题)。数据集由107张独特的图像和1006个问答对组成。
ETCII (Evaluation of Text-Centric Italian Images), is a benchmark dataset to evaluate Large Vision-Language Models on VQA with images containing Italian text. The dataset has three question categories: hallucination (the question asks if a specific word is present within the image), reasoning (the correct answer requires common sense reasoning over the image contents), and knowledge (the correct answer requires external knowledge). The dataset consists of 107 unique images and 1006 question-answer pairs.
提供机构:
swap-uniba
原始信息汇总
数据集概述:ETCII (Evaluation of Text-Centric Italian Images)
- 数据集名称:ETCII
- 发布机构:swap-uniba (SWAP Research Group @ UNIBA)
- 数据集规模:1K - 10K 条数据(共 1,006 条问答对,107 张独特图像)
- 总文件大小:813 MB
- 数据格式:Parquet、optimized-parquet
- 数据模态:图像、文本
- 语言:意大利语
- 适用库:Datasets、Dask、Polars 等
- 最近下载量:12 次/月
数据集内容与结构
ETCII 是一个用于评估大型视觉-语言模型(Large Vision-Language Models)在包含意大利语文本的图像上进行视觉问答(VQA)能力的基准数据集。数据集包含以下三种问题类型:
- Hallucination(幻觉检测):询问图像中是否出现某个特定单词。
- Reasoning(推理):需要对图像内容进行常识推理,无需外部知识即可得出正确答案。
- Knowledge(知识):需要外部知识才能得出正确答案。
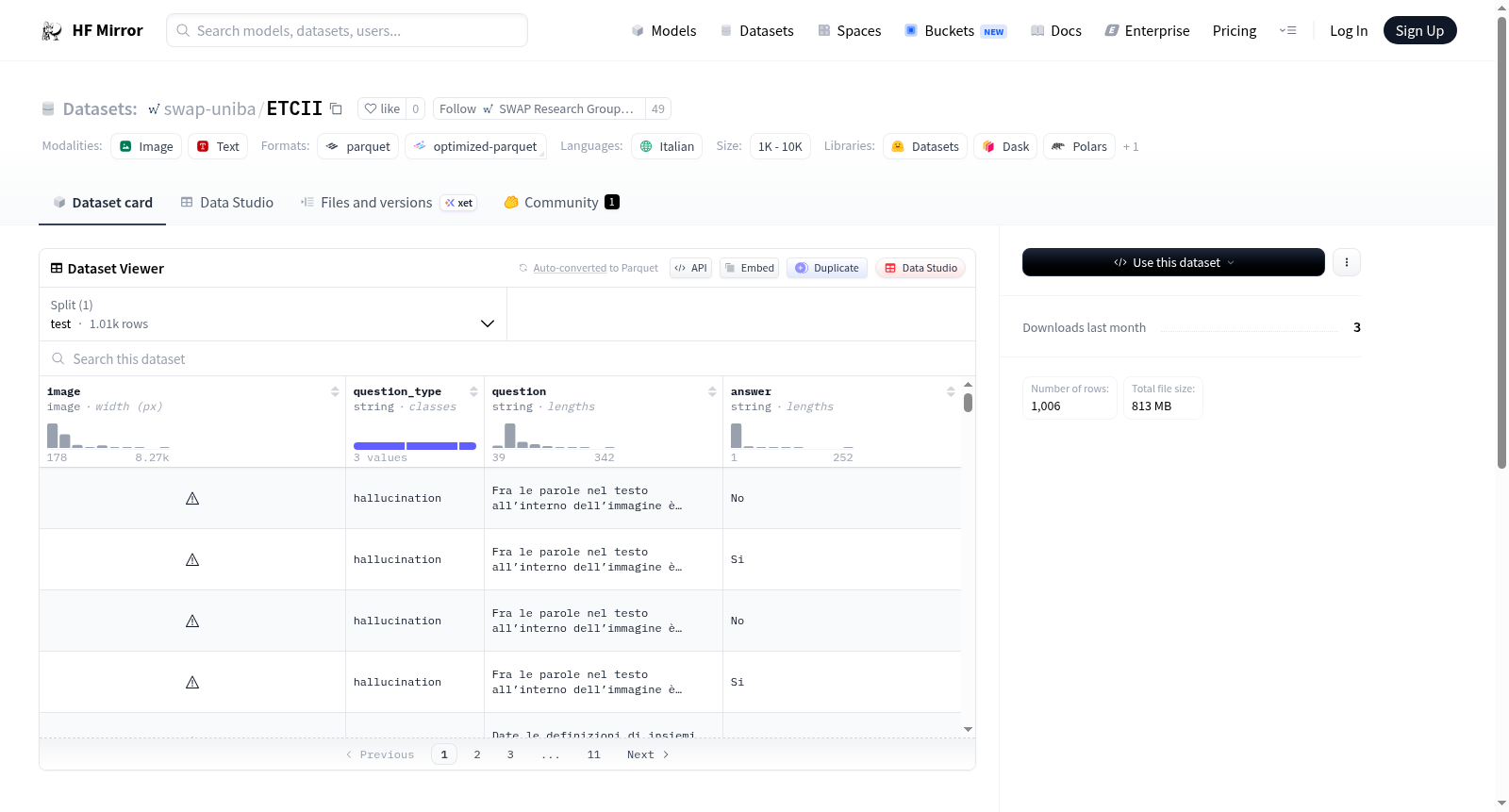
数据集包含一个子集(default),并仅提供 test 拆分(1,006 行),数据列包括:
image:图像数据imagewidth (px):图像宽度(像素)question_type:问题类型(字符串,共 3 个类别:hallucination、reasoning、knowledge)question:问题文本(字符串,长度范围 39-342 字符)answer:答案文本(字符串,长度范围 1-252 字符)
数据集用途
该数据集专门用于评估和训练多模态模型在处理包含意大利语文本的图像时的理解与问答能力。
搜集汇总
数据集介绍
构建方式
ETCII数据集的构建聚焦于意大利语文本图像,旨在评估大型视觉语言模型在文本中心视觉问答任务中的表现。数据集收集了107张包含意大利文字的真实场景图像,并针对每张图像精心设计了多组问题-答案对,最终形成1006个样本。问题的设计覆盖三种类型:幻觉型问题考察模型对图像中文本存在的判断能力;推理型问题要求模型结合图像内容进行常识性推理;知识型问题则需借助外部知识才能正确作答。所有样本均以标准化格式存储,包含图像、问题类型、问题文本及正确答案字段。
特点
该数据集的核心特点在于其专注意大利语文本图像的视觉问答评估,填补了非英语语言文本中心VQA基准的空白。样本规模虽仅含107张图像与1006个问答对,但通过精细的问题分类——幻觉、推理与知识——实现了对模型能力的多维度测试。每张图像配备约9.4个问题,确保了评估的密集性与多样性。此外,数据集仅提供测试集,避免了训练集泄露可能带来的过拟合风险,适合用于模型性能的最终基准测试。
使用方法
使用ETCII数据集时,研究者可直接从HuggingFace平台加载默认配置下的测试集。数据格式包含图像、问题类型、问题文本及答案四个字段,便于直接输入大型视觉语言模型进行推理。评估时需关注模型对三类问题的回答准确性,特别是幻觉型问题的文本检测能力与推理型问题的常识理解表现。由于数据集专注于意大利语,使用前应确保模型具备处理意大利文本与视觉内容交互的能力。建议结合官方论文中的统计信息与构建细节进行结果分析。
背景与挑战
背景概述
ETCII(Evaluation of Text-Centric Italian Images)数据集由意大利研究团队于近年创建,旨在评估大规模视觉语言模型在处理包含意大利语文本的图像时的视觉问答能力。随着多模态模型的快速发展,现有基准大多聚焦于英语场景,对非英语语言尤其是视觉文本的理解评估存在显著空白。该数据集通过107张独特图像和1006个问答对,系统性地考察模型在文本幻觉检测、常识推理及外部知识运用三个维度的表现,为意大利语视觉文本理解领域提供了首个标准化评测资源,推动了多语言视觉问答研究的深入发展。
当前挑战
该数据集所解决的领域核心挑战在于视觉语言模型对非英语文本图像的理解不足,尤其缺乏针对意大利语场景的基准测试,导致模型在实际应用如文档分析、场景文本问答中表现不可控。在构建过程中,研究人员面临图像中文本多样性与场景复杂性的平衡难题,需精心挑选包含不同字体、排版及背景噪声的意大利语图像,同时设计三类问题以区分模型能力层次,确保问答对不依赖外部知识或存在歧义,有效规避数据泄漏风险,最终形成兼具难度与代表性的评测集。
常用场景
经典使用场景
ETCII数据集专为评估大型视觉-语言模型在包含意大利文本的图像上的视觉问答能力而设计。其经典使用场景聚焦于三大核心任务:幻觉检测、推理判断以及知识调用。具体而言,该数据集通过询问图像中特定词汇是否存在以检验模型的幻觉倾向,通过要求模型基于图像内容进行常识推理以评估其逻辑能力,并通过依赖外部知识的问题类型测量模型的知识整合水平。这种多维度的评估框架,使得ETCII成为检验多模态模型在跨语言和文本密集型视觉场景下综合性能的标准化基准。
解决学术问题
ETCII数据集主要解决了多模态领域中的一个关键学术痛点:现有视觉-语言模型评估基准大多以英语为中心,缺乏对低资源语言(如意大利语)中文本-视觉交互能力的系统性评测。该数据集通过构建包含107张独特图像和1006个问答对的精细标注资源,首次提供了针对意大利语场景的标准化验证平台。它使研究者能够量化模型在非英语文本存在时的视觉理解缺陷,特别是从幻觉抑制、常识推理和知识检索三个维度剖析模型的局限性,从而推动多语言多模态模型的理论改进方向。
衍生相关工作
围绕ETCII数据集,学术界已衍生出多项开拓性工作。一方面,研究者基于其分类评估框架,开发了专门针对意大利语文本图像的多模态模型微调策略,通过强化文本-视觉联合表示学习来提升模型在低资源语言场景下的表现。另一方面,该数据集催生了一系列跨语言视觉问答的对比研究,研究者将其与英语基准(如TextVQA)联合分析,揭示了模型在语言迁移时知识表征的差异性规律。此外,ETCII的三类问题设计范式也被后续工作借鉴,用于构建其他语种(如西班牙语、法语)的文本中心视觉评估集,形成多语言评估生态。
以上内容由遇见数据集搜集并总结生成


