danish-foundation-models/norwegian-dynaword
收藏Hugging Face2026-05-03 更新2026-02-07 收录
下载链接:
https://hf-mirror.com/datasets/danish-foundation-models/norwegian-dynaword
下载链接
链接失效反馈官方服务:
资源简介:
Norwegian Dynaword是一个包含多种挪威语自由文本的数据集,涵盖了多个领域(如法律、书籍、社交媒体等)。数据集是持续开发的,意味着会不断更新。数据集中的文本都是公开许可的,适合用于训练大型语言模型。数据集包含挪威语的多种变体,如Bokmål和Nynorsk,以及少量的英语和丹麦语。数据集的结构包括多个子集,每个子集都有详细的描述和统计信息。
The Norwegian dynaword is a collection of Norwegian free-form text datasets from various domains. All of the datasets in the Norwegian Dynaword are openly licensed and deemed permissible for training large language models. Norwegian dynaword is continually developed, which means that the dataset will actively be updated as new datasets become available. The dataset includes multiple variants of Norwegian, such as Bokmål and Nynorsk, as well as small amounts of English and Danish. The dataset structure includes multiple subsets, each with detailed descriptions and statistics.
提供机构:
danish-foundation-models
搜集汇总
数据集介绍
构建方式
挪威语动态词库(Norwegian Dynaword)是一个持续演进的自由文本语料集合,旨在为大型语言模型的训练提供开放许可的挪威语数据。该数据集通过整合来自不同领域的多个子集构建而成,涵盖议会演讲记录、机构网站内容、公共领域书籍、政府报告、百科全书、新闻报刊及法律条文等多元来源。每个子集均附有独立的数据表以记录其收集与处理流程,部分来源还提供了可复现的构建脚本。数据集采用持续开发模式,随着新资源的涌现而动态更新,并通过自动化的质量检查确保格式规范、标识唯一性及文档完整性,但不实施过度清洗,以保留原始文本特征。
特点
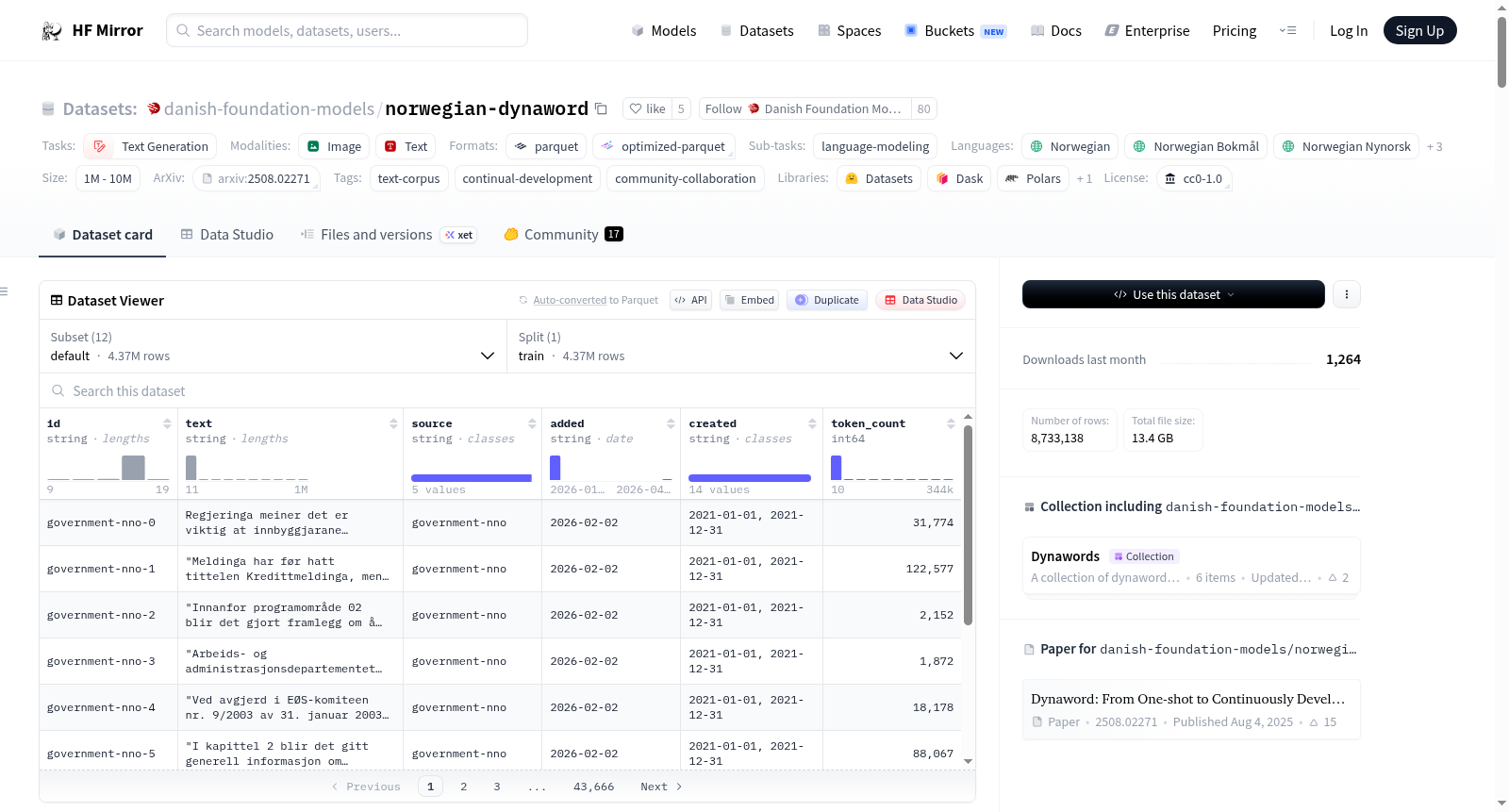
该数据集具有显著的多维度覆盖特性,在语言层面包含挪威语布克莫尔文、尼诺斯克文及未明确区分的挪威语,在领域层面覆盖口语、网页、书籍、报告、百科、新闻和法律等七大类。数据集总量达4.37M个样本,包含约7.94B个词元(基于Llama 3分词器计算),平均文档长度为1.82K词元。每个样本均配有丰富的元数据,包括唯一标识符、文本内容、来源标识、添加日期、原始创建时间及词元数量,便于研究者进行细粒度的语料分析与筛选。
使用方法
用户可通过Hugging Face的datasets库便捷加载该数据集,支持全量加载和流式加载两种模式。默认加载方式为`load_dataset('danish-foundation-models/norwegian-dynaword', split='train')`,也可通过指定子集名称(如'maalfrid')加载单一来源的数据。为确保实验可重复性,建议在加载时指定修订版本号(revision参数)。数据集仅提供训练集切分,所有数据均可在单个split中获取,便于直接用于语言模型预训练、文本生成或其他自然语言处理任务。
背景与挑战
背景概述
挪威语作为北欧语言中的重要成员,其形态丰富、方言多样且包含书面语波克摩尔语与尼诺斯克语两种官方标准形式,这对自然语言处理研究提出了独特挑战。Norwegian Dynaword数据集由丹麦基础模型团队与挪威国家图书馆等机构协作构建,于2025年发布,旨在为挪威语大语言模型训练提供持续演进的开放式语料资源。该数据集整合了来自议会记录、政府报告、法律文本、新闻、百科全书及书籍等多个领域的自由文本,涵盖约79.4亿个令牌,是当前规模最大、覆盖面最广的挪威语公开语料库。其创建核心研究问题在于,如何构建一个能够动态更新、反映语言演化并支持低资源语言模型开发的高质量数据集,为斯堪的纳维亚语系的语言技术研究奠定了重要基础。
当前挑战
该数据集面临的首要挑战在于挪威语的双语标准并存与方言混杂性,不同来源文本中波克摩尔语与尼诺斯克语的分布不均,且存在语言误分类风险,影响模型的语言一致性学习。构建过程中,数据采集需从多个开放许可来源整合,面临OCR文本质量参差、历史文档格式差异大等难题,尤其是议会记录与报纸等OCR材料的噪音处理。此外,持续开发模式要求维护版本控制与质量保障机制,包括去重检测、空文档过滤和元数据标准化,但需避免过度清洗以保留后续方法论创新的空间。法律与政府数据还涉及敏感信息与归属条款的合规处理,进一步增加了数据治理的复杂性。
常用场景
经典使用场景
在自然语言处理领域,挪威语动态语料库(Norwegian Dynaword)的核心应用在于为大语言模型的预训练与持续学习提供高质量、多领域的文本数据。该数据集汇聚了来自议会演讲、法律文献、政府报告、百科全书、新闻、书籍及网络文本等十余种来源的挪威语语料,覆盖了书面语(尼诺斯克语与博克马尔语)与口语的丰富变体。研究者常将其用作语言模型从零开始训练或领域自适应微调的基础语料库,尤其适合探索低资源语言在持续发展范式下的数据扩充策略。得益于其开放性许可与持续更新的机制,该数据集成为了挪威语自然语言处理研究中不可或缺的资源基石。
解决学术问题
挪威语动态语料库解决了挪威语自然语言处理研究中长期面临的语料匮乏与领域覆盖不均问题。传统挪威语数据集多局限于单一领域或静态快照,难以支撑跨领域语言建模与语言演变分析。该数据集通过整合议会记录、政府文件、百科全书、新闻与书籍等多元异构来源,填补了法律、政务、新闻等专业领域数据缺失的空白。其持续发展特性允许研究者追踪语言使用的历时变化,探索词汇语义漂移与文体差异。此外,数据集提供的精细元数据(如来源、时间戳)为检测模型偏见、评估领域间性能差异提供了方法论基础,有力推动了低资源语言语料库建设规范的演进。
衍生相关工作
基于挪威语动态语料库,学界衍生了一系列挪威语大语言模型与基准评测工作。例如,研究者利用该数据集训练了首个覆盖两种挪威语书写标准的持续学习模型,验证了多领域增量训练对语言生成质量的提升效果。在评估方面,衍生工作构建了挪威语领域的基准测试集,涵盖词义消歧、文本分类与机器翻译等任务,系统对比了不同预训练语料配置下的模型表现。此外,数据集本身推动了语料处理流程的开放研究,包括自动质量检查协议的规范化、跨源数据去重算法的优化,以及元数据对齐方案的标准化,这些方法论贡献已被后续更多低资源语言语料库项目所采纳。
以上内容由遇见数据集搜集并总结生成


