allenai/sciq
收藏Hugging Face2024-01-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/allenai/sciq
下载链接
链接失效反馈资源简介:
---
annotations_creators:
- no-annotation
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-nc-3.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- closed-domain-qa
paperswithcode_id: sciq
pretty_name: SciQ
dataset_info:
features:
- name: question
dtype: string
- name: distractor3
dtype: string
- name: distractor1
dtype: string
- name: distractor2
dtype: string
- name: correct_answer
dtype: string
- name: support
dtype: string
splits:
- name: train
num_bytes: 6546183
num_examples: 11679
- name: validation
num_bytes: 554120
num_examples: 1000
- name: test
num_bytes: 563927
num_examples: 1000
download_size: 4674410
dataset_size: 7664230
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# Dataset Card for "sciq"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://allenai.org/data/sciq](https://allenai.org/data/sciq)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 2.82 MB
- **Size of the generated dataset:** 7.68 MB
- **Total amount of disk used:** 10.50 MB
### Dataset Summary
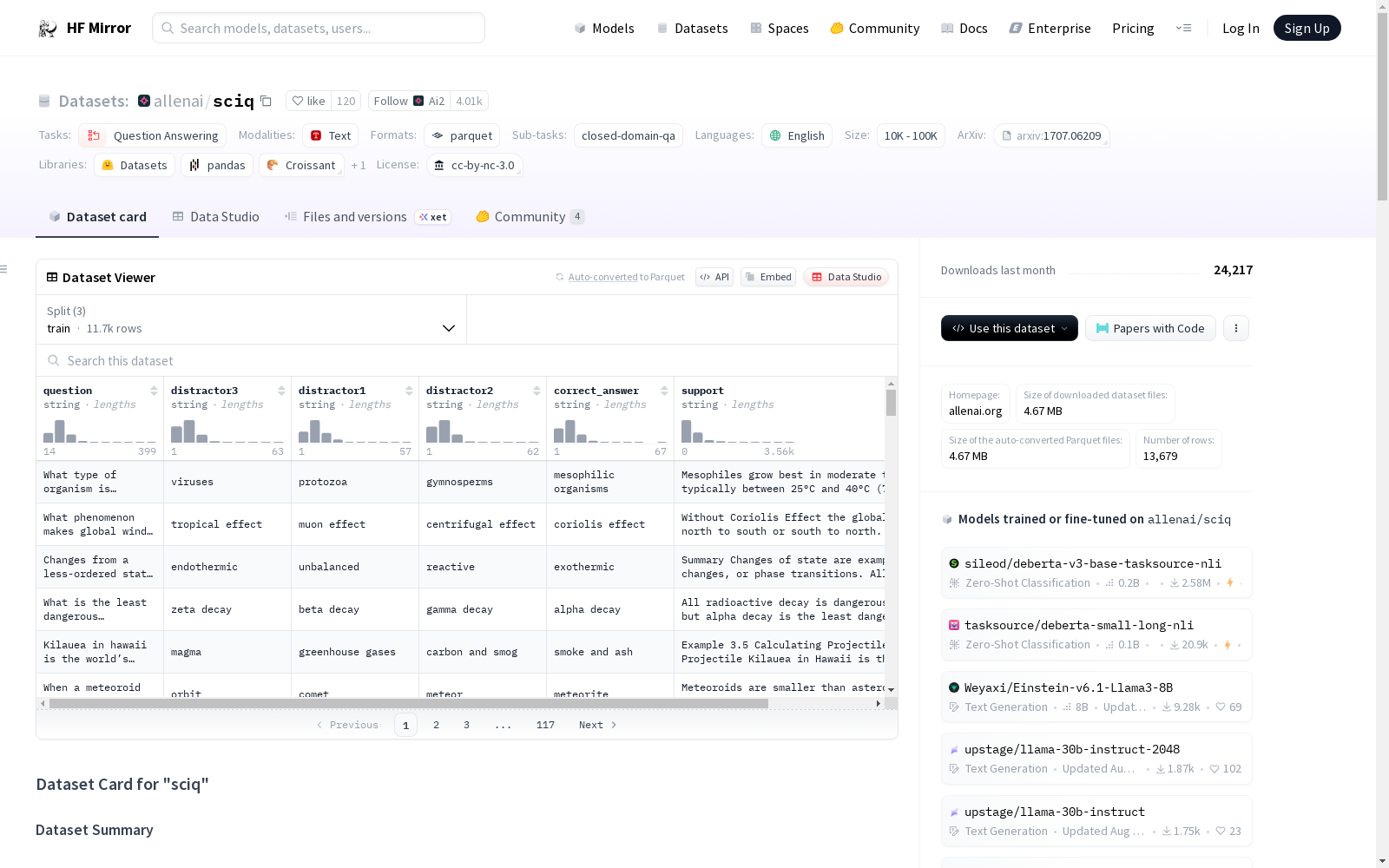
The SciQ dataset contains 13,679 crowdsourced science exam questions about Physics, Chemistry and Biology, among others. The questions are in multiple-choice format with 4 answer options each. For the majority of the questions, an additional paragraph with supporting evidence for the correct answer is provided.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### default
- **Size of downloaded dataset files:** 2.82 MB
- **Size of the generated dataset:** 7.68 MB
- **Total amount of disk used:** 10.50 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"correct_answer": "coriolis effect",
"distractor1": "muon effect",
"distractor2": "centrifugal effect",
"distractor3": "tropical effect",
"question": "What phenomenon makes global winds blow northeast to southwest or the reverse in the northern hemisphere and northwest to southeast or the reverse in the southern hemisphere?",
"support": "\"Without Coriolis Effect the global winds would blow north to south or south to north. But Coriolis makes them blow northeast to..."
}
```
### Data Fields
The data fields are the same among all splits.
#### default
- `question`: a `string` feature.
- `distractor3`: a `string` feature.
- `distractor1`: a `string` feature.
- `distractor2`: a `string` feature.
- `correct_answer`: a `string` feature.
- `support`: a `string` feature.
### Data Splits
| name |train|validation|test|
|-------|----:|---------:|---:|
|default|11679| 1000|1000|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
The dataset is licensed under the [Creative Commons Attribution-NonCommercial 3.0 Unported License](http://creativecommons.org/licenses/by-nc/3.0/).
### Citation Information
```
@inproceedings{SciQ,
title={Crowdsourcing Multiple Choice Science Questions},
author={Johannes Welbl, Nelson F. Liu, Matt Gardner},
year={2017},
journal={arXiv:1707.06209v1}
}
```
### Contributions
Thanks to [@patrickvonplaten](https://github.com/patrickvonplaten), [@lewtun](https://github.com/lewtun), [@thomwolf](https://github.com/thomwolf) for adding this dataset.
提供机构:
allenai
原始信息汇总
数据集概述
基本信息
- 数据集名称: SciQ
- 语言: 英语 (en)
- 许可证: Creative Commons Attribution-NonCommercial 3.0 Unported License (cc-by-nc-3.0)
- 多语言性: 单语种
- 数据集大小: 10K<n<100K
- 源数据: 原始数据
- 任务类别: 问答 (question-answering)
- 任务ID: 封闭领域问答 (closed-domain-qa)
- 论文代码ID: sciq
- 美观名称: SciQ
数据集结构
-
特征:
question: 字符串类型distractor3: 字符串类型distractor1: 字符串类型distractor2: 字符串类型correct_answer: 字符串类型support: 字符串类型
-
数据分割:
train: 11679个样本,6546183字节validation: 1000个样本,554120字节test: 1000个样本,563927字节
数据集创建
- 语言创建者: 众包
- 注释创建者: 无注释
使用考虑
- 许可证信息: 数据集根据Creative Commons Attribution-NonCommercial 3.0 Unported License授权。
引用信息
@inproceedings{SciQ, title={Crowdsourcing Multiple Choice Science Questions}, author={Johannes Welbl, Nelson F. Liu, Matt Gardner}, year={2017}, journal={arXiv:1707.06209v1} }
贡献者
AI搜集汇总
数据集介绍
构建方式
SciQ数据集通过搜集众包的科学试题构建而成,涵盖了物理、化学和生物学等多个科学领域。该数据集包含13,679个多项选择题,每个问题有四个选项,并伴有正确答案的支撑证据段落。数据集分为训练集、验证集和测试集,分别包含11679、1000和1000个问题实例。
使用方法
使用SciQ数据集时,用户需遵循相应的许可证规定。数据集可通过HuggingFace的dataset库进行下载和加载。加载后,用户可以根据需要访问问题、选项、正确答案以及答案的支撑证据等字段,进行封闭域问答等任务的训练和评估。
背景与挑战
背景概述
SciQ数据集,由Allen Institute for Artificial Intelligence(AI2)的研究团队于2017年创建,旨在为自然语言处理和机器学习领域提供一项挑战,即科学知识问答任务。该数据集汇集了13,679个众包的科学选择题,内容涉及物理、化学和生物学等多个学科领域,并提供了支持正确答案的额外证据段落。SciQ数据集以其独特的科学问题收集和格式化方式,对科学知识问答领域的研究产生了显著影响,为模型训练和评估提供了宝贵的资源。
当前挑战
SciQ数据集面临的挑战主要包括:1) 领域知识的深度和广度问题,需要模型具备较强的科学知识理解能力;2) 数据构建过程中的众包方式可能引入噪声和偏差,影响数据质量;3) 多选题形式要求模型不仅能理解问题,还要在多个干扰项中准确识别正确答案;4) 数据集的多样性和公平性问题,如何确保数据覆盖不同知识层次和背景的学习者。
常用场景
经典使用场景
在科学知识问答系统的构建与评估领域,SciQ数据集被广泛作为基准测试集使用,其包含的物理、化学和生物学等科学领域的问题,以多项选择题的形式呈现,为模型提供了丰富的训练和验证场景。
解决学术问题
SciQ数据集有效解决了科学知识问答研究中的数据缺乏问题,为研究者提供了一个大规模、 crowdsourced的科学问题库,从而推动了相关模型的性能提升和算法改进。
实际应用
在实际应用中,SciQ数据集可用于教育科技产品的开发,如在线学习平台中的智能辅导系统,以帮助学生通过互动式问答加深对科学概念的理解。
数据集最近研究
最新研究方向
在知识问答领域,SciQ数据集以其高质量的科普题目及解答,成为自然语言处理任务中闭域问答研究的重点。近期研究主要围绕提升模型对复杂科学概念的理解和准确回答能力,涉及多模型融合、上下文信息利用等策略。这些研究对于推动教育辅助技术的发展,提高在线学习效率具有显著意义。
以上内容由AI搜集并总结生成


