---
license: mit
task_categories:
- text-generation
- question-answering
- summarization
- zero-shot-classification
language:
- en
tags:
- medical
- clinical
- healthcare
- instruction-finetuning
- multi-task learning
size_categories:
- 10K<n<100K
---
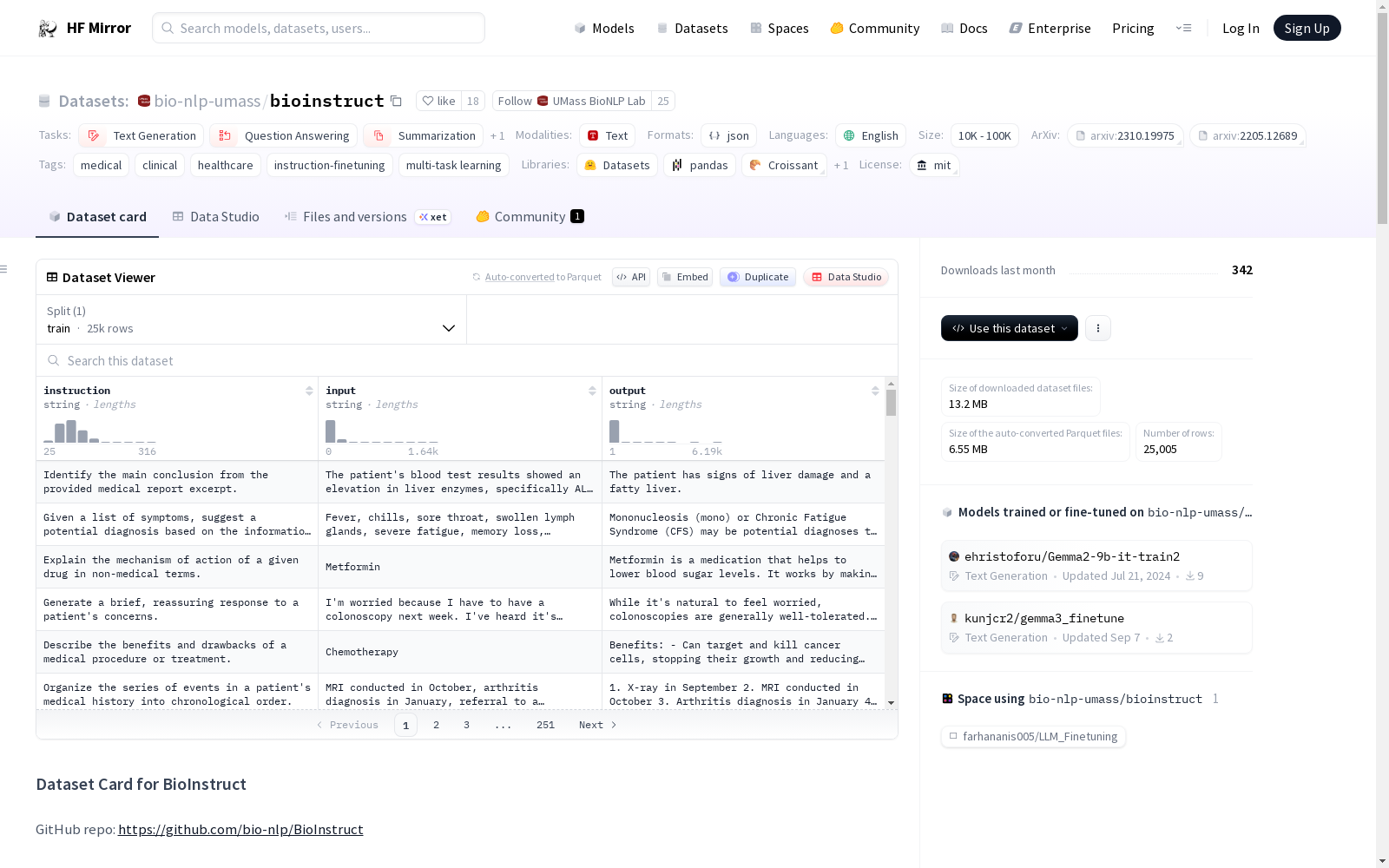
# Dataset Card for BioInstruct
GitHub repo: https://github.com/bio-nlp/BioInstruct
## Dataset Summary
[BioInstruct](https://academic.oup.com/jamia/advance-article/doi/10.1093/jamia/ocae122/7687618) is a dataset of 25k instructions and demonstrations generated by OpenAI's GPT-4 engine in July 2023.
This instruction data can be used to conduct instruction-tuning for language models (e.g. Llama) and make the language model follow biomedical instruction better.
Improvements of Llama on 9 common BioMedical tasks are shown in the [result section](https://arxiv.org/pdf/2310.19975).
Taking inspiration from [Self-Instruct](https://github.com/yizhongw/self-instruct), the collection of BioInstruct is a fully automated process. This process requires only an initial set of 80 manually constructed seed tasks, which can be produced within roughly three hours of human effort. These seed examples span a diverse range of biomedical and clinical NLP tasks, covering areas such as answering biomedical questions, summarizing, assessing eligibility for clinical trials, and determining differential diagnoses. During the data collection phase, we prompted the pretrained GPT-4 language model with three examples randomly selected from seed tasks, guiding it to generate new samples.
Among the GPT-4 created instructions, we plot the top 20 most common root verbs and their top 4 direct noun objects of BioInstruct dataset in Figure below.
We further used GPT-4 to classify the instructions into the following 4 major categories. Below is proportion in this dataset:
- 33.8% on information extract.
- 33.5% on text generation.
- 22.8% on question answering.
- 10.0% on others.
Seed examples were collected from the training split of biomedical dataset below (see [paper](https://arxiv.org/pdf/2310.19975) for a comprehensive list):
[MeQSum](https://huggingface.co/datasets/sumedh/MeQSum),
[Primock57](https://github.com/babylonhealth/primock57),
[MedQA](https://huggingface.co/collections/lavita/medical-qa-datasets-6540b9b1992b1c560eda935c),
[emrQA](https://github.com/panushri25/emrQA#download-dataset),
[DiSCQ](https://github.com/elehman16/discq),
[MEDIQA-AnS](https://osf.io/9afru),
[CliCR](https://github.com/clips/clicr),
[Diagnoise-me](https://www.kaggle.com/datasets/dsxavier/diagnoise-me?resource=download),
[pubhealth](https://huggingface.co/datasets/bigbio/pubhealth),
[MedNLI](https://huggingface.co/datasets/bigbio/mednli),
[CASI](https://arxiv.org/pdf/2205.12689),
[Medal](https://huggingface.co/datasets/McGill-NLP/medal),
[MedTextSimplifier](https://github.com/vanh17/MedTextSimplifier),
BIOSSES,
ChemProt,
GAD

## Dataset Structure
### Data Instances
An example of "train" looks as follows:
```json{
"instruction": "Explain the mechanism of action of a given drug in non-medical terms.",
"input": "Metformin",
"output": "Metformin is a medication that helps to lower blood sugar levels. It works by making your body more sensitive to insulin, a hormone that helps control sugar levels, and by decreasing the amount of sugar your liver produces."
}
```
### Data Fields
The data fields are as follows:
* `instruction`: describes the task the model should perform. Each of the 25K instructions is unique.
* `input`: optional context or input for the task. For example, when the instruction is "Explain how the drug works", the input is the drug name.
* `output`: the answer to the instruction as generated by GPT-4.
### Languages
The data in BioInstruct are in English (BCP-47 en).
### Licensing Information
The dataset is available under the MIT license.
### Citation Information
```
@article{Tran2024Bioinstruct,
author = {Tran, Hieu and Yang, Zhichao and Yao, Zonghai and Yu, Hong},
title = "{BioInstruct: instruction tuning of large language models for biomedical natural language processing}",
journal = {Journal of the American Medical Informatics Association},
pages = {ocae122},
year = {2024},
month = {06},
issn = {1527-974X},
doi = {10.1093/jamia/ocae122},
url = {https://doi.org/10.1093/jamia/ocae122},
eprint = {https://academic.oup.com/jamia/advance-article-pdf/doi/10.1093/jamia/ocae122/58084577/ocae122.pdf},
}
```
### Acknowledgments
We thank [bigbio](https://huggingface.co/bigbio), [openlifescienceai](https://huggingface.co/openlifescienceai), and [hf4h](https://huggingface.co/hf4h) for organizing a collection of biomedical datasets.
We thank [Meta](https://huggingface.co/meta-llama) for releasing their Llama models.
### Contribution
[Hieu Tran](https://huggingface.co/hieutran81), [Zhichao Yang](https://huggingface.co/whaleloops), Zonghai Yao, Hong Yu
license: MIT协议
task_categories:
- 文本生成
- 问答
- 摘要
- 零样本分类(zero-shot-classification)
language:
- 英语
tags:
- 医疗
- 临床
- 医疗健康
- 指令微调(instruction-finetuning)
- 多任务学习(multi-task learning)
size_categories:
- 10K<n<100K
# BioInstruct数据集卡片
GitHub仓库:https://github.com/bio-nlp/BioInstruct
## 数据集概述
[BioInstruct](https://academic.oup.com/jamia/advance-article/doi/10.1093/jamia/ocae122/7687618) 是一个包含25000条指令与演示样本的数据集,所有样本由OpenAI的GPT-4引擎于2023年7月生成。
该指令数据可用于对大语言模型(Large Language Model, LLM,如Llama)进行指令微调,以提升模型对生物医学指令的遵循能力。在9项常见生物医学任务上对Llama的改进效果已在[结果章节](https://arxiv.org/pdf/2310.19975)中展示。
本数据集的构建灵感源自[Self-Instruct](https://github.com/yizhongw/self-instruct),全程采用全自动流程完成。该流程仅需80条人工构建的种子任务作为初始输入,仅需约3小时的人工工作量即可完成种子任务的制作。这些种子示例涵盖了多样的生物医学与临床自然语言处理任务,包括回答生物医学问题、文本摘要、评估临床试验入组资格以及鉴别诊断等领域。在数据采集阶段,我们从种子任务中随机选取3个示例作为提示,引导预训练的GPT-4大语言模型生成新的样本。
在GPT-4生成的指令中,我们绘制了BioInstruct数据集中前20个最常见的根动词及其前4个直接名词宾语的统计图(如下图所示)。我们进一步使用GPT-4将指令划分为以下4大类别,各分类在数据集中的占比如下:
- 信息提取类:33.8%
- 文本生成类:33.5%
- 问答类:22.8%
- 其他类:10.0%
种子示例采集自以下生物医学数据集的训练划分(完整列表详见[论文](https://arxiv.org/pdf/2310.19975)):
[MeQSum](https://huggingface.co/datasets/sumedh/MeQSum)、[Primock57](https://github.com/babylonhealth/primock57)、[MedQA](https://huggingface.co/collections/lavita/medical-qa-datasets-6540b9b1992b1c560eda935c)、[emrQA](https://github.com/panushri25/emrQA#download-dataset)、[DiSCQ](https://github.com/elehman16/discq)、[MEDIQA-AnS](https://osf.io/9afru)、[CliCR](https://github.com/clips/clicr)、[Diagnoise-me](https://www.kaggle.com/datasets/dsxavier/diagnoise-me?resource=download)、[pubhealth](https://huggingface.co/datasets/bigbio/pubhealth)、[MedNLI](https://huggingface.co/datasets/bigbio/mednli)、[CASI](https://arxiv.org/pdf/2205.12689)、[Medal](https://huggingface.co/datasets/McGill-NLP/medal)、[MedTextSimplifier](https://github.com/vanh17/MedTextSimplifier)、BIOSSES、ChemProt、GAD

## 数据集结构
### 数据实例
训练集的一个示例格式如下:
json
{
"instruction": "用非医学术语解释某一给定药物的作用机制。",
"input": "二甲双胍",
"output": "二甲双胍是一种可降低血糖水平的药物。其作用机制为提高机体对胰岛素(一种协助调控血糖水平的激素)的敏感性,并减少肝脏生成的葡萄糖量。"
}
### 数据字段
各数据字段说明如下:
* `instruction`:描述模型需执行的任务,25000条指令均唯一。
* `input`:任务的可选上下文或输入。例如,当指令为"解释药物的工作原理"时,输入即为药物名称。
* `output`:由GPT-4生成的对应指令的答案。
### 语言说明
BioInstruct数据集采用英语(BCP-47编码为en)。
### 许可证信息
本数据集采用MIT协议进行授权。
### 引用信息
@article{Tran2024Bioinstruct,
author = {Tran, Hieu and Yang, Zhichao and Yao, Zonghai and Yu, Hong},
title = "{BioInstruct: instruction tuning of large language models for biomedical natural language processing}",
journal = {Journal of the American Medical Informatics Association},
pages = {ocae122},
year = {2024},
month = {06},
issn = {1527-974X},
doi = {10.1093/jamia/ocae122},
url = {https://doi.org/10.1093/jamia/ocae122},
eprint = {https://academic.oup.com/jamia/advance-article-pdf/doi/10.1093/jamia/ocae122/58084577/ocae122.pdf},
}
### 致谢
感谢[bigbio](https://huggingface.co/bigbio)、[openlifescienceai](https://huggingface.co/openlifescienceai)以及[hf4h](https://huggingface.co/hf4h)团队整理并提供生物医学数据集。
感谢[Meta](https://huggingface.co/meta-llama)团队开源其Llama系列模型。
### 贡献者
[Hieu Tran](https://huggingface.co/hieutran81)、[Zhichao Yang](https://huggingface.co/whaleloops)、Zonghai Yao、Hong Yu