C^3-Bench
收藏github2025-06-27 更新2025-06-28 收录
下载链接:
https://github.com/Tencent-Hunyuan/C3-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
基于大型语言模型的代理利用工具修改环境,彻底改变了AI与物理世界的互动方式。与传统NLP任务不同,这些代理在做出选择时必须考虑更复杂的因素,如工具间关系、环境反馈和先前决策等。C^3-Bench是一个开源高质量的基准测试,集成了攻击概念并应用单变量分析来识别影响代理鲁棒性的关键元素。具体设计了三个挑战:导航复杂工具关系、处理关键隐藏信息和管理动态决策路径。此外,还引入了细粒度指标、创新数据收集算法和可复现的评估方法。在49个主流代理上进行了广泛实验,涵盖通用快速思考、慢速思考和领域特定模型。
Agent systems based on large language models that leverage tools to modify environments have revolutionized how AI interacts with the physical world. Unlike traditional natural language processing (NLP) tasks, these agents must consider far more complex factors when making choices, such as inter-tool relationships, environmental feedback, prior decisions, and more. C^3-Bench is an open-source, high-quality benchmark that integrates attack concepts and applies univariate analysis to identify key elements affecting agent robustness. It specifically designs three core challenges: navigating complex tool relationships, handling critical hidden information, and managing dynamic decision-making paths. Additionally, it introduces fine-grained metrics, innovative data collection algorithms, and reproducible evaluation methodologies. Extensive experiments have been conducted on 49 mainstream agents, covering general fast-thinking, slow-thinking, and domain-specific models.
创建时间:
2025-06-26
原始信息汇总
C3-Bench 数据集概述
📖 数据集简介
- 名称: C3-Bench
- 目标: 评估基于大语言模型的智能体在多任务环境中的鲁棒性
- 特点:
- 开源高质量基准测试
- 整合攻击概念并应用单变量分析
- 设计三大挑战:复杂工具关系导航、关键隐藏信息处理、动态决策路径管理
😊 核心材料
- 测试数据位置:
- 本地路径:
c3_bench/data/C3-Bench.jsonl - HuggingFace地址: https://huggingface.co/datasets/tencent/C3-BenchMark
- 本地路径:
- 语言支持: 英语和中文
⚡️ 快速开始
基础安装
bash conda create -n C3-Bench python=3.10 conda activate C3-Bench git clone https://github.com/Tencent-Hunyuan/C3-Benchmark.git cd c3_bench/ pip install -r requirements.txt
💾 测试数据详情
- 数据质量: 经过五轮人工检查和修正,确保100%准确性
- 数据特点:
- 覆盖所有可能的动作空间
- 包含真实多轮任务
- 平衡的数据分布
- 优化阶段:
- 初始数据生成
- 四类动作划分和人工修正
- 专家评审和二次修正
- 交叉验证和三轮修正
- 最终专家检查和代码验证
🛠️ 评估框架
- 特点:
- 高可复现性
- 高评估效率
- 高代码复用性
- 多维度分析
- 强扩展性
- 框架图:

🤖 模型支持
- API模型: 支持如hunyuan-turbos-latest等
- HuggingFace模型: 支持多种开源模型
- 部署方式: 推荐使用vllm部署
💫 评估方法
bash python3 analysis_result.py --data_file PREDICT_DATA_FILE --output_csv_flag=True --output_csv_path=./data_with_details.csv
🧠 可控多智能体数据生成框架
- 特点:
- 可控任务生成
- 指定数量任务生成
- 多样化任务生成
- 真实多轮任务生成
- 丰富的智能体类型
- 强大的规划器和检查器
- 任意模型指定
- 双语支持
⚡️ 快速开始示例
bash export MODEL=hunyuan-turbos-latest export API_KEY=xxxxxxxxx export BASE_URL=https://api.hunyuan.cloud.tencent.com/v1 export LANGUAGE=zh
cd multi_agent python3 generate.py --layer_num_total 4 --user_model ["hunyuan-turbos-latest"] --planner_model "hunyuan-turbos-latest" --tool_model "hunyuan-turbos-latest" --agent_model "hunyuan-turbos-latest" --checker_model "hunyuan-turbos-latest"
搜集汇总
数据集介绍
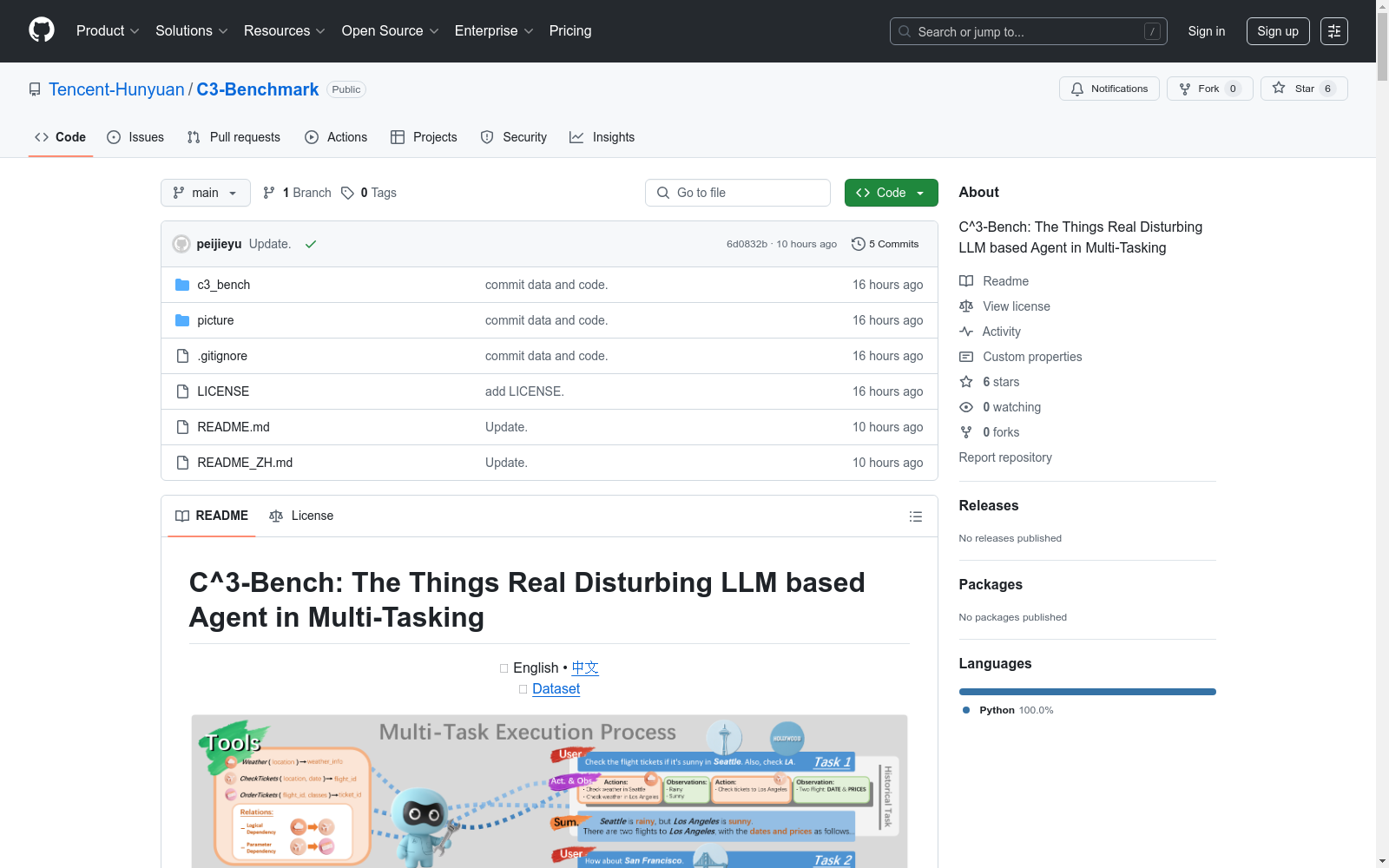
构建方式
C^3-Bench数据集的构建采用了创新的多智能体数据生成框架,通过五轮人工校验与修正确保数据质量。研究团队首先利用Multi Agent Data Generation框架生成覆盖全部动作空间的初始数据,随后由四位资深算法研究员分阶段进行人工校验与修正,包括口语化处理、真实多轮任务设计等关键环节。每轮数据生成后立即进行人工校验,采用分层构建策略确保层间逻辑一致性。最终由领域专家进行五轮交叉验证,结合自动化代码检查,将数据准确率从初始60%提升至100%。这种模型生成与人工校验相结合的构建方式,既保证了数据的全面性,又确保了高质量与多样性。
使用方法
使用C^3-Bench数据集需通过其模块化评估框架,该框架采用推理与结果分析分离的架构。用户可通过标准ToolCalls协议接入API模型或HuggingFace模型,支持动态评估和决策树剪枝技术提升效率。评估过程分为两个阶段:首先通过EvalByToolCallGraph模块进行动作匹配判断,随后使用AnalysisResult模块进行六维度的细粒度分析,结果以CSV格式输出。框架具有高度可扩展性,支持快速集成新模型,并提供bad case分析功能。对于多模型比较,支持同时评估多个预测结果文件,极大提升了研究效率。
背景与挑战
背景概述
C^3-Bench是由腾讯混元团队开发的一个高质量基准测试数据集,旨在评估基于大语言模型(LLM)的智能体在多任务环境中的表现。该数据集于近期发布,专注于解决智能体在复杂工具调用、环境反馈和动态决策路径等方面的挑战。传统评估方法通常依赖于多轮对话,而C^3-Bench通过引入攻击概念和单变量分析,揭示了影响智能体鲁棒性的关键因素。该数据集的构建经历了多轮人工校验和优化,确保了数据的高质量和多样性,为智能体性能的评估和优化提供了重要参考。
当前挑战
C^3-Bench面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,智能体需要处理复杂的工具依赖关系、长上下文信息依赖以及频繁的策略切换,这些任务对模型的鲁棒性和适应性提出了极高要求。在构建过程中,数据生成和校验的复杂性带来了显著挑战,包括确保多轮任务的逻辑一致性、覆盖所有可能的动作空间,以及通过人工校验提升数据准确性。此外,数据集的构建还需平衡多样性与质量,避免因模型生成任务的过于形式化而影响数据的真实性。
常用场景
经典使用场景
在大型语言模型(LLM)驱动的智能体研究中,C^3-Bench作为一个开源高质量基准测试,专注于评估智能体在多任务环境下的鲁棒性。该数据集通过设计复杂的工具关系导航、关键隐藏信息处理和动态决策路径管理三大挑战场景,为研究者提供了一个系统化的评估平台。其经典使用场景体现在对49种主流智能体的全面测试中,涵盖通用快速思考、慢速思考及领域专用模型,揭示了智能体在工具依赖性和长上下文信息处理等核心能力上的缺陷。
解决学术问题
C^3-Bench有效解决了智能体研究领域的关键学术问题:传统多轮对话评估忽视工具间关系、环境反馈等动态因素对智能体决策的影响。通过引入单变量分析方法和细粒度评估指标,该数据集首次实现了对智能体脆弱性的系统性诊断,尤其针对工具依赖链断裂、长程信息记忆失效和策略频繁切换等典型问题提供了量化分析框架,推动了智能体可解释性研究的发展。
实际应用
在实际应用层面,该数据集为智能体系统的工业落地提供了重要参考。其构建的可控多智能体数据生成框架支持双语任务生成,已应用于腾讯混元等商业模型的优化迭代。测试数据覆盖全部可能动作空间的特性,使其成为金融客服、智能家居等需要复杂工具调用的场景中,模型性能验证的黄金标准。数据经过五轮专家校验的严格质量把控,确保了评估结论对实际业务优化的指导价值。
数据集最近研究
最新研究方向
在大型语言模型(LLM)驱动的智能代理领域,C^3-Bench数据集的推出标志着对多任务环境下代理鲁棒性评估的突破性探索。该数据集通过整合工具依赖关系、隐藏信息处理及动态决策路径三大挑战,首次系统性地揭示了主流代理模型在复杂环境交互中的核心缺陷——49个测试模型在长上下文依赖和策略切换场景中普遍存在显著性能衰减。其创新的可控多代理数据生成框架支持双语任务构建,覆盖全动作空间的特性为智能代理的对抗性测试设立了新标准,尤其为医疗、金融等高可靠性需求领域的代理部署提供了关键安全评估范式。当前研究正基于该数据集探索代理决策可解释性,其细粒度指标体系已推动学术界对工具调用链失效模式的定量分析。
以上内容由遇见数据集搜集并总结生成


