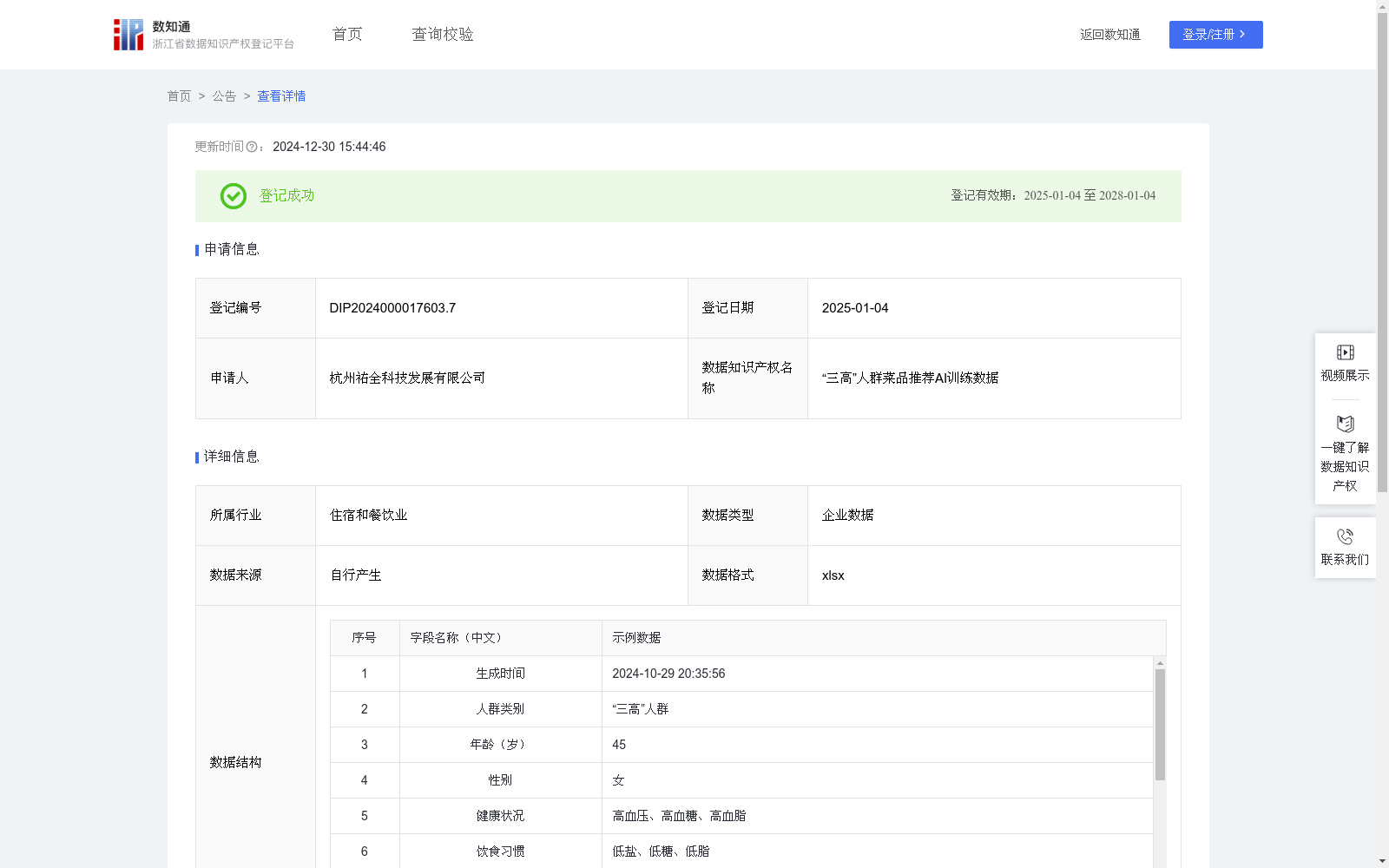
“三高”人群菜品推荐AI训练数据
收藏浙江省数据知识产权登记平台2024-12-30 更新2024-12-31 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/109345
下载链接
链接失效反馈官方服务:
资源简介:
“三高”人群菜品推荐AI训练数据的价值在于其为构建精准、高效的“三高”人群菜品推荐AI模型提供了丰富且具针对性的信息基础。这些数据覆盖了“三高”人群的关键特征,包括年龄、性别、健康状况和饮食习惯,使AI模型能够深入学习并掌握这些因素对菜品选择的影响。通过利用这些数据进行训练,AI模型能够更加准确地识别“三高”人群的营养需求和饮食限制,进而在实际应用中提供更加个性化的菜品推荐。这一训练过程的核心价值在于提升AI模型的预测精确度和适应能力,确保其在面对现实世界的复杂多变情况时,能够做出更加符合“三高”人群实际需求的决策。1.数据生成与预处理:使用Featuretools(一种特征生成工具)随机生成“三高”人群的特征信息,包括生成时间、人群类别、年龄、性别、健康状况、饮食习惯。通过数据清洗去除无效或错误记录,确保数据质量。
2.特征工程:跟据生成时间、年龄、性别、健康状况和饮食习惯,使用Feature-engine工具进行特征转换,生成特征标签。
3.菜品筛选:跟据特征标签,调用“三高”人群带量菜品知识库,运用SQL查询筛选出符合条件的推荐菜品。到此步骤为止,“三高”人群的特征信息、特征标签和推荐菜品共同构成训练集。
4.深度学习架构选择:采用深度交叉网络(DCN)作为深度学习架构。
5.模型训练:运用训练集对DCN模型进行训练。使用二元交叉熵损失函数来优化模型。采用Adam优化器进行参数更新。使用正则化技术(如L2正则化)来防止过拟合。
6.模型评估:使用准确率、召回率和F1分数来评估模型性能。通过交叉验证来评估模型的稳定性PSI。
The value of the AI training data for dish recommendation targeting the 'three highs' population lies in providing a rich and targeted information foundation for building an accurate and efficient AI dish recommendation model for this group. These data cover the key characteristics of the 'three highs' population, including age, gender, health status and dietary habits, enabling the AI model to deeply learn and grasp the impact of these factors on dish selection. By training with this data, the AI model can more accurately identify the nutritional needs and dietary restrictions of the 'three highs' population, thereby providing more personalized dish recommendations in practical applications. The core value of this training process is to improve the prediction accuracy and adaptability of the AI model, ensuring that it can make decisions that better meet the actual needs of the 'three highs' population when facing the complex and changing scenarios in the real world.
1. Data Generation and Preprocessing: Use Featuretools, a feature generation tool, to randomly generate feature information of the 'three highs' population, including generation time, population category, age, gender, health status and dietary habits. Remove invalid or erroneous records via data cleaning to ensure data quality.
2. Feature Engineering: Perform feature transformation using the Feature-engine tool based on the generation time, age, gender, health status and dietary habits to generate feature labels.
3. Dish Screening: Call the portion-controlled dish knowledge base for the 'three highs' population based on the feature labels, and use SQL queries to filter out eligible recommended dishes. Up to this step, the feature information, feature labels and recommended dishes of the 'three highs' population together constitute the training dataset.
4. Deep Learning Architecture Selection: Adopt the Deep & Cross Network (DCN) as the deep learning architecture.
5. Model Training: Train the DCN model using the training dataset. Use the binary cross-entropy loss function to optimize the model. Adopt the Adam optimizer for parameter update. Apply regularization techniques (such as L2 regularization) to prevent overfitting.
6. Model Evaluation: Evaluate model performance using accuracy, recall and F1-score. Assess the model's stability via the Population Stability Index (PSI) through cross-validation.
提供机构:
杭州祐全科技发展有限公司
创建时间:
2024-11-30
搜集汇总
数据集介绍
特点
该数据集为'三高'人群菜品推荐AI训练数据,包含557条记录,覆盖人群特征、饮食习惯及推荐菜品,并采用深度交叉网络(DCN)进行模型训练,评估指标表现优异。
以上内容由遇见数据集搜集并总结生成


