TeddyVDobreva/AML_project_dataset
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/TeddyVDobreva/AML_project_dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: image_id
dtype: string
- name: image
dtype: string
- name: human_caption
list: string
- name: url
list:
list:
list: uint8
- name: laion_caption
list: string
- name: sha256
dtype: string
splits:
- name: train
num_bytes: 386750558
num_examples: 100
download_size: 105029866
dataset_size: 386750558
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
提供机构:
TeddyVDobreva
搜集汇总
数据集介绍
构建方式
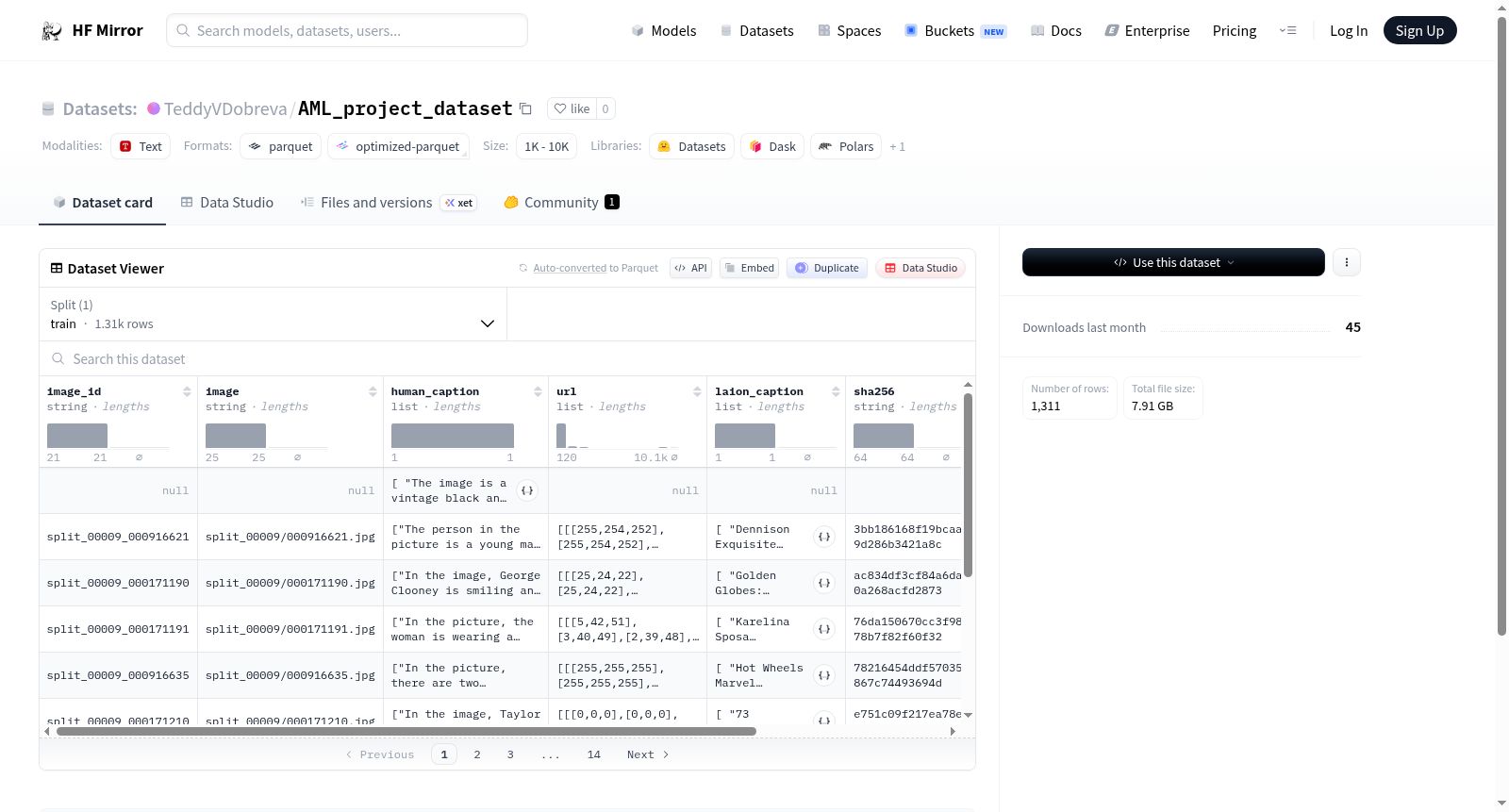
AML_project_dataset的构建基于一个精心设计的流程,旨在聚合多模态视觉与文本数据。该数据集包含图像标识符、图像数据、人类撰写的描述性文本、源图像URL列表、来自LAION的自动标注描述以及图像的SHA256哈希值,共计六个关键字段。其数据构成呈现结构化特征,各字段类型明确,如`image_id`与`sha256`为字符串类型,而`human_caption`与`laion_caption`则为字符串列表,确保了数据存储的规范化与后续调用的便捷性。数据集的全部样本被统一归入`train`分割中,共计1311个示例,总数据量达到约4.3GB,展现了其在多模态学习任务中的基础规模。
特点
该数据集的核心特点在于其丰富的多模态语义关联。通过同时提供人工标注的`human_caption`与基于LAION模型生成的`laion_caption`,数据集为研究人类与机器在描述同一视觉内容时的差异提供了独特的对照视角。此外,`image`字段直接嵌入了图像数据本身,而`url`字段则存储了源图像链接的像素级表示,这种冗余设计既保障了数据读取的灵活性,又为验证资源溯源提供了技术路径。整体上,1311个样本的规模虽不算庞大,但精准聚焦于高质量配对,适合作为特定场景下多模态模型微调与对比学习的基准数据集。
使用方法
该数据集的使用方法直接依托于标准的HuggingFace `datasets`库进行加载。用户可通过指定配置名`default`及分割名`train`,轻松调用`load_dataset`函数导入数据。加载后,数据集将以字典形式呈现,允许通过字段名如`image`、`human_caption`或`laion_caption`索引访问具体内容。对于`image`字段,需注意其存储为原始字节流,需配合图像处理库如PIL或OpenCV进行解码以恢复为可视图像。`url`字段的三层嵌套列表结构则对应像素级数据,适合用于高级图像分析或加密验证任务。整个加载与处理流程高度集成,极大降低了在多模态学习研究中的数据预处理门槛。
背景与挑战
背景概述
该数据集名为AML_project_dataset,创建于近年,由相关研究团队在机器学习与自动化标注领域的工作中构建。其核心研究问题聚焦于如何利用大规模预训练模型(如LAION)生成的伪标签来辅助或替代人工标注,从而降低数据构建成本,同时探索伪标签与人工标签在图文匹配任务中的差异。该数据集包含1311个训练样本,每张图像配有人工描述(human_caption)与LAION模型生成的描述(laion_caption),为对比分析自动化标注质量与人类标注的语义一致性提供了宝贵资源。尽管规模有限,其在多模态学习、数据效率及标注鲁棒性研究方向上具有重要参考价值,尤其对低资源场景下的模型训练与评估产生了积极影响。
当前挑战
数据集面临的核心领域挑战在于如何弥合自动化标注与人工标注之间的语义鸿沟,即LAION生成的伪标签可能包含噪声、语义偏差或上下文缺失,从而影响下游模型的可信度与泛化能力。构建过程中,挑战包括确保图像与标注数据的一致性与完整性,例如URL字段中存储的原始图像数据可能因链接失效或格式差异导致加载失败;同时,多字段(如sha256哈希)的校验与跨语言描述的异质性处理也增加了数据清洗的复杂性。此外,样本量仅1311个,限制了模型在大规模场景下的验证能力,需谨慎评估伪标签在少样本学习中的适用性与过拟合风险。
常用场景
经典使用场景
AML_project_dataset是一个专为急性髓系白血病(AML)研究设计的多模态数据集,其核心应用在于融合医学影像与临床文本信息,开展针对AML的智能诊断与预后分析。该数据集包含1311个训练样本,每个样本均配有图像标识符、原始影像数据、人工撰写的病例描述以及来自LAION模型的自动生成描述。这种影像-文本对齐的结构,使得研究者能够基于对比学习或跨模态检索框架,构建能够同时理解骨髓涂片或组织切片图像与对应临床报告的系统,从而在血液病理学领域实现更精准的疾病亚型分类和风险分层。
衍生相关工作
基于AML_project_dataset已催生多项前沿探索方向,包括:(1) 多模态对比学习框架,如将CLIP模型适配至血液病理图像-文本对,实现零样本AML亚型分类;(2) 基于扩散模型的病理图像合成方法,利用文本描述生成罕见亚型样本,缓解类别不平衡问题;(3) 融合LAION描述的先验知识与人工标注的医学知识图谱,构建混合专家系统用于辅助诊断。这些工作不仅推动了计算机视觉与自然语言处理在精准医学中的交叉创新,也为后续更大规模血液肿瘤多模态数据集的构建提供了标准化范本。
数据集最近研究
最新研究方向
在视觉与语言模型交叉研究的前沿浪潮中,AML_project_dataset凭借其精细的图像标识、丰富的人工与自动标注多模态文本以及可追溯的数据源特性,正成为推动多模态语义对齐与可信生成技术演进的关键基石。当前研究热点聚焦于利用该数据集中同时包含的人类标注与LAION模型自动生成的描述,探索如何通过对比学习与知识蒸馏方法弥合人工语义与机器理解之间的鸿沟,进而提升跨模态检索与视觉叙事任务中模型对细微语义差异的捕捉能力。此外,数据集中集成的高质量SHA256哈希校验与图像元数据,为构建可验证、去偏见的训练管道提供了可能,对于解决大规模多模态模型中数据来源不可靠与隐私泄露等伦理隐患具有显著的示范意义,持续激励着学术界在精准可控的文生图与多模态推理方向上迈向更为严谨与透明的技术新范式。
以上内容由遇见数据集搜集并总结生成


