ADL-X
收藏arXiv2024-06-14 更新2024-06-21 收录
下载链接:
https://adl-x.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
ADL-X是由北卡罗来纳大学夏洛特分校和英智†蔚蓝海岸大学合作创建的多视角RGBD指令ADL数据集,包含100,000个未修剪的RGB视频-指令对,3D姿态,语言描述和动作条件对象轨迹。该数据集通过新颖的半自动化框架生成,旨在训练大型语言视觉模型(LLVMs)以理解和预测日常生活中的活动。ADL-X的创建过程涉及从NTU RGB+D 120数据集中提取和处理视频,采用人物中心裁剪策略和动作序列随机组合,以捕捉ADL场景中的自然随机性。数据集的应用领域包括老年人护理监控、认知衰退评估和机器人辅助开发,旨在通过精确的时空关系理解和复杂的人机交互来解决现实世界中的问题。
ADL-X is a multi-view RGBD instruction ADL dataset co-developed by the University of North Carolina at Charlotte and Université Côte d'Azur. It contains 100,000 untrimmed RGB video-instruction pairs, 3D poses, linguistic descriptions, and action-conditioned object trajectories. Generated via a novel semi-automated framework, this dataset is designed to train Large Language-Vision Models (LLVMs) for understanding and predicting daily-life activities. The development process of ADL-X involves extracting and processing videos from the NTU RGB+D 120 dataset, adopting person-centric cropping strategies and random combinations of action sequences to capture the natural randomness in ADL scenarios. The application areas of this dataset include elder care monitoring, cognitive decline assessment, and robotic assistance development, aiming to solve real-world problems through accurate spatio-temporal relationship understanding and complex human-computer interaction.
提供机构:
北卡罗来纳大学夏洛特分校†英智†蔚蓝海岸大学
创建时间:
2024-06-14
搜集汇总
数据集介绍
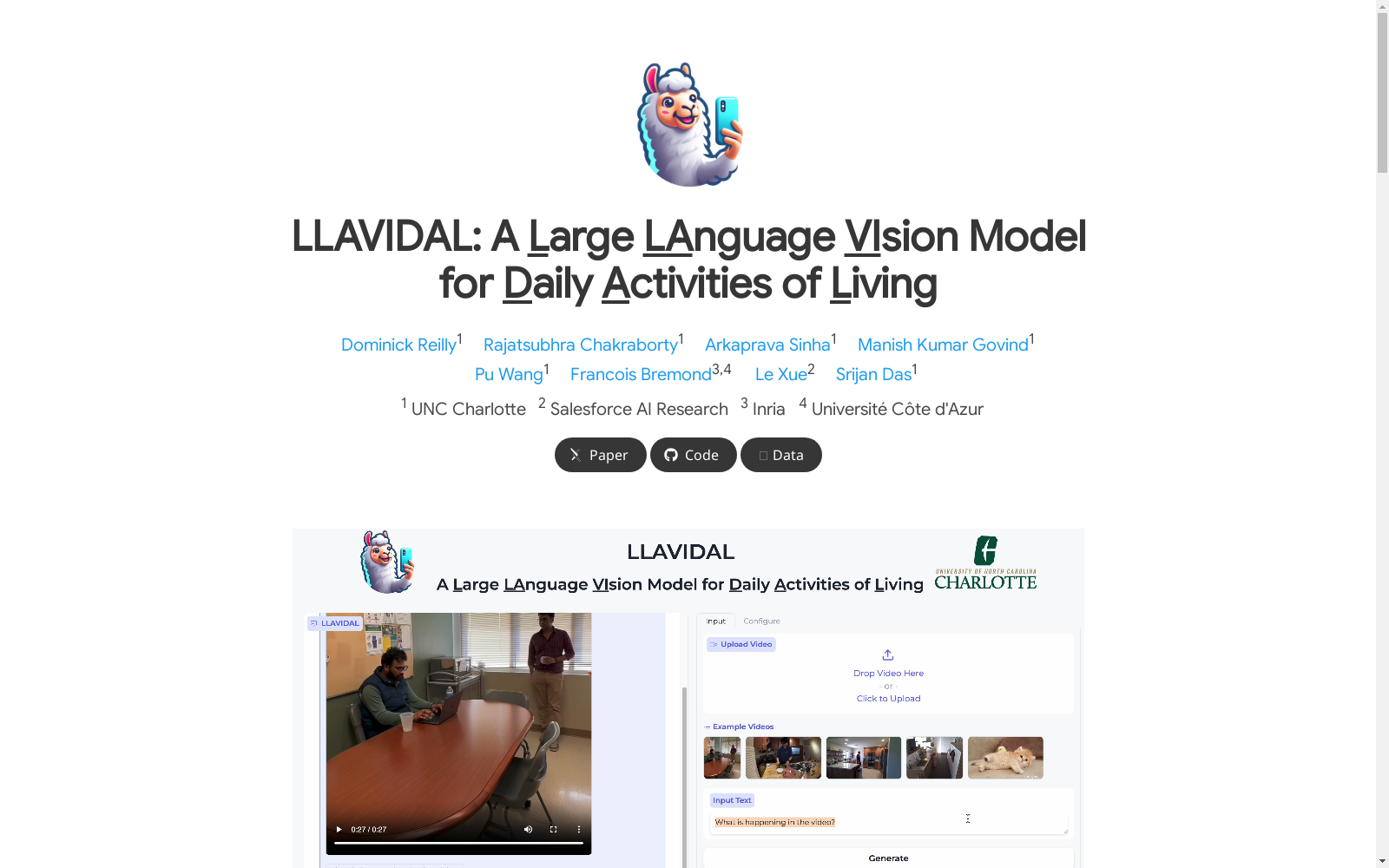
构建方式
在日常生活活动分析领域,现有数据集难以捕捉真实场景中的复杂时空关系。ADL-X数据集通过半自动化框架构建,以NTU RGB+D 120数据集为基础,采用人物中心裁剪策略消除背景干扰,并通过时序拼接技术生成包含随机动作序列的复合视频。利用CogVLM模型生成帧级描述,结合GPT-3.5 Turbo生成密集视频描述与多样化问答对,最终形成包含10万对视频指令的多模态数据集,涵盖RGB视频、3D姿态、语言描述与动作条件对象轨迹。
使用方法
该数据集专为大语言视觉模型的指令调优设计,研究人员可通过多模态融合策略将视频、姿态与对象线索整合至语言嵌入空间。具体使用时,首先提取视频的时空特征、姿态的语言上下文特征以及对象的轨迹特征,通过线性投影层将这些特征映射至LLM输入空间。训练阶段采用指令调优范式,将多模态特征与文本查询拼接后输入冻结的Vicuna语言解码器。评估时可使用配套的ADLMCQ基准测试,通过动作识别与动作预测的多选题任务客观衡量模型对日常生活活动的时序理解能力。
背景与挑战
背景概述
在计算机视觉与人工智能融合发展的浪潮中,理解人类日常生活活动(ADL)成为推动具身智能与健康辅助系统的关键。ADL-X数据集应运而生,由北卡罗来纳大学夏洛特分校、Inria及蔚蓝海岸大学的研究团队于2024年共同创建,旨在解决现有大规模语言视觉模型在解析ADL视频时面临的时空关系建模难题。该数据集包含10万对RGB视频-指令数据,并融合了三维人体姿态、语言描述及动作条件化物体轨迹等多模态信息,为模型提供了丰富的上下文线索。其核心研究问题聚焦于如何让模型精准捕捉ADL中细粒度动作、复杂人-物交互及非结构化时序动态,对老年健康监测、认知衰退评估及服务机器人等领域的智能化发展具有深远影响。
当前挑战
ADL-X数据集致力于解决日常生活活动视频理解这一核心领域问题,其挑战主要体现在模型需应对多外中心视角、细微动作差异、复杂人-物交互及长程时序依赖等复杂场景。在构建过程中,研究团队面临多重挑战:首先,从原始NTU RGB+D 120数据集中提取并拼接短视频片段时,需保持主体与视角的一致性,同时注入真实ADL固有的动作随机性以模拟非结构化流程;其次,通过半自动化框架生成高质量视频描述与问答对时,需利用CogVLM等模型进行人物中心裁剪以消除背景噪声,并依赖GPT-3.5进行动作条件化过滤与上下文增强,确保指令数据的精确性与多样性;此外,有效整合三维姿态与物体轨迹等多模态线索至语言嵌入空间,要求设计新颖的投影对齐策略,以克服异构特征融合带来的优化难题。
常用场景
经典使用场景
在计算机视觉与人工智能交叉领域,ADL-X数据集为大型语言视觉模型(LLVM)在日常生活活动理解中的指令微调提供了关键支撑。该数据集通过整合多视角RGB视频、三维人体姿态、语言描述及动作条件化物体轨迹,构建了丰富的视频-指令对,专门用于训练模型捕捉ADL场景中复杂的时空关系与细微动作变化。其经典应用场景在于为LLVM提供高质量、领域特定的训练数据,使模型能够深入解析如烹饪、清洁等日常活动中非结构化、并发性的动作序列,从而提升对真实世界动态的理解能力。
解决学术问题
ADL-X数据集有效应对了现有LLVM在理解日常生活活动时面临的若干核心学术挑战。传统模型通常基于网络视频训练,难以处理ADL中存在的多视角、细粒度动作及复杂人-物交互问题。该数据集通过提供带有时序随机性的合成动作序列、三维姿态信息以及物体轨迹,使研究者能够探索如何将人体运动学与物体语义融入语言模型嵌入空间。这解决了模型在ADL场景中时空推理能力不足、对细微动作敏感度低以及缺乏视点不变性表示等关键问题,为构建更鲁棒、更贴近实际应用的视频理解系统奠定了数据基础。
实际应用
在实际应用层面,ADL-X数据集及其衍生的LLAVIDAL模型在智能健康监护、老年照护与辅助机器人等领域展现出显著价值。模型能够通过视频分析自动识别日常活动中的异常行为,如跌倒预警、认知衰退评估,或为行动不便者提供实时活动辅助指导。在智能家居环境中,该系统可理解居民与家电的交互意图,实现更自然的场景化服务。此外,在康复训练与远程医疗中,模型能生成详细的活动报告,帮助医护人员量化评估患者的日常功能状态,推动个性化护理方案的制定与优化。
数据集最近研究
最新研究方向
在计算机视觉与人工智能领域,ADL-X数据集的推出标志着对日常生活活动理解研究的重要进展。该数据集通过整合多视角RGB视频、三维姿态、语言描述及动作条件对象轨迹,为大型语言视觉模型提供了针对ADL场景的精细化训练资源。前沿研究聚焦于如何有效融合三维姿态与对象交互线索,以提升模型在复杂时空关系中的推理能力。热点方向包括利用半自动化框架生成视频指令对,以及开发如LLAVIDAL的专用模型,这些模型通过将姿态与对象特征投影至语言嵌入空间,显著增强了在ADL多选问答基准上的性能。这一进展对老年健康监测、认知评估及辅助机器人等应用具有深远意义,推动了多模态智能系统向更细腻、更人性化的理解方向发展。
相关研究论文
- 1LLAVIDAL: Benchmarking Large Language Vision Models for Daily Activities of Living北卡罗来纳大学夏洛特分校†英智†蔚蓝海岸大学 · 2024年
以上内容由遇见数据集搜集并总结生成


