SyntheticGenV5
收藏SyntheticGenV5 数据集概述
数据集基本信息
- 数据集名称: SyntheticGenV5
- 许可证: MIT
- 主要任务类别: 图像分割
- 具体任务: 语义分割
- 标签: 遥感、语义分割、合成数据、领域自适应、图像
- 数据规模: 1K<n<10K
- 配置名称: default
数据集简介
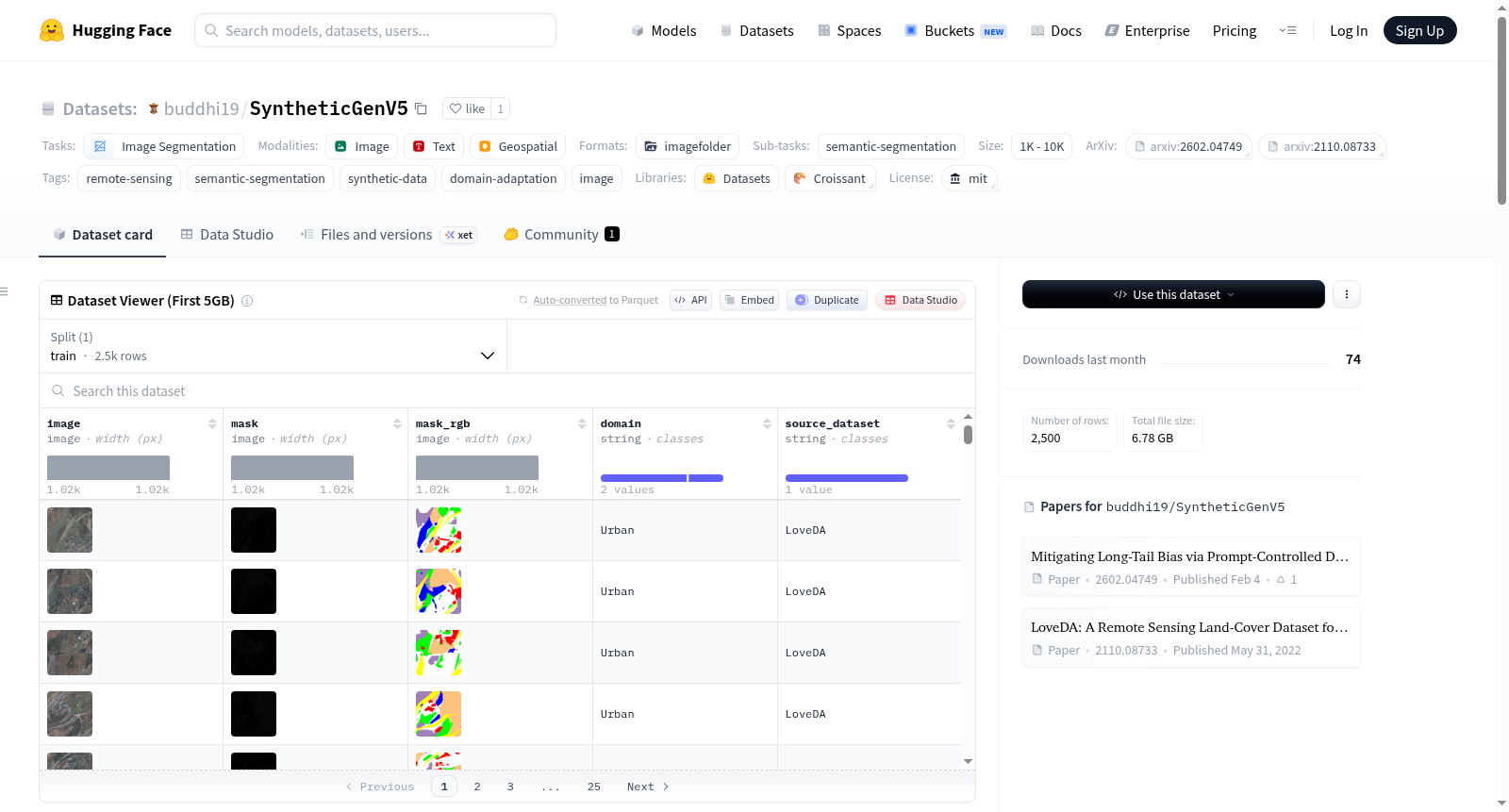
SyntheticGenV5 是一个用于城市-乡村领域感知学习的合成遥感语义分割数据集。该数据集基于论文 https://huggingface.co/papers/2602.04749 构建。它保持了原始文件夹布局,并使用 Train/metadata.csv 文件来关联每张图像与其语义分割掩码和 RGB 掩码。
数据集特点与用途
- 包含两个领域: 城市和乡村
- 设计用途: 专为遥感语义分割设计
- 应用场景: 适用于合成数据增强和领域泛化研究
- 辅助功能: 包含 RGB 掩码可视化,便于检查
数据结构
数据集遵循以下目录结构:
Train/ ├── metadata.csv ├── Urban/ │ ├── image_png/ │ ├── mask_png/ │ └── mask_rgb_png/ └── Rural/ ├── image_png/ ├── mask_png/ └── mask_rgb_png/
元数据字段
Train/metadata.csv 文件中的每一行包含以下字段:
image_file_namemask_file_namemask_rgb_file_namedomainsource_dataset
数据加载方式
python from datasets import load_dataset ds = load_dataset("buddhi19/SyntheticGenV5") print(ds["train"][0])
数据来源
该数据集衍生或生成自 LoveDA 数据集: LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation
引用信息
LoveDA 数据集引用
bibtex @misc{wang2022lovedaremotesensinglandcover, title={LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation}, author={Junjue Wang and Zhuo Zheng and Ailong Ma and Xiaoyan Lu and Yanfei Zhong}, year={2022}, eprint={2110.08733}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2110.08733}, }
SyntheticGenV5 及相关论文引用
bibtex @misc{wijenayake2026mitigating, title={Mitigating Long-Tail Bias via Prompt-Controlled Diffusion Augmentation}, author={Buddhi Wijenayake and Nichula Wasalathilake and Roshan Godaliyadda and Vijitha Herath and Parakrama Ekanayake and Vishal M. Patel}, year={2026}, eprint={2602.04749}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2602.04749} }
重要说明
- 原始目录布局被保留
Train/metadata.csv用于在 Hugging Face 上更清晰地加载数据- 包含 RGB 掩码主要用于可视化
- 当前版本仅包含
train分割
致谢
感谢 LoveDA 作者提供的原始基准数据集,该数据集启发并支持了本数据集的创建。