sjleslie/MGEN_StrippedQs_B_split_slimpj_context_len_2__bs008
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/sjleslie/MGEN_StrippedQs_B_split_slimpj_context_len_2__bs008
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 20195949
num_examples: 54844
download_size: 12885846
dataset_size: 20195949
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
提供机构:
sjleslie
搜集汇总
数据集介绍
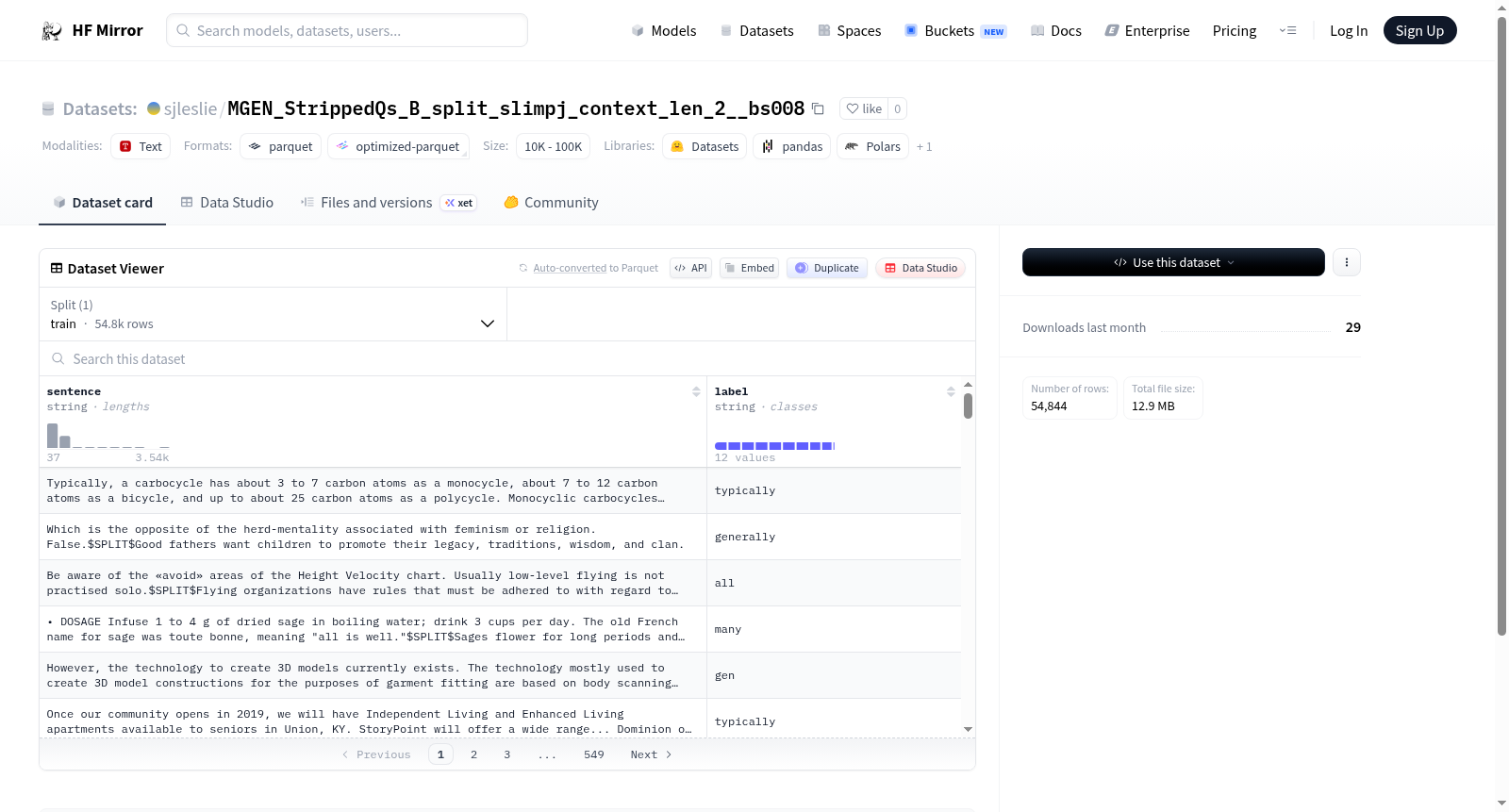
构建方式
在自然语言处理领域,文本分类任务对高质量标注数据的需求日益增长。该数据集通过精心设计的预处理流程构建而成,原始文本经过清洗与标准化处理,去除无关噪声并统一格式。随后采用自动化标注机制,依据特定分类体系为每个句子分配相应标签,确保标注的一致性与准确性。数据划分遵循机器学习常规实践,将全部样本整合为单一训练集,便于模型直接进行学习与优化。
特点
该数据集聚焦于句子级别的文本分类,其结构简洁而明确,仅包含句子文本与对应标签两个核心特征。数据规模适中,涵盖数万个标注样本,为模型训练提供了充足的基础。特征设计去除了冗余信息,使研究者能够专注于文本语义与分类关系的探索。这种精炼的数据组织形式,既降低了处理复杂度,也提升了在有限计算资源下的实验效率。
使用方法
研究者可通过HuggingFace数据集库直接加载该数据集,其标准化的接口确保了使用的便捷性。加载后,数据以常见的字典格式呈现,可直接用于训练各类文本分类模型,如基于Transformer的预训练语言模型。由于数据集仅提供训练分割,用户需自行划分验证集以监控训练过程,或结合其他独立测试集评估模型泛化性能。这种设计赋予了使用者在实验流程上更大的灵活性。
背景与挑战
背景概述
在自然语言处理领域,文本分类任务一直是核心研究方向之一,旨在通过机器学习模型自动识别和归类文本内容。数据集MGEN_StrippedQs_B_split_slimpj_context_len_2__bs008的创建,反映了近年来对高效、结构化文本数据的需求增长,以支持模型在特定上下文环境下的精准分类。该数据集由相关研究机构或团队构建,专注于解决文本句子与标签之间的映射问题,通过提供大量标注样本,推动分类算法在复杂语言场景中的泛化能力,对提升自动化文本分析系统的性能具有潜在影响力。
当前挑战
该数据集旨在应对文本分类任务中的核心挑战,即如何在有限上下文长度内准确捕捉句子语义,并实现高精度标签预测,这涉及处理语言歧义和类别不平衡问题。在构建过程中,挑战包括数据清洗与标准化,确保句子和标签格式的一致性,以及通过分割和采样策略优化数据分布,以平衡计算效率与模型训练效果,避免过拟合或欠拟合现象。
常用场景
经典使用场景
在自然语言处理领域,文本分类任务常需处理大规模、多样化的句子数据。该数据集以其结构化的句子与标签对,为监督学习模型提供了精准的训练基础。经典使用场景包括构建分类器,对输入句子进行多类别标签预测,广泛应用于情感分析、主题分类等下游任务中,助力模型理解语言语义并实现自动化标注。
实际应用
在实际应用中,该数据集可服务于智能客服系统,用于自动识别用户查询意图并分类响应;在内容审核平台中,辅助检测不当言论或垃圾信息。其结构化数据有助于企业构建高效的文本处理流水线,提升自动化水平,降低人工成本,并在社交媒体分析、新闻分类等场景中发挥关键作用。
衍生相关工作
基于该数据集,衍生出多项经典研究工作,包括改进的文本分类模型架构如BERT变体的微调实验,以及半监督学习方法的创新应用。这些工作进一步拓展了数据集在跨领域迁移学习、少样本学习中的潜力,为自然语言处理社区贡献了丰富的算法比较与性能优化案例。
以上内容由遇见数据集搜集并总结生成


