---
annotations_creators:
- machine-generated
language_creators:
- found
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories: []
source_datasets:
- original
task_categories:
- image-to-image
- text-to-image
- unconditional-image-generation
task_ids: []
pretty_name: Magazine
tags:
- graphic design
- layout
- content-aware
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: filename
dtype: string
- name: category
dtype:
class_label:
names:
'0': fashion
'1': food
'2': news
'3': science
'4': travel
'5': wedding
- name: size
struct:
- name: width
dtype: int64
- name: height
dtype: int64
- name: elements
sequence:
- name: label
dtype:
class_label:
names:
'0': text
'1': image
'2': headline
'3': text-over-image
'4': headline-over-image
- name: polygon_x
sequence: float32
- name: polygon_y
sequence: float32
- name: keywords
sequence: string
- name: images
sequence: image
splits:
- name: train
num_bytes: 4655342211.434
num_examples: 3919
download_size: 4652903538
dataset_size: 4655342211.434
---
# Dataset Card for Magazine dataset
[](https://github.com/shunk031/huggingface-datasets_Magazine/actions/workflows/ci.yaml)
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://xtqiao.com/projects/content_aware_layout/
- **Repository:** https://github.com/shunk031/huggingface-datasets_Magazine
- **Paper (SIGGRAPH2019):** https://dl.acm.org/doi/10.1145/3306346.3322971
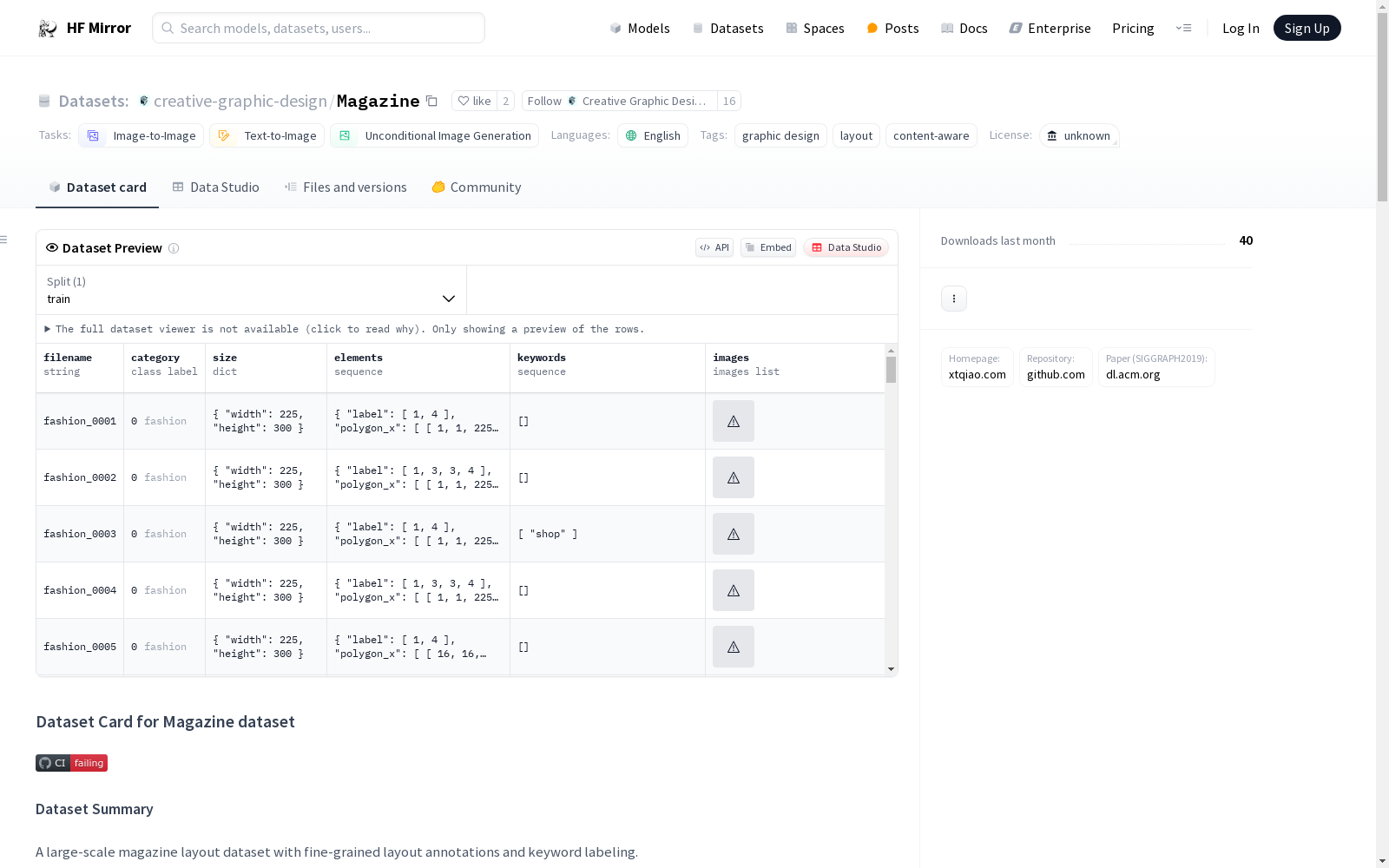
### Dataset Summary
A large-scale magazine layout dataset with fine-grained layout annotations and keyword labeling.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
<!-- To use Magazine dataset, you need to download the image and layout annotations from the [OneDrive](https://portland-my.sharepoint.com/:f:/g/personal/xqiao6-c_my_cityu_edu_hk/EhmRh5SFoQ9Hjl_aRjCOltkBKFYefiSagR6QLJ7pWvs3Ww?e=y8HO5Q) in the [official page](https://xtqiao.com/projects/content_aware_layout/).
Then place the downloaded files in the following structure and specify its path.
```shell
/path/to/datasets
├── MagImage.zip
└── MagLayout.zip
```
```python
import datasets as ds
dataset = ds.load_dataset(
path="shunk031/Magazine",
data_dir="/path/to/datasets/", # Specify the path of the downloaded directory.
)
``` -->
```python
import datasets as ds
dataset = ds.load_dataset("creative-graphic-design/Magazine")
```
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
[More Information Needed]
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
[More Information Needed]
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
```
Copyright (c) 2019, Xiaotian Qiao
All rights reserved.
This code is copyrighted by the authors and is for non-commercial research
purposes only.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
```
### Citation Information
```bibtex
@article{zheng2019content,
title={Content-aware generative modeling of graphic design layouts},
author={Zheng, Xinru and Qiao, Xiaotian and Cao, Ying and Lau, Rynson WH},
journal={ACM Transactions on Graphics (TOG)},
volume={38},
number={4},
pages={1--15},
year={2019},
publisher={ACM New York, NY, USA}
}
```
### Contributions
Thanks to [Xinru Zheng and Xiaotian Qiao](https://xtqiao.com/projects/content_aware_layout/) for creating this dataset.
annotations_creators:
- 机器生成
language_creators:
- 采集所得
language:
- 英语
license:
- 未知
multilinguality:
- 单语言
size_categories: []
source_datasets:
- 原始数据集
task_categories:
- 图像到图像(image-to-image)
- 文本到图像(text-to-image)
- 无条件图像生成(unconditional-image-generation)
task_ids: []
pretty_name: 杂志(Magazine)
tags:
- 平面设计(graphic design)
- 版面布局(layout)
- 内容感知(content-aware)
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: filename
dtype: 字符串(string)
- name: category
dtype:
类标签(class_label):
命名项:
'0': 时尚(fashion)
'1': 食品(food)
'2': 新闻(news)
'3': 科学(science)
'4': 旅游(travel)
'5': 婚礼(wedding)
- name: size
结构体(struct):
- name: width
dtype: 64位整数(int64)
- name: height
dtype: 64位整数(int64)
- name: elements
序列(sequence):
- name: label
dtype:
类标签(class_label):
命名项:
'0': 文本(text)
'1': 图像(image)
'2': 标题(headline)
'3': 图像上文本(text-over-image)
'4': 图像上标题(headline-over-image)
- name: polygon_x
序列(sequence): 32位浮点数(float32)
- name: polygon_y
序列(sequence): 32位浮点数(float32)
- name: keywords
序列(sequence): 字符串(string)
- name: images
序列(sequence): 图像(image)
splits:
- name: train
num_bytes: 4655342211.434
num_examples: 3919
download_size: 4652903538
dataset_size: 4655342211.434
# Magazine数据集卡片
[](https://github.com/shunk031/huggingface-datasets_Magazine/actions/workflows/ci.yaml)
## 目录
- [数据集卡片制作指南](#数据集卡片制作指南)
- [目录](#目录)
- [数据集概述](#数据集概述)
- [数据集总结](#数据集总结)
- [支持任务与基准测试榜单](#支持任务与基准测试榜单)
- [使用语言](#使用语言)
- [数据集结构](#数据集结构)
- [数据实例](#数据实例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集创建](#数据集创建)
- [数据集构建初衷](#数据集构建初衷)
- [源数据](#源数据)
- [初始数据收集与标准化](#初始数据收集与标准化)
- [源语言生产者是谁?](#源语言生产者是谁?)
- [标注信息](#标注信息)
- [标注流程](#标注流程)
- [标注者是谁?](#标注者是谁?)
- [个人与敏感信息](#个人与敏感信息)
- [数据集使用注意事项](#数据集使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏差讨论](#偏差讨论)
- [其他已知局限性](#其他已知局限性)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [许可信息](#许可信息)
- [引用信息](#引用信息)
- [贡献](#贡献)
## 数据集概述
- **主页:** https://xtqiao.com/projects/content_aware_layout/
- **代码仓库:** https://github.com/shunk031/huggingface-datasets_Magazine
- **论文(SIGGRAPH2019):** https://dl.acm.org/doi/10.1145/3306346.3322971
### 数据集总结
该数据集为大规模杂志版面布局数据集,包含细粒度版面布局标注与关键词标注。
### 支持任务与基准测试榜单
[需补充更多信息]
### 使用语言
[需补充更多信息]
## 数据集结构
### 数据实例
若要使用Magazine数据集,需从官方页面[https://xtqiao.com/projects/content_aware_layout/]的OneDrive链接下载图像与布局标注文件,随后将下载的文件按如下结构放置,并指定其路径。
shell
/path/to/datasets
├── MagImage.zip
└── MagLayout.zip
python
import datasets as ds
dataset = ds.load_dataset(
path="shunk031/Magazine",
data_dir="/path/to/datasets/", # 指定下载数据集所在目录的路径。
)
也可使用如下代码加载:
python
import datasets as ds
dataset = ds.load_dataset("creative-graphic-design/Magazine")
### 数据字段
[需补充更多信息]
### 数据划分
[需补充更多信息]
## 数据集创建
### 数据集构建初衷
[需补充更多信息]
### 源数据
[需补充更多信息]
#### 初始数据收集与标准化
[需补充更多信息]
#### 源语言生产者是谁?
[需补充更多信息]
### 标注信息
[需补充更多信息]
#### 标注流程
[需补充更多信息]
#### 标注者是谁?
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据集使用注意事项
### 数据集的社会影响
[需补充更多信息]
### 偏差讨论
[需补充更多信息]
### 其他已知局限性
[需补充更多信息]
## 附加信息
### 数据集维护者
[需补充更多信息]
### 许可信息
Copyright (c) 2019, Xiaotian Qiao
保留所有权利。
本代码受作者版权保护,仅可用于非商业性研究用途。
无论是否对源代码进行修改,以源代码或二进制形式再分发和使用本软件,均需满足以下条件:
* 源代码的再分发必须保留上述版权声明、本条件列表以及如下免责声明。
* 二进制形式的再分发必须在随附的文档和/或其他材料中复制上述版权声明、本条件列表以及如下免责声明。
本软件由版权持有者和贡献者“按原样”提供,不附带任何明示或默示的担保,包括但不限于适销性和特定用途适用性的默示担保。在任何情况下,版权持有者或贡献者均不对任何直接、间接、附带、特殊、惩戒性或间接损害(包括但不限于替代商品或服务的采购、使用、数据或利润损失,或业务中断)承担责任,无论该责任源于合同、严格责任或侵权(包括疏忽或其他),无论是否事先知晓该损害的可能性。
### 引用信息
bibtex
@article{zheng2019content,
title={Content-aware generative modeling of graphic design layouts},
author={Zheng, Xinru and Qiao, Xiaotian and Cao, Ying and Lau, Rynson WH},
journal={ACM Transactions on Graphics (TOG)},
volume={38},
number={4},
pages={1--15},
year={2019},
publisher={ACM New York, NY, USA}
}
### 贡献
感谢[Xinru Zheng与Xiaotian Qiao](https://xtqiao.com/projects/content_aware_layout/)创建本数据集。