ehovy/race
收藏Hugging Face2024-01-04 更新2024-04-20 收录
下载链接:
https://hf-mirror.com/datasets/ehovy/race
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- multiple-choice
task_ids:
- multiple-choice-qa
paperswithcode_id: race
pretty_name: RACE
dataset_info:
- config_name: all
features:
- name: example_id
dtype: string
- name: article
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: options
sequence: string
splits:
- name: test
num_bytes: 8775370
num_examples: 4934
- name: train
num_bytes: 157308478
num_examples: 87866
- name: validation
num_bytes: 8647176
num_examples: 4887
download_size: 41500647
dataset_size: 174731024
- config_name: high
features:
- name: example_id
dtype: string
- name: article
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: options
sequence: string
splits:
- name: test
num_bytes: 6989097
num_examples: 3498
- name: train
num_bytes: 126243228
num_examples: 62445
- name: validation
num_bytes: 6885263
num_examples: 3451
download_size: 33750880
dataset_size: 140117588
- config_name: middle
features:
- name: example_id
dtype: string
- name: article
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: options
sequence: string
splits:
- name: test
num_bytes: 1786273
num_examples: 1436
- name: train
num_bytes: 31065250
num_examples: 25421
- name: validation
num_bytes: 1761913
num_examples: 1436
download_size: 7781596
dataset_size: 34613436
configs:
- config_name: all
data_files:
- split: test
path: all/test-*
- split: train
path: all/train-*
- split: validation
path: all/validation-*
- config_name: high
data_files:
- split: test
path: high/test-*
- split: train
path: high/train-*
- split: validation
path: high/validation-*
- config_name: middle
data_files:
- split: test
path: middle/test-*
- split: train
path: middle/train-*
- split: validation
path: middle/validation-*
---
# Dataset Card for "race"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [http://www.cs.cmu.edu/~glai1/data/race/](http://www.cs.cmu.edu/~glai1/data/race/)
- **Repository:** https://github.com/qizhex/RACE_AR_baselines
- **Paper:** [RACE: Large-scale ReAding Comprehension Dataset From Examinations](https://arxiv.org/abs/1704.04683)
- **Point of Contact:** [Guokun Lai](mailto:guokun@cs.cmu.edu), [Qizhe Xie](mailto:qzxie@cs.cmu.edu)
- **Size of downloaded dataset files:** 76.33 MB
- **Size of the generated dataset:** 349.46 MB
- **Total amount of disk used:** 425.80 MB
### Dataset Summary
RACE is a large-scale reading comprehension dataset with more than 28,000 passages and nearly 100,000 questions. The
dataset is collected from English examinations in China, which are designed for middle school and high school students.
The dataset can be served as the training and test sets for machine comprehension.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### all
- **Size of downloaded dataset files:** 25.44 MB
- **Size of the generated dataset:** 174.73 MB
- **Total amount of disk used:** 200.17 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answer": "A",
"article": "\"Schoolgirls have been wearing such short skirts at Paget High School in Branston that they've been ordered to wear trousers ins...",
"example_id": "high132.txt",
"options": ["short skirts give people the impression of sexualisation", "short skirts are too expensive for parents to afford", "the headmaster doesn't like girls wearing short skirts", "the girls wearing short skirts will be at the risk of being laughed at"],
"question": "The girls at Paget High School are not allowed to wear skirts in that _ ."
}
```
#### high
- **Size of downloaded dataset files:** 25.44 MB
- **Size of the generated dataset:** 140.12 MB
- **Total amount of disk used:** 165.56 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answer": "A",
"article": "\"Schoolgirls have been wearing such short skirts at Paget High School in Branston that they've been ordered to wear trousers ins...",
"example_id": "high132.txt",
"options": ["short skirts give people the impression of sexualisation", "short skirts are too expensive for parents to afford", "the headmaster doesn't like girls wearing short skirts", "the girls wearing short skirts will be at the risk of being laughed at"],
"question": "The girls at Paget High School are not allowed to wear skirts in that _ ."
}
```
#### middle
- **Size of downloaded dataset files:** 25.44 MB
- **Size of the generated dataset:** 34.61 MB
- **Total amount of disk used:** 60.05 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answer": "B",
"article": "\"There is not enough oil in the world now. As time goes by, it becomes less and less, so what are we going to do when it runs ou...",
"example_id": "middle3.txt",
"options": ["There is more petroleum than we can use now.", "Trees are needed for some other things besides making gas.", "We got electricity from ocean tides in the old days.", "Gas wasn't used to run cars in the Second World War."],
"question": "According to the passage, which of the following statements is TRUE?"
}
```
### Data Fields
The data fields are the same among all splits.
#### all
- `example_id`: a `string` feature.
- `article`: a `string` feature.
- `answer`: a `string` feature.
- `question`: a `string` feature.
- `options`: a `list` of `string` features.
#### high
- `example_id`: a `string` feature.
- `article`: a `string` feature.
- `answer`: a `string` feature.
- `question`: a `string` feature.
- `options`: a `list` of `string` features.
#### middle
- `example_id`: a `string` feature.
- `article`: a `string` feature.
- `answer`: a `string` feature.
- `question`: a `string` feature.
- `options`: a `list` of `string` features.
### Data Splits
| name |train|validation|test|
|------|----:|---------:|---:|
|all |87866| 4887|4934|
|high |62445| 3451|3498|
|middle|25421| 1436|1436|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
http://www.cs.cmu.edu/~glai1/data/race/
1. RACE dataset is available for non-commercial research purpose only.
2. All passages are obtained from the Internet which is not property of Carnegie Mellon University. We are not responsible for the content nor the meaning of these passages.
3. You agree not to reproduce, duplicate, copy, sell, trade, resell or exploit for any commercial purpose, any portion of the contexts and any portion of derived data.
4. We reserve the right to terminate your access to the RACE dataset at any time.
### Citation Information
```
@inproceedings{lai-etal-2017-race,
title = "{RACE}: Large-scale {R}e{A}ding Comprehension Dataset From Examinations",
author = "Lai, Guokun and
Xie, Qizhe and
Liu, Hanxiao and
Yang, Yiming and
Hovy, Eduard",
booktitle = "Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing",
month = sep,
year = "2017",
address = "Copenhagen, Denmark",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D17-1082",
doi = "10.18653/v1/D17-1082",
pages = "785--794",
}
```
### Contributions
Thanks to [@abarbosa94](https://github.com/abarbosa94), [@patrickvonplaten](https://github.com/patrickvonplaten), [@lewtun](https://github.com/lewtun), [@thomwolf](https://github.com/thomwolf), [@mariamabarham](https://github.com/mariamabarham) for adding this dataset.
annotations_creators:
- 专家生成
language_creators:
- 现有文本采集
language:
- en
license:
- 其他
multilinguality:
- 单语
size_categories:
- 10K<n<100K
source_datasets:
- 原创数据集
task_categories:
- 多项选择
task_ids:
- 多项选择问答
paperswithcode_id: race
pretty_name: RACE
dataset_info:
- config_name: all
features:
- name: example_id
dtype: string
- name: article
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: options
sequence: string
splits:
- name: test
num_bytes: 8775370
num_examples: 4934
- name: train
num_bytes: 157308478
num_examples: 87866
- name: validation
num_bytes: 8647176
num_examples: 4887
download_size: 41500647
dataset_size: 174731024
- config_name: high
features:
- name: example_id
dtype: string
- name: article
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: options
sequence: string
splits:
- name: test
num_bytes: 6989097
num_examples: 3498
- name: train
num_bytes: 126243228
num_examples: 62445
- name: validation
num_bytes: 6885263
num_examples: 3451
download_size: 33750880
dataset_size: 140117588
- config_name: middle
features:
- name: example_id
dtype: string
- name: article
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: options
sequence: string
splits:
- name: test
num_bytes: 1786273
num_examples: 1436
- name: train
num_bytes: 31065250
num_examples: 25421
- name: validation
num_bytes: 1761913
num_examples: 1436
download_size: 7781596
dataset_size: 34613436
configs:
- config_name: all
data_files:
- split: test
path: all/test-*
- split: train
path: all/train-*
- split: validation
path: all/validation-*
- config_name: high
data_files:
- split: test
path: high/test-*
- split: train
path: high/train-*
- split: validation
path: high/validation-*
- config_name: middle
data_files:
- split: test
path: middle/test-*
- split: train
path: middle/train-*
- split: validation
path: middle/validation-*
# 数据集卡片:"RACE"
## 目录
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与排行榜](#支持任务与排行榜)
- [语言](#语言)
- [数据集结构](#数据集结构)
- [数据实例](#数据实例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [构建初衷](#构建初衷)
- [源数据](#源数据)
- [注释](#注释)
- [个人与敏感信息](#个人与敏感信息)
- [数据使用注意事项](#数据使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏差讨论](#偏差讨论)
- [其他已知局限性](#其他已知局限性)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [许可证信息](#许可证信息)
- [引用信息](#引用信息)
- [贡献者](#贡献者)
## 数据集描述
- **主页:** [http://www.cs.cmu.edu/~glai1/data/race/](http://www.cs.cmu.edu/~glai1/data/race/)
- **代码仓库:** https://github.com/qizhex/RACE_AR_baselines
- **相关论文:** [RACE: 考试来源的大规模阅读理解数据集](https://arxiv.org/abs/1704.04683)
- **联系人:** [赖国坤](mailto:guokun@cs.cmu.edu), [谢奇哲](mailto:qzxie@cs.cmu.edu)
- **下载数据集文件大小:** 76.33 MB
- **生成后数据集大小:** 349.46 MB
- **总磁盘占用:** 425.80 MB
### 数据集概述
RACE是一款大规模阅读理解数据集,包含超过28000个文本段落与近100000道问题。该数据集采集自中国面向中学生与高中生的英语考试,可作为机器阅读理解任务的训练集与测试集使用。
### 支持任务与排行榜
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集结构
### 数据实例
#### all配置
- **下载数据集文件大小:** 25.44 MB
- **生成后数据集大小:** 174.73 MB
- **总磁盘占用:** 200.17 MB
训练集的一个示例格式如下:
该示例过长已被截断:
{
"answer": "A",
"article": ""Schoolgirls have been wearing such short skirts at Paget High School in Branston that they've been ordered to wear trousers ins...",
"example_id": "high132.txt",
"options": ["short skirts give people the impression of sexualisation", "short skirts are too expensive for parents to afford", "the headmaster doesn't like girls wearing short skirts", "the girls wearing short skirts will be at the risk of being laughed at"],
"question": "The girls at Paget High School are not allowed to wear skirts in that _ ."
}
#### high配置(高中版)
- **下载数据集文件大小:** 25.44 MB
- **生成后数据集大小:** 140.12 MB
- **总磁盘占用:** 165.56 MB
训练集的一个示例格式如下:
该示例过长已被截断:
{
"answer": "A",
"article": ""Schoolgirls have been wearing such short skirts at Paget High School in Branston that they've been ordered to wear trousers ins...",
"example_id": "high132.txt",
"options": ["short skirts give people the impression of sexualisation", "short skirts are too expensive for parents to afford", "the headmaster doesn't like girls wearing short skirts", "the girls wearing short skirts will be at the risk of being laughed at"],
"question": "The girls at Paget High School are not allowed to wear skirts in that _ ."
}
#### middle配置(中学版)
- **下载数据集文件大小:** 25.44 MB
- **生成后数据集大小:** 34.61 MB
- **总磁盘占用:** 60.05 MB
训练集的一个示例格式如下:
该示例过长已被截断:
{
"answer": "B",
"article": ""There is not enough oil in the world now. As time goes by, it becomes less and less, so what are we going to do when it runs ou...",
"example_id": "middle3.txt",
"options": ["There is more petroleum than we can use now.", "Trees are needed for some other things besides making gas.", "We got electricity from ocean tides in the old days.", "Gas wasn't used to run cars in the Second World War."],
"question": "According to the passage, which of the following statements is TRUE?"
}
### 数据字段
所有划分下的数据字段均一致:
#### all配置
- `example_id`: 字符串类型字段,即示例ID
- `article`: 字符串类型字段,即阅读文本段落
- `answer`: 字符串类型字段,即正确答案
- `question`: 字符串类型字段,即问题
- `options`: 字符串列表类型字段,即候选选项
#### high配置
- `example_id`: 字符串类型字段,即示例ID
- `article`: 字符串类型字段,即阅读文本段落
- `answer`: 字符串类型字段,即正确答案
- `question`: 字符串类型字段,即问题
- `options`: 字符串列表类型字段,即候选选项
#### middle配置
- `example_id`: 字符串类型字段,即示例ID
- `article`: 字符串类型字段,即阅读文本段落
- `answer`: 字符串类型字段,即正确答案
- `question`: 字符串类型字段,即问题
- `options`: 字符串列表类型字段,即候选选项
### 数据划分
| 配置名称 | 训练集样本数 | 验证集样本数 | 测试集样本数 |
|---------|-------------:|------------:|-------------:|
| all | 87866 | 4887 | 4934 |
| high | 62445 | 3451 | 3498 |
| middle | 25421 | 1436 | 1436 |
## 数据集构建
### 构建初衷
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据采集与标准化
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言生产者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 注释
#### 注释流程
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 注释者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据使用注意事项
### 数据集的社会影响
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏差讨论
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限性
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集维护者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 许可证信息
http://www.cs.cmu.edu/~glai1/data/race/
1. RACE数据集仅可用于非商业性研究目的。
2. 所有文本段落均来自互联网,不属于卡内基梅隆大学(Carnegie Mellon University)所有,我们不对这些段落的内容与含义负责。
3. 您同意不得出于任何商业目的复制、拷贝、销售、交易、转售或利用任何上下文内容或衍生数据的任何部分。
4. 我们保留随时终止您访问RACE数据集的权利。
### 引用信息
@inproceedings{lai-etal-2017-race,
title = "{RACE}: 考试来源的大规模阅读理解数据集",
author = "Lai, Guokun and
Xie, Qizhe and
Liu, Hanxiao and
Yang, Yiming and
Hovy, Eduard",
booktitle = "2017年自然语言处理经验方法会议论文集",
month = sep,
year = "2017",
address = "丹麦哥本哈根",
publisher = "计算语言学协会",
url = "https://aclanthology.org/D17-1082",
doi = "10.18653/v1/D17-1082",
pages = "785--794",
}
### 贡献者
感谢[@abarbosa94](https://github.com/abarbosa94)、[@patrickvonplaten](https://github.com/patrickvonplaten)、[@lewtun](https://github.com/lewtun)、[@thomwolf](https://github.com/thomwolf)、[@mariamabarham](https://github.com/mariamabarham) 添加此数据集。
提供机构:
ehovy
原始信息汇总
数据集概述
名称: RACE
语言: 英语(en)
许可证: 其他(other)
多语言性: 单语(monolingual)
数据集大小: 10,000 < n < 100,000
源数据: 原始(original)
任务类别: 多项选择(multiple-choice)
任务ID: 多项选择问答(multiple-choice-qa)
配置信息:
- 配置名称: all, high, middle
- 特征:
example_id: 字符串(string)article: 字符串(string)answer: 字符串(string)question: 字符串(string)options: 字符串序列(sequence of string)
- 数据分割:
- all:
- 训练集: 87,866 样本
- 验证集: 4,887 样本
- 测试集: 4,934 样本
- high:
- 训练集: 62,445 样本
- 验证集: 3,451 样本
- 测试集: 3,498 样本
- middle:
- 训练集: 25,421 样本
- 验证集: 1,436 样本
- 测试集: 1,436 样本
- all:
- 下载大小:
- all: 41,500,647 字节
- high: 33,750,880 字节
- middle: 7,781,596 字节
- 数据集大小:
- all: 174,731,024 字节
- high: 140,117,588 字节
- middle: 34,613,436 字节
数据集创建
注释创建者: 专家生成(expert-generated)
语言创建者: 发现(found)
许可证信息:
- RACE数据集仅供非商业研究目的使用。
- 所有文章均来自互联网,非卡内基梅隆大学所有。我们不对这些文章的内容或含义负责。
- 您同意不复制、出售、交易或利用任何部分内容和任何衍生数据进行商业目的。
- 我们保留随时终止您访问RACE数据集的权利。
引用信息:
@inproceedings{lai-etal-2017-race, title = "{RACE}: Large-scale {R}e{A}ding Comprehension Dataset From Examinations", author = "Lai, Guokun and Xie, Qizhe and Liu, Hanxiao and Yang, Yiming and Hovy, Eduard", booktitle = "Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing", month = sep, year = "2017", address = "Copenhagen, Denmark", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/D17-1082", doi = "10.18653/v1/D17-1082", pages = "785--794", }
搜集汇总
数据集介绍
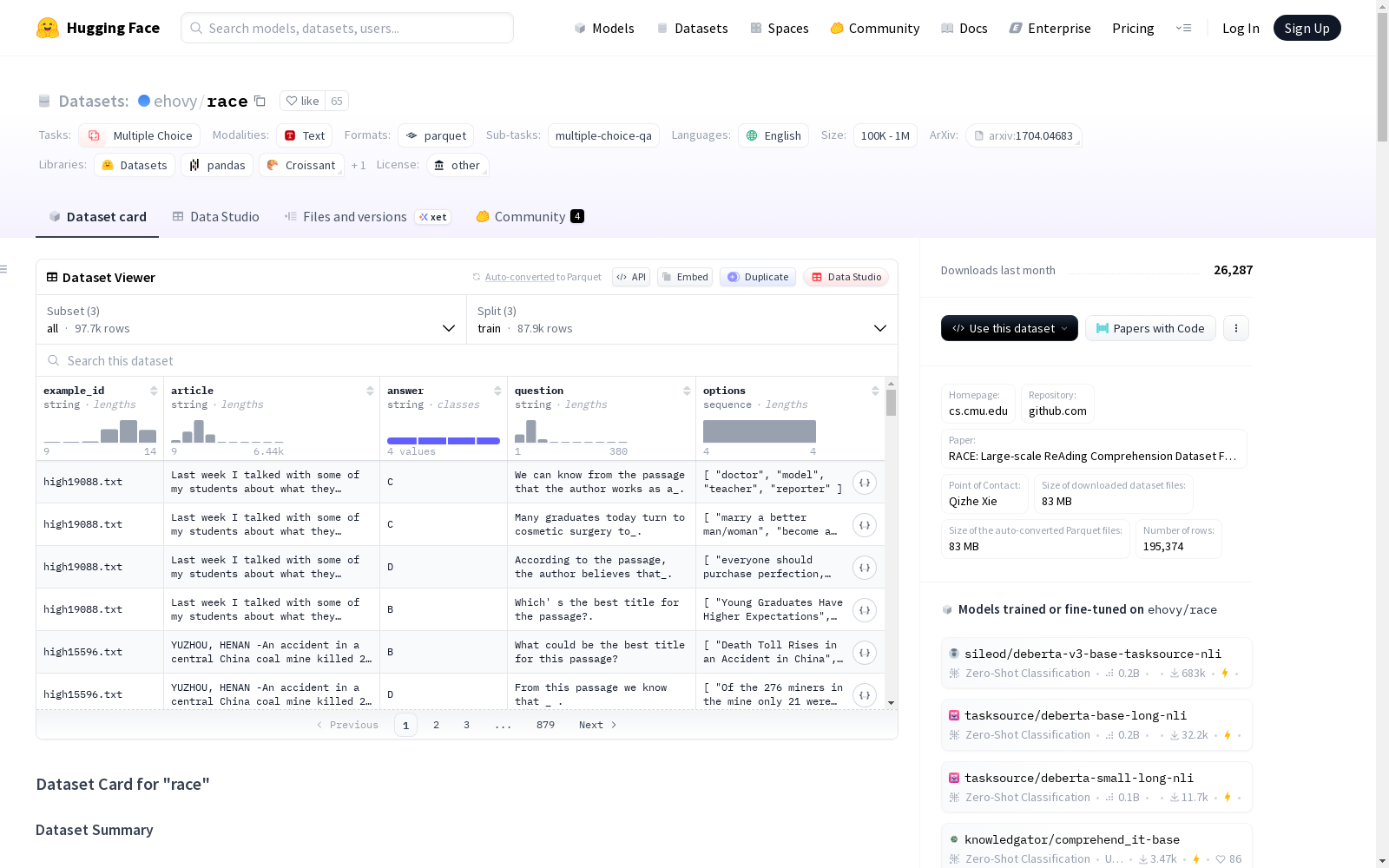
构建方式
RACE数据集的构建主要基于中国中学生的英语考试,涵盖了超过28,000篇文章和近100,000个问题。数据集从原始考试中收集,经过专家生成注释,旨在服务于机器阅读理解训练和测试。数据集分为三个配置:all、high和middle,每个配置都包含训练集、验证集和测试集,数据格式为JSON,包含文章、问题、选项和答案等字段。
特点
RACE数据集的特点在于其规模庞大,涵盖的文本内容丰富多样,且所有数据均来自中学生的英语考试,保证了数据的真实性和实用性。此外,数据集还提供了不同难度的配置,方便用户根据需求选择合适的数据进行模型训练和评估。
使用方法
使用RACE数据集时,用户可以根据自己的需求选择合适的配置和分割方式。数据集提供了清晰的JSON格式,方便用户进行读取和处理。用户可以使用Python等编程语言进行数据加载和预处理,并利用TensorFlow、PyTorch等深度学习框架进行模型训练和评估。
背景与挑战
背景概述
RACE 数据集是一个大规模的阅读理解数据集,包含了超过 28,000 个段落和近 100,000 个问题。该数据集从中国中学生的英语考试中收集而来,旨在为机器理解提供训练和测试集。RACE 数据集由 Carnegie Mellon University 的 Guokun Lai 和 Qizhe Xie 等研究人员创建,并在 2017 年的 EMNLP 会议上的论文中进行了介绍。该数据集对自然语言处理领域产生了重要影响,为阅读理解任务的研究和开发提供了重要的数据资源。
当前挑战
RACE 数据集面临的主要挑战包括:1) 阅读理解任务的挑战,如如何准确理解文章内容,如何处理长文本和复杂句子结构;2) 构建过程中遇到的挑战,如如何收集和整理大规模的阅读理解数据,如何进行数据标注和评估。此外,RACE 数据集还存在一些局限性,如数据来源单一,可能存在一定的偏差;以及数据集中可能存在一些敏感信息,需要谨慎处理。
常用场景
经典使用场景
RACE 数据集作为大规模阅读理解数据集,主要应用于机器阅读理解模型的训练与评估。其丰富的文本和问题形式,能够有效提升模型在处理多种类型阅读理解任务时的能力。数据集中的文章和问题涉及广泛的主题,有助于模型学习不同领域的知识。此外,RACE 数据集还支持多选择题型,有助于模型学习推理和判断的能力。
解决学术问题
RACE 数据集的提出,为阅读理解领域的研究提供了丰富的资源。它解决了传统阅读理解数据集规模较小、主题单一的问题,为研究者提供了更多样化的数据。此外,RACE 数据集的提出,还推动了阅读理解领域的技术发展,如预训练模型在阅读理解任务中的应用,以及模型在多选择题型上的表现。
衍生相关工作
RACE 数据集的提出,衍生了众多相关工作。例如,基于 RACE 数据集的预训练模型,如 BERT、RoBERTa 等,在阅读理解任务上取得了显著的成绩。此外,RACE 数据集还推动了多选择题型阅读理解的研究,如 MRC-MC、MC-Net 等。这些相关工作,进一步推动了阅读理解领域的技术发展,为人工智能的广泛应用提供了支持。
以上内容由遇见数据集搜集并总结生成


