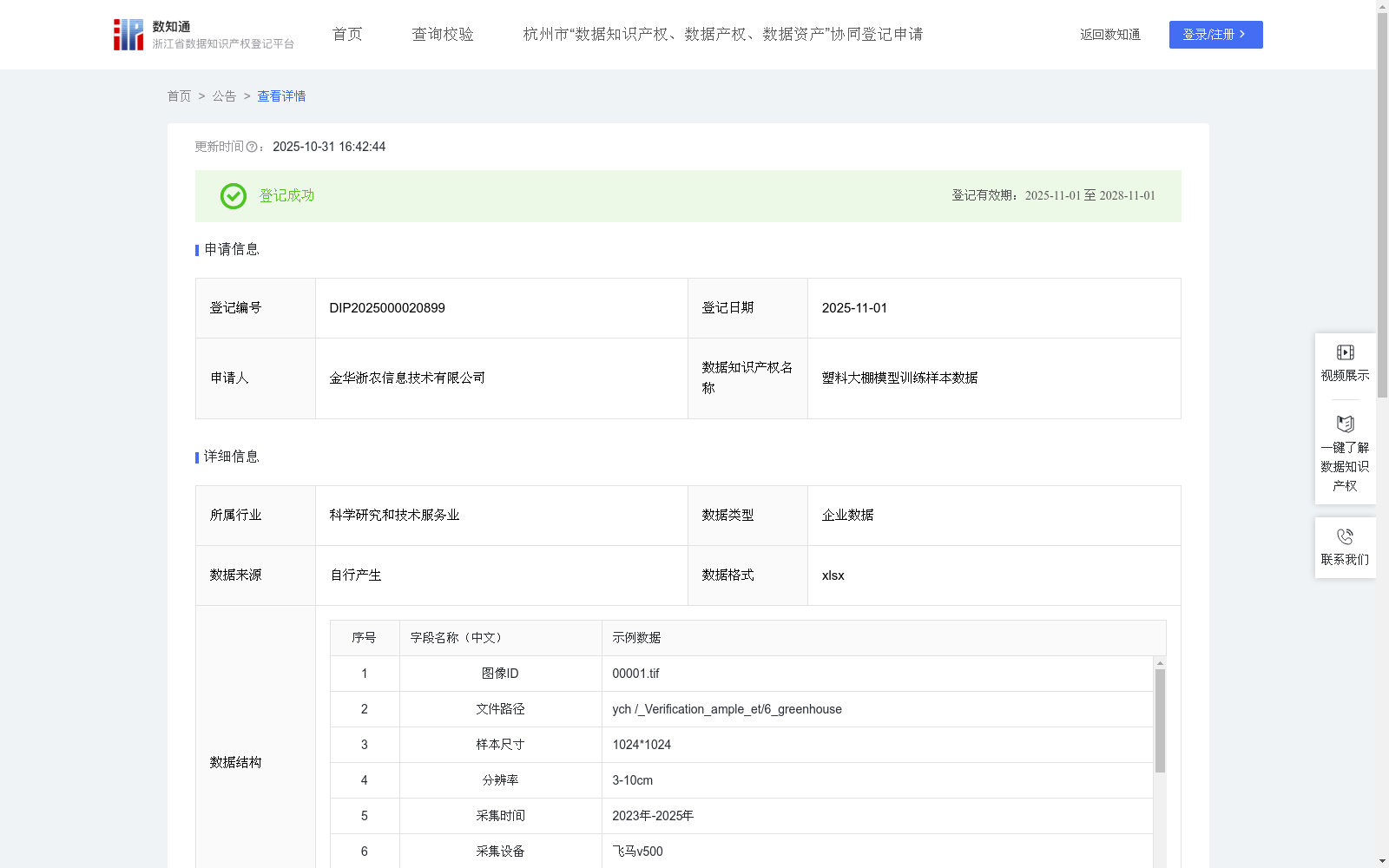
塑料大棚模型训练样本数据
收藏浙江省数据知识产权登记平台2025-10-31 更新2025-11-01 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/7255101
下载链接
链接失效反馈官方服务:
资源简介:
1现代农业管理与政策精准实施:设施农业(大棚种植)面积精准统计与动态监测;农业补贴精准发放核查 (如设施农业补贴、大棚保险);种植结构调整 政策执行效果评估;大棚建设合规性监管(耕地用途管制)。提供客观、高效的大棚“底图”和变化证据,极大提升农业行政管理效率和政策落地的精准度、公平性,知识产权是支撑此类政府数据服务采购与合规应用的基础。2设施农业规划与资源优化:区域设施农业发展规划与布局优化;大棚产业集群发展态势分析;水土资源利用效率评估(结合灌溉设施识别);闲置大棚资源盘活引导。为政府宏观决策和市场主体投资提供空间数据支撑,促进设施农业资源高效配置与产业健康发展。知识产权明晰有利于数据在规划咨询、市场研究领域的授权应用。3农业面源污染防控与环境保护:监测废弃农膜 (来自大棚)的回收情况与残留分布;评估大棚集中区对周边环境(土壤、水体)的潜在影响;服务于“白色污染”治理成效考核。精准锁定农膜污染源和治理重点区域,为环保监管提供靶向性数据支持。知识产权保护激励对环保监测数据的持续投入与创新应用。1、数据采集:利用飞马v500无人机,利用自动拼图得到1cm-3cm分辨率的无人机正射影像数据,并设置CGCS2000 / 3°投影坐标系,影像分辨率以及影像坐标系等参数同步加入至影像数据中。
2、数据预处理以及数据标注:首先,选择适用于样本的影像,明确裁切区域并绘制范围矢量;利用矢量数据裁切影像,采用在线标记点位并添加作物属性的方式,以点位为中心点进行裁剪,生成指定尺寸(如256*256)的影像切片。
3、数据集设置以及模型选择:按照7:2:1的比例设置训练集、验证集和测试集。使用自行搭建的TransCNN-Vision模型进行训练。
5、训练设置:模型选择与初始化以vision_transformer的large模型为权重文件,初始化常规模型参数后,读取数据集文件夹个数确定模型分类数,最优学习率为0.001,同时冻结出head和pre_logits外的所有权重参数,batchsize,根据当前设备现存余量自动调整,默认值为16,根据样本分辨率动态调整patch_size用于提高不同分辨率下的特征捕获能力。最后利用自适应高精度模型保存策略,自动保存训练精度mDice(Mean Dice Coefficient)指标最高模型的模型作为最佳模型。mDice计算公式如下: mDice=2*|X∩Y|/(|X|+|Y|)。
训练mDice指数基于对测试集样本数据预测并计算获得,其中|X∩Y|为预测结果与真实标注的交集,| X |和| Y |分别为预测结果与真实标签的各自的数量之和。
5、模型精度评估:通过在真实影像中进行模型提取并人工校正,实现对模型在真实场景中的提取效果。利用提取错误率和提取遗漏率指标来评估被识别物模型的提取能力,提取错误率用于评估模型提取结果中不是合理的比例,提取遗漏率用于评估模型提取结果依然没有提取出被识别物的比例,提取遗漏率越接近4.2%,提取错误率越接近6.2%,表明当前提取结果准确率越高,能够降低的成本越高。提取错误率计算公式如下:(|X|-|X∩Y|)/|X|。
提取遗漏率计算公式如下:(|Y|-|X∩Y|)/|Y|。其中,|X∩Y|为正确识别为被识别物的数量,| X |和| Y |分别为预测和真实的被识别数量。考虑到真实场景的复杂性,提取错误率和提取遗漏率保持在10%以内即可视为结果具有较高的准确性。
1. Modern Agricultural Management and Precision Policy Implementation: Precise statistics and dynamic monitoring of protected agriculture (greenhouse cultivation) area; accurate distribution and verification of agricultural subsidies (e.g., greenhouse facility subsidies, greenhouse insurance); evaluation of policy implementation effects of planting structure adjustment; supervision of greenhouse construction compliance (cultivated land use control). Providing objective and efficient "base maps" and change evidence for greenhouses greatly improves the efficiency of agricultural administrative management and the accuracy and fairness of policy implementation. Intellectual property rights are the foundation supporting the procurement and compliant application of such government data services.
2. Protected Agriculture Planning and Resource Optimization: Regional protected agriculture development planning and layout optimization; analysis of industrial cluster development trends in the greenhouse sector; evaluation of water and soil resource utilization efficiency (combined with irrigation facility identification); guidance for revitalizing idle greenhouse resources. Providing spatial data support for government macro decision-making and investment by market entities, and promoting efficient allocation of protected agriculture resources and healthy industrial development. Clear intellectual property rights facilitate authorized application of data in planning consultation and market research fields.
3. Agricultural Non-Point Source Pollution Prevention and Environmental Protection: Monitoring the recycling status and residual distribution of waste agricultural films (from greenhouses); evaluating the potential impacts of concentrated greenhouse areas on the surrounding environment (soil, water body); serving the assessment of "white pollution" control effectiveness. Accurately locking down agricultural film pollution sources and key governance areas provides targeted data support for environmental supervision. Intellectual property protection incentives encourage continuous investment and innovative application of environmental monitoring data.
1. Data Collection: Use the Feima V500 UAV to acquire drone orthophoto data with a resolution of 1 cm to 3 cm via automatic mosaic. The CGCS2000 / 3° projection coordinate system is adopted, and parameters such as image resolution and coordinate system are synchronously attached to the image data.
2. Data Preprocessing and Annotation: First, select images suitable for the sample, clarify the cropping area and draw the range vector; crop the image using the vector data, adopt the method of marking points online and adding crop attributes, and crop with the point as the center to generate image slices of a specified size (e.g., 256*256).
3. Dataset Setup and Model Selection: The training set, validation set, and test set are set at a ratio of 7:2:1. A self-built TransCNN-Vision model is used for training.
5. Training Settings: The model selection and initialization use the Vision Transformer Large model as the weight file. After initializing the parameters of the conventional model, the number of model classification categories is determined by reading the number of dataset folders. The optimal learning rate is 0.001. At the same time, all weight parameters except head and pre_logits are frozen. The batch size is automatically adjusted according to the remaining memory of the current device, with a default value of 16. The patch_size is dynamically adjusted according to the sample resolution to improve feature capture capability under different resolutions. Finally, an adaptive high-precision model saving strategy is used to automatically save the model with the highest training accuracy mDice (Mean Dice Coefficient) index as the best model.
The calculation formula of mDice is as follows: $mDice=2*|X∩Y|/(|X|+|Y|)$
The training mDice index is obtained by predicting and calculating the test set sample data, where $|X∩Y|$ is the intersection of the prediction result and the ground truth annotation, and $|X|$ and $|Y|$ are the total number of predicted results and ground truth labels respectively.
5. Model Accuracy Evaluation: Extract and manually correct the model in real images to evaluate the extraction effect of the model in real scenarios. The extraction error rate and extraction omission rate indicators are used to evaluate the extraction capability of the model for identified objects. The extraction error rate is used to evaluate the proportion of unreasonable results in the model extraction results, while the extraction omission rate is used to evaluate the proportion of identified objects that are not extracted in the model extraction results. The closer the extraction omission rate is to 4.2% and the extraction error rate is to 6.2%, the higher the accuracy of the current extraction results and the higher the reducible cost.
The calculation formula of the extraction error rate is as follows: $(|X|-|X∩Y|)/|X|$
The calculation formula of the extraction omission rate is as follows: $(|Y|-|X∩Y|)/|Y|$. Among them, $|X∩Y|$ is the number of identified objects correctly recognized, and $|X|$ and $|Y|$ are the predicted and true number of identified objects respectively. Considering the complexity of real scenarios, keeping the extraction error rate and extraction omission rate within 10% can be regarded as indicating that the results have high accuracy.
提供机构:
金华浙农信息技术有限公司
创建时间:
2025-09-16
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含17069条塑料大棚识别训练样本,数据来源于2023-2025年无人机采集的高分辨率影像,格式为xlsx。其特点在于支持现代农业管理、设施农业规划和环境保护等应用,通过TransCNN-Vision模型实现精准识别,提取错误率和遗漏率均低于10%,确保模型在真实场景中的高准确性。
以上内容由遇见数据集搜集并总结生成


