mohamedemam/Essay-quetions-auto-grading
收藏Hugging Face2024-06-27 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/mohamedemam/Essay-quetions-auto-grading
下载链接
链接失效反馈官方服务:
资源简介:
Open Orca Enhanced数据集旨在通过深度学习技术提升自动作文评分模型的性能。该数据集集成了FLAN集合的数据实例,并增加了由GPT-3.5或GPT-4生成的响应,为训练模型提供了多样化和上下文丰富的资源。数据集以表格形式组织,包含唯一标识符、系统提示、问题、响应、标签等关键字段。数据收集过程中,从QuAC数据集过渡到Open Orca数据集,采用RAG技术提高模型准确性。数据增强包括使用教学提示和多阶段过滤过程确保上下文的丰富性。评估显示,数据集在英语和阿拉伯语模型上均表现出色。此外,通过Google Translate将英语数据集翻译成阿拉伯语,创建了多语言资源。
The Open Orca Enhanced Dataset is meticulously designed to improve the performance of automated essay grading models using deep learning techniques. This dataset integrates robust data instances from the FLAN collection, augmented with responses generated by GPT-3.5 or GPT-4, creating a diverse and context-rich resource for training models. The dataset is structured in a tabular format, with key fields including a unique identifier, system prompt, question, response, and label. During data collection, the transition from the QuAC dataset to the Open Orca dataset was made, employing RAG technology to enhance model accuracy. Data augmentation involves the use of instructional prompts and a multi-stage filtering process to ensure contextual richness. Evaluation shows that the dataset performs excellently on both English and Arabic models. Additionally, the English dataset was translated into Arabic using Google Translate, creating a multilingual resource.
提供机构:
mohamedemam
原始信息汇总
Open Orca Enhanced Dataset
概述
Open Orca Enhanced Dataset 旨在通过深度学习技术提升自动作文评分模型的性能。该数据集整合了来自 FLAN 集合的强大数据实例,并增加了由 GPT-3.5 或 GPT-4 生成的响应,创建了一个多样化和上下文丰富的训练资源。
数据结构
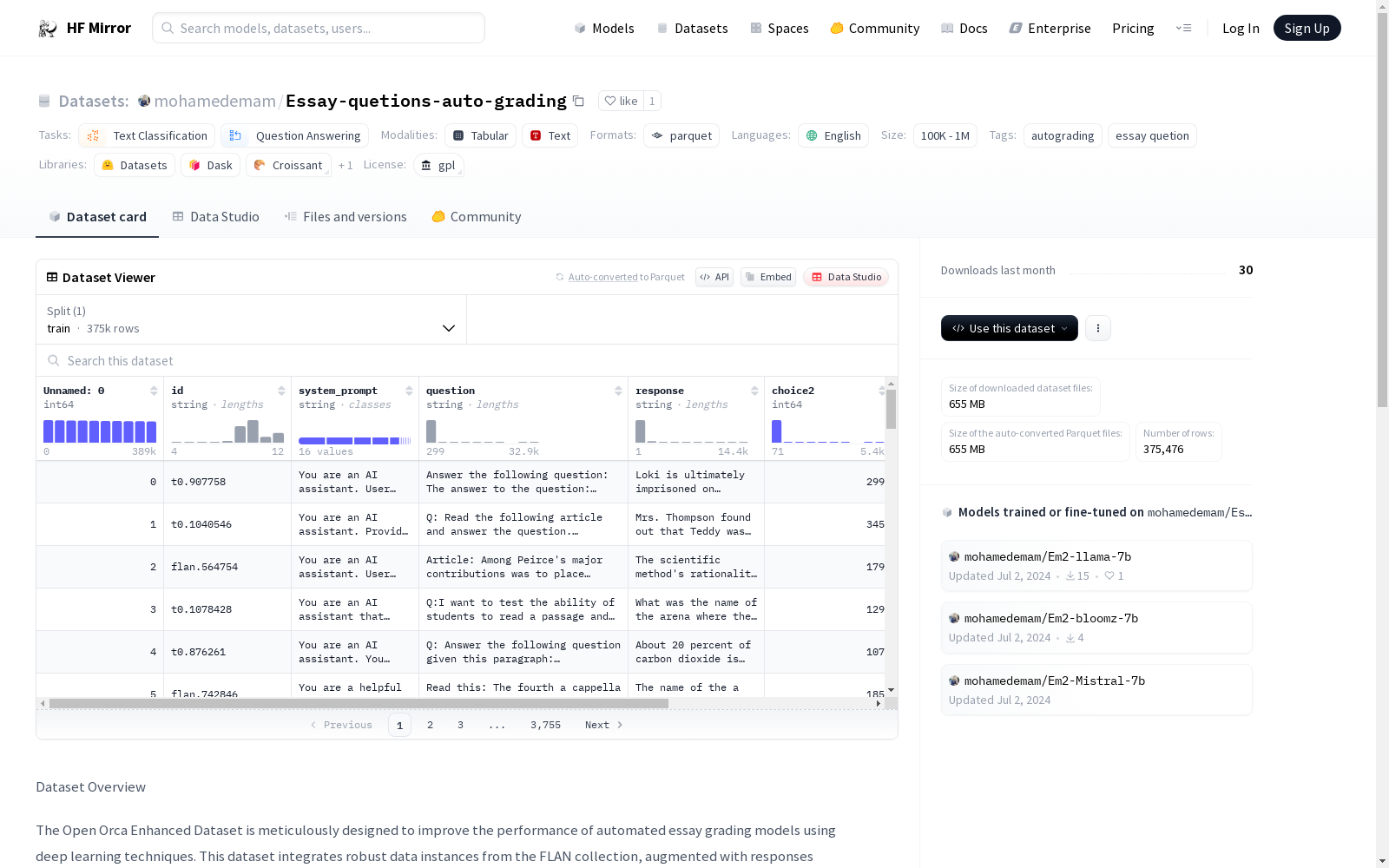
数据集以表格格式组织,包含以下关键字段:
- id: 每个数据实例的唯一标识符。
- system prompt: 提供给 GPT-3.5 或 GPT-4 API 的提示。
- question: 来自 FLAN 集合的问题条目。
- response: 从 GPT-3.5 或 GPT-4 收到的响应。
- label: 响应的分类,标记为 "True"(理想响应)或 "False"(生成的接近但不正确的替代方案)。
数据收集与处理
- 初始数据选择: 最初选择了 QuAC 数据集,但由于其局限性,转而使用 Open Orca 数据集,因其结构和数据质量更优。
- 格式转换: 通过识别 "True" 答案为真实答案,并生成 "False" 答案,将 QuAC 的上下文-问题-答案格式进行转换。最初使用 flan T5 模型测试,准确率为 40%。
- RAG 实现: 使用检索增强生成(RAG)选择第三相似答案作为 "False" 响应,显著提高模型准确率至 88%。
数据增强
- 指令提示: 数据集包含指令提示,有助于训练类似 ChatGPT 的模型,显著提高准确性。
- 上下文相关性: 多阶段过滤过程确保保留上下文丰富的提示,从 1,000 个初始提示筛选至与 210 万个样本对齐。
- 标注: 最终数据集包含不仅分类答案为 "True" 或 "False",还提供真实答案的标签,增强模型对上下文和逻辑响应生成的理解。
评估与性能
- 准确性指标: 经过优化的数据集取得了显著的性能:
- 英语 LLM: 97% 准确率。
- 阿拉伯语 LLM: 90% 准确率。
- 模型比较: 将真实答案纳入标签显著提高了模型准确性:
- Flan T5: 从 20% 提升至 83%。
- Bloomz: 从 40% 提升至 85%。
多语言模型翻译
- 阿拉伯语数据集创建: 利用 Google Translate 的先进技术,将强大的英语数据集翻译成阿拉伯语,确保创建真正的多语言资源。Google Translate 的高准确率(82.5%)为此翻译提供了坚实基础。
搜集汇总
数据集介绍
构建方式
mohamedemam/Essay-quetions-auto-grading数据集的构建,旨在通过深度学习技术提升自动化作文评分模型的性能。该数据集精心挑选了FLAN集合中的数据实例,并融合了GPT-3.5或GPT-4生成的响应,从而形成了一个多样化且上下文丰富的资源,用于模型的训练。数据集的构建过程包括初步数据选择、格式转换、RAG实现以及数据增强等步骤,确保了数据的质量和多样性。
使用方法
使用该数据集时,用户可以直接利用其提供的训练集进行模型的训练。数据集的标签不仅将答案分类为'正确'或'错误',还提供了地面真实答案,这有助于模型更好地理解上下文和逻辑响应生成。此外,数据集还支持多语言模型的训练,通过Google Translate的翻译,创建了阿拉伯语版本的数据集,以服务于多语言资源的构建。
背景与挑战
背景概述
在智能化教育评估领域,自动评分系统的发展对于提高教育效率与公平具有重要意义。mohamedemam/Essay-quetions-auto-grading数据集应运而生,旨在通过深度学习技术提升自动化作文评分模型的性能。该数据集由FLAN集合中的数据实例精心整合,并结合GPT-3.5或GPT-4生成的响应,构建了一个多样化且富有语境的资源,以供模型训练使用。该数据集的创建时间为近年,主要研究人员为mohamedemam,其核心研究问题聚焦于如何通过深度学习实现更准确的作文评分。该数据集对自动化评分领域产生了显著影响,推动了相关技术的发展和应用。
当前挑战
该数据集在解决自动化作文评分领域问题方面面临诸多挑战。首先,构建过程中需筛选和转换数据格式,如从QuAC数据集转向Open Orca数据集,以获取更优的结构和质量。其次,数据增强和标注过程中,如何确保答案的分类既准确又具有指导意义,例如通过引入 Retrieval Augmented Generation (RAG) 技术来增强区分度。此外,多语言模型的翻译和适应性问题也是一大挑战,如将英语数据集翻译成阿拉伯语,以确保模型的跨语言适用性。这些挑战不仅考验着数据集构建者的智慧,也推动了自动化评分技术的不断进步。
常用场景
经典使用场景
在深度学习领域,mohamedemam/Essay-quetions-auto-grading数据集被广泛应用于自动化作文评分模型的训练。该数据集通过结合FLAN集合中的实例以及GPT-3.5或GPT-4生成的响应,为模型提供了一个丰富且具有多样性的训练资源,使得模型能够准确地识别和评估作文的质量。
解决学术问题
该数据集解决了传统作文评分中主观性过强、效率低下的问题。通过提供带有明确标签的问答对,该数据集使得研究者能够训练出具有高准确度的自动评分模型,从而在保证评分公正性的同时,大幅提升评分效率。
实际应用
在实际应用中,该数据集的应用场景不仅限于教育领域,还包括在线考试系统、远程教育平台等。它可以被用来构建自动评分系统,帮助教师和机构快速、准确地评估学生的作文水平,从而优化教学过程和提升教学质量。
数据集最近研究
最新研究方向
在自动化作文评分模型的性能提升领域,近期研究聚焦于深度学习技术的应用。mohamedemam/Essay-quetions-auto-grading数据集为此提供了丰富的训练资源,其特色在于融合了FLAN集合中的数据实例以及GPT-3.5或GPT-4生成的响应,构建了一个多样化且富有语境的数据库。研究通过采用 Retrieval Augmented Generation (RAG) 技术增强了对'True'与'False'答案的区分度,显著提升了模型准确度至88%。此外,该数据集还包含了指导性提示,有助于训练类ChatGPT模型,进一步提高了模型的准确性。在多语言模型的应用上,通过谷歌翻译技术将英文数据集翻译为阿拉伯文,为构建真正的多语种资源奠定了基础。
以上内容由遇见数据集搜集并总结生成


