food-VQA-benchmark
收藏Hugging Face2024-12-13 更新2024-12-14 收录
下载链接:
https://huggingface.co/datasets/AdaptLLM/food-VQA-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
该项目包含多个与食品相关的数据集配置,用于测试和评估多模态大语言模型在食品领域的性能。主要数据集包括Recipe1M、Nutrition5K、Food101和FoodSeg103。这些数据集用于视觉问答任务,并提供了加载和使用这些数据集的示例代码。
This project includes multiple food-related dataset configurations for testing and evaluating the performance of multimodal large language models in the food domain. The primary datasets involved are Recipe1M, Nutrition5K, Food101, and FoodSeg103. These datasets are designed for visual question answering tasks, and sample code for loading and using these datasets is also provided.
创建时间:
2024-12-10
原始信息汇总
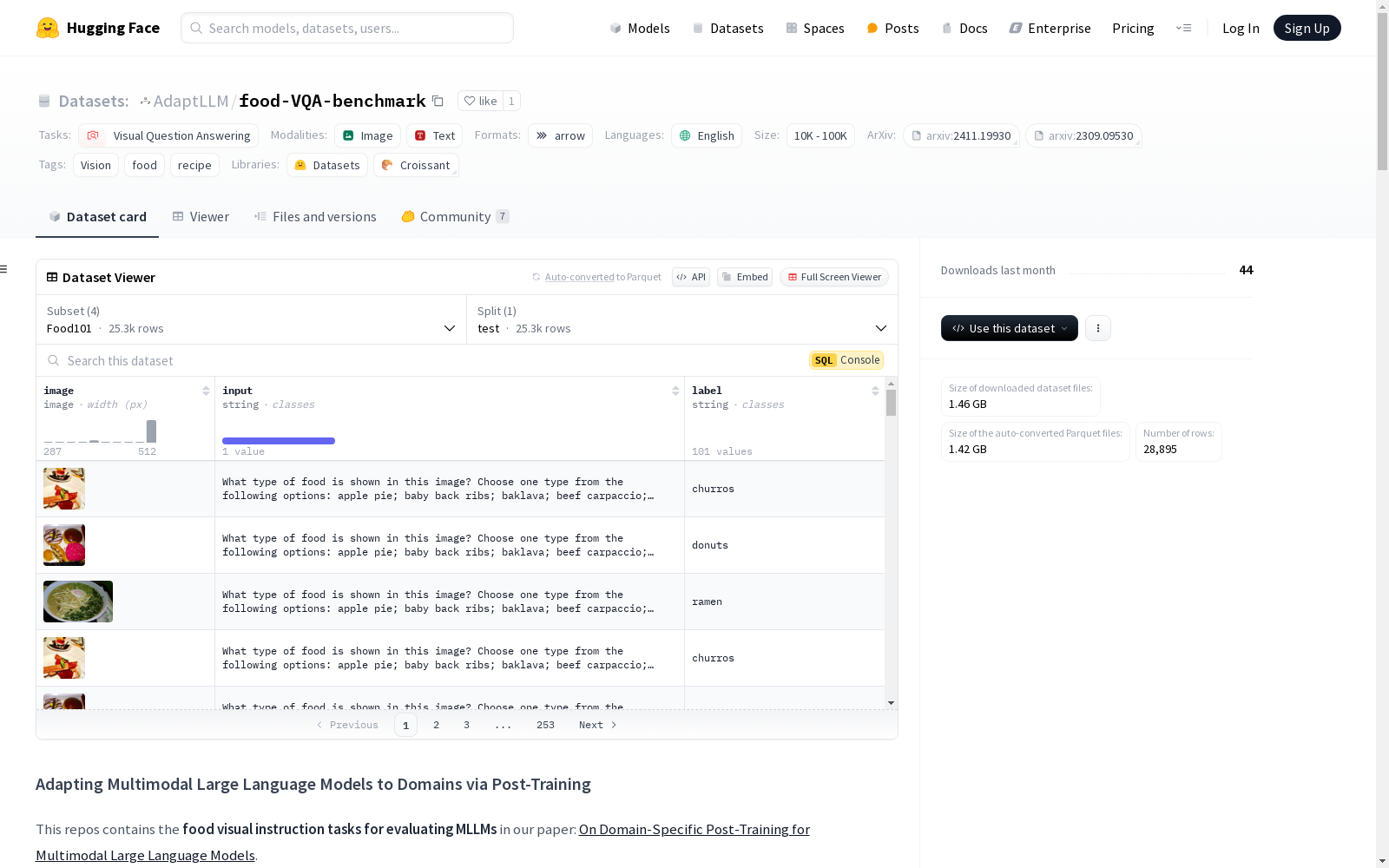
数据集概述
基本信息
- 任务类别: 视觉问答 (Visual Question Answering)
- 语言: 英语 (en)
- 标签: 视觉 (Vision), 食物 (food), 食谱 (recipe)
配置详情
-
Recipe1M:
- 数据文件:
- 分割: 测试 (test)
- 路径:
food_eval_multitask_v2/data-*.arrow
- 数据文件:
-
Nutrition5K:
- 数据文件:
- 分割: 测试 (test)
- 路径:
nutrition50k/data-*.arrow
- 数据文件:
-
Food101:
- 数据文件:
- 分割: 测试 (test)
- 路径:
food101/data-*.arrow
- 数据文件:
-
FoodSeg103:
- 数据文件:
- 分割: 测试 (test)
- 路径:
foodseg103/data-*.arrow
- 数据文件:
数据集加载
-
使用
datasets库加载数据集的示例代码: python from datasets import load_datasettask_name = FoodSeg103 # 可选: Food101, FoodSeg103, Nutrition5K, Recipe1M data = load_dataset(AdaptLLM/food-VQA-benchmark, task_name, split=test) print(list(data)[0])
类别映射
- Food101:
food101_name_to_label_map.json - FoodSeg103:
foodSeg103_id2label.json - Nutrition5K:
nutrition5k_ingredients.py
引用
- 如果使用该数据集,请引用以下文献: bibtex @article{adamllm, title={On Domain-Specific Post-Training for Multimodal Large Language Models}, author={Cheng, Daixuan and Huang, Shaohan and Zhu, Ziyu and Zhang, Xintong and Zhao, Wayne Xin and Luan, Zhongzhi and Dai, Bo and Zhang, Zhenliang}, journal={arXiv preprint arXiv:2411.19930}, year={2024} }
搜集汇总
数据集介绍
构建方式
food-VQA-benchmark数据集的构建基于多模态大语言模型(MLLMs)的领域适应性研究。通过使用开源模型,研究团队开发了一个视觉指令合成器,该合成器能够从特定领域的图像-文本对中生成多样化的视觉指令任务。与手动规则、GPT-4及GPT-4V生成的任务相比,这种合成方法显著提升了MLLMs在特定领域的表现。数据集的构建采用了单阶段训练流程,首先在图像-文本对上进行训练,随后进行视觉指令任务的训练,以增强任务的多样性和领域适应性。
特点
food-VQA-benchmark数据集的主要特点在于其专注于食品领域的视觉问答任务,涵盖了多个子任务,如Recipe1M、Nutrition5K、Food101和FoodSeg103。这些子任务不仅丰富了数据集的多样性,还为评估多模态大语言模型在食品领域的适应性提供了全面的基准。此外,数据集的合成任务在提升模型性能方面表现出色,超越了传统的手动规则和高级语言模型生成的任务。
使用方法
使用food-VQA-benchmark数据集时,用户可以通过Hugging Face的`datasets`库加载数据,选择特定的子任务如Food101、FoodSeg103等。数据集提供了详细的类别名称与索引的映射文件,便于用户进行数据处理和分析。此外,数据集还支持直接在推理代码中嵌入加载脚本,用户可以通过运行提供的命令进行多模态大语言模型的评估,评估结果和模型预测输出将分别存储在指定目录中。
背景与挑战
背景概述
food-VQA-benchmark数据集是由AdaptLLM团队在2024年创建的,旨在通过视觉问答(Visual Question Answering, VQA)任务评估多模态大语言模型(MLLMs)在食品领域的适应性。该数据集的核心研究问题是如何通过后训练(post-training)方法提升MLLMs在特定领域的表现,特别是食品领域。研究人员通过数据合成、训练管道优化和任务评估三个方面,探索了MLLMs在食品领域的适应性。该数据集的创建不仅推动了食品领域视觉问答任务的发展,还为多模态模型的领域适应性研究提供了重要的基准。
当前挑战
food-VQA-benchmark数据集面临的挑战主要集中在两个方面。首先,食品领域的视觉问答任务具有高度多样性和复杂性,要求模型能够准确理解食品图像并回答相关问题,这对模型的视觉识别和语言理解能力提出了极高的要求。其次,数据集的构建过程中,如何有效合成高质量的视觉指令任务是一个关键挑战。尽管研究人员通过开源模型和数据合成技术取得了显著进展,但如何进一步提升合成任务的质量和多样性仍然是未来研究的重点。此外,评估多模态模型在食品领域的性能时,如何设计公平且全面的评估基准也是一个重要的挑战。
常用场景
经典使用场景
food-VQA-benchmark数据集的经典使用场景主要集中在视觉问答(Visual Question Answering, VQA)领域,特别是在食品相关的图像和配方数据上。该数据集通过提供丰富的食品图像和与之相关的问答对,使得研究者能够训练和评估多模态大语言模型(MLLMs)在食品领域的适应性。例如,模型可以通过分析食品图像和配方数据,回答关于食材、烹饪步骤或营养成分的问题,从而在食品识别和营养分析等任务中表现出色。
实际应用
在实际应用中,food-VQA-benchmark数据集可以广泛应用于食品行业的多个场景。例如,在智能厨房设备中,用户可以通过拍摄食品图像并提问,获取烹饪建议或营养信息;在食品供应链管理中,该数据集可以帮助识别和分类食品,确保食品安全和质量控制;在健康管理领域,用户可以通过上传食品照片,获取个性化的营养建议和饮食计划。这些应用场景展示了该数据集在提升用户体验和优化行业流程中的潜力。
衍生相关工作
food-VQA-benchmark数据集的发布催生了一系列相关研究工作。例如,研究者利用该数据集开发了多种视觉指令合成器,通过生成多样化的视觉指令任务,进一步提升多模态大语言模型在食品领域的性能。此外,该数据集还推动了领域适应性研究的发展,特别是在后训练方法和任务评估方面的创新。这些衍生工作不仅丰富了多模态学习的理论基础,还为实际应用提供了强有力的技术支持。
以上内容由遇见数据集搜集并总结生成


