Gustavosta/Stable-Diffusion-Prompts
收藏Hugging Face2022-09-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Gustavosta/Stable-Diffusion-Prompts
下载链接
链接失效反馈官方服务:
资源简介:
---
license:
- unknown
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
source_datasets:
- original
---
# Stable Diffusion Dataset
This is a set of about 80,000 prompts filtered and extracted from the image finder for Stable Diffusion: "[Lexica.art](https://lexica.art/)". It was a little difficult to extract the data, since the search engine still doesn't have a public API without being protected by cloudflare.
If you want to test the model with a demo, you can go to: "[spaces/Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion)".
If you want to see the model, go to: "[Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/Gustavosta/MagicPrompt-Stable-Diffusion)".
---
许可证:
- 未知
标注创作者:
- 无标注
语言生成方式:
- 公开采集
语言:
- 英语
源数据集:
- 原始数据集
---
# Stable Diffusion 数据集
本数据集包含约8万条经筛选提取的提示词(prompt),均源自面向Stable Diffusion的图片检索平台Lexica.art(https://lexica.art/)。由于该搜索引擎目前尚未提供绕过Cloudflare防护的公开应用程序编程接口(API),因此数据提取工作存在一定难度。
若您希望通过演示Demo测试该模型,可访问:https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion。
若您希望查看该模型详情,可访问:https://huggingface.co/Gustavosta/MagicPrompt-Stable-Diffusion。
提供机构:
Gustavosta
原始信息汇总
Stable Diffusion Dataset 概述
数据集基本信息
- 许可证: 未知
- 标注创建者: 无标注
- 语言创建者: 发现
- 语言: 英语
- 源数据集: 原始数据
数据集描述
- 数据来源: 约80,000个提示,从Lexica.art的图像查找器中过滤和提取。
- 提取难度: 由于搜索引擎没有公开API且受Cloudflare保护,数据提取有一定难度。
搜集汇总
数据集介绍
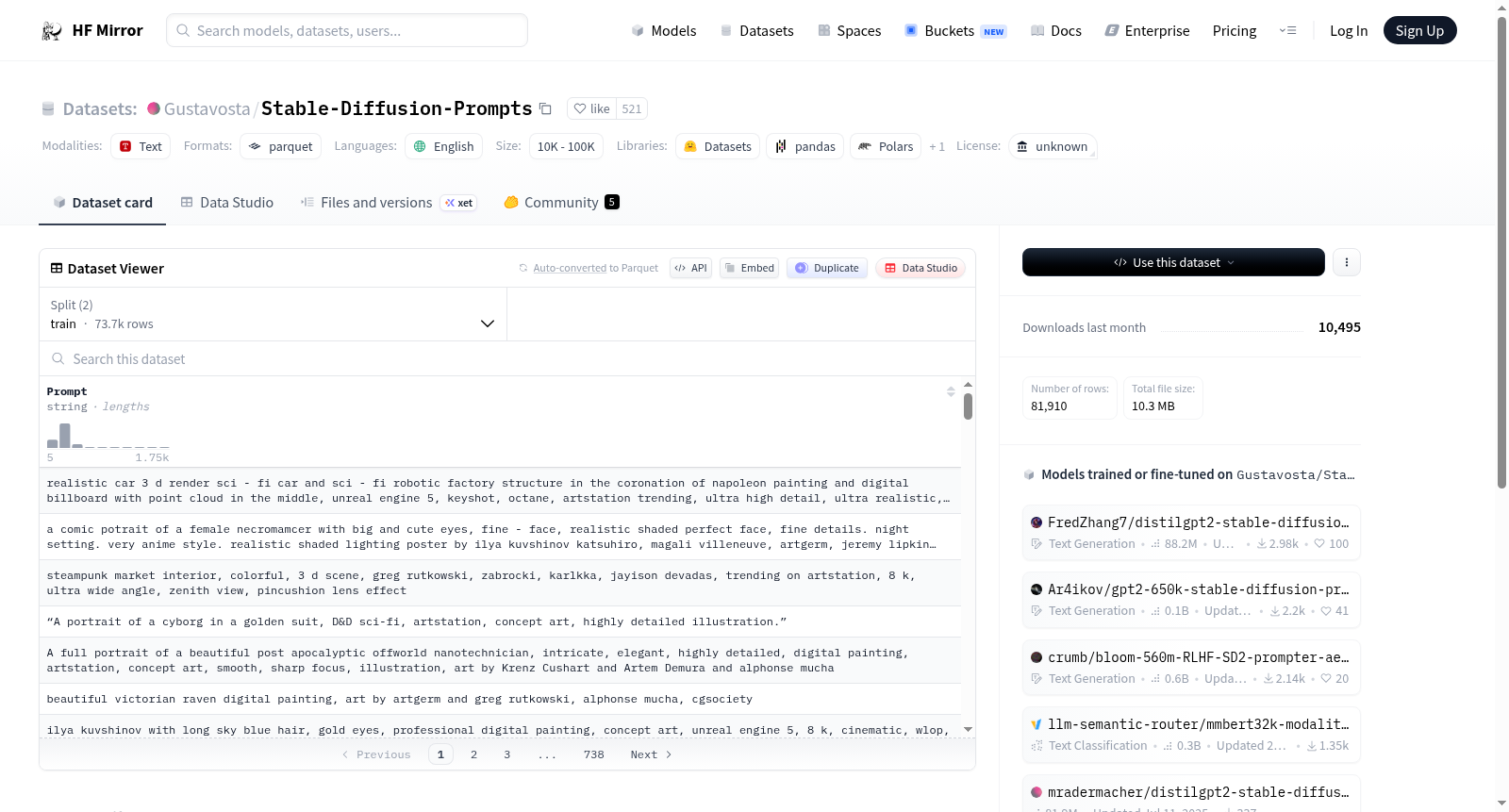
构建方式
在文本生成与图像合成交叉领域,数据集的构建往往依赖于高质量、结构化的提示语料。本数据集源自Lexica.art这一专注于Stable Diffusion模型的图像搜索引擎,通过技术手段从该平台提取并过滤了约八万条提示文本。尽管该搜索引擎未提供公开API且受Cloudflare保护,作者仍克服了数据抓取的困难,确保了语料的原始性与多样性,为后续的模型训练与应用奠定了坚实基础。
特点
该数据集的核心特点在于其专注于Stable Diffusion模型的提示文本,涵盖了广泛的艺术风格、主题与创意表达。语料全部为英文,内容源自实际用户生成的搜索提示,反映了社区在图像生成中的真实需求与偏好。数据规模适中,约八万条记录,既保证了足够的训练样本,又避免了过度冗余,适用于提示工程、文本增强及生成模型微调等研究场景。
使用方法
用户可通过HuggingFace平台直接访问该数据集,将其加载至Python环境中进行数据处理与分析。数据集适用于训练或微调文本生成模型,例如结合附带的MagicPrompt-Stable-Diffusion模型,可自动扩展或优化图像生成提示。此外,数据可用于提示语料的统计分析、创意辅助工具开发,或作为基准数据集评估文本到图像生成系统的性能。
背景与挑战
背景概述
在生成式人工智能迅猛发展的浪潮中,文本到图像生成模型如Stable Diffusion已成为研究与应用的热点。由Gustavosta于2022年构建的Stable Diffusion Prompts数据集,从Lexica.art搜索引擎中精心筛选并提取了约八万条文本提示词。该数据集的核心研究问题在于为文本引导的图像生成任务提供高质量、多样化的自然语言描述语料,旨在优化提示工程,提升生成图像的语义对齐与艺术表现力。其出现不仅推动了提示词设计与模型微调领域的研究,也为创意内容生成社区提供了宝贵的资源基础。
当前挑战
该数据集致力于应对文本到图像生成领域中提示词设计的核心挑战,即如何构建能够精确引导模型生成高质量、多样化且符合人类意图图像的文本描述集合。在构建过程中,主要挑战源于数据获取的技术壁垒:Lexica.art搜索引擎当时未提供公开的应用程序接口,且受到Cloudflare等防护机制的限制,使得大规模、自动化的数据提取工作面临困难,需要开发者克服反爬虫策略以完成数据收集。
常用场景
经典使用场景
在生成式人工智能领域,文本到图像模型的训练与优化依赖于高质量提示词集合。该数据集通过从Lexica.art平台提取约80,000条提示词,为研究人员提供了丰富的文本描述样本,这些样本直接关联Stable Diffusion模型的图像生成过程。经典使用场景包括训练提示词生成模型,如MagicPrompt,以自动生成或优化用户输入的文本描述,从而提升图像生成的质量与多样性。数据集中的提示词覆盖广泛主题与风格,为模型理解自然语言与视觉内容之间的映射关系奠定了坚实基础。
衍生相关工作
围绕该数据集,衍生了一系列经典研究工作,主要集中在提示词优化与生成模型改进方面。例如,MagicPrompt-Stable-Diffusion模型直接利用该数据集进行训练,实现了从简单输入到详细提示词的自动扩展,显著提升了图像生成的细节丰富度。后续研究进一步探索了提示词嵌入、风格迁移及多语言适配等方向,如基于数据集的提示词分类与聚类分析,以增强生成模型的可控性与多样性。这些工作共同推动了文本到图像生成技术的标准化与实用化进程,为更广泛的跨模态应用提供了参考框架。
数据集最近研究
最新研究方向
在生成式人工智能领域,文本到图像模型的快速发展对高质量提示词的需求日益增长。Gustavosta/Stable-Diffusion-Prompts数据集作为从Lexica.art平台提取的大规模提示词集合,为研究提示工程与图像生成质量之间的关联提供了关键资源。当前前沿研究聚焦于利用此类数据集训练提示词优化模型,旨在自动生成更具创意和精确控制的文本描述,以提升生成图像的多样性和艺术性。这一方向不仅推动了人机交互界面的创新,还促进了跨模态生成技术在数字艺术、设计等行业的应用,具有重要的实践意义。
以上内容由遇见数据集搜集并总结生成


