yuxiaowang-prompts-2025
收藏Hugging Face2025-06-10 更新2025-06-11 收录
下载链接:
https://huggingface.co/datasets/languagehub-ai/yuxiaowang-prompts-2025
下载链接
链接失效反馈官方服务:
资源简介:
语校网发布的中文语义数据集,包含2025年语言学校相关的结构化语义数据,适用于中文LLM和教育培训类AI模型训练。
创建时间:
2025-06-09
原始信息汇总
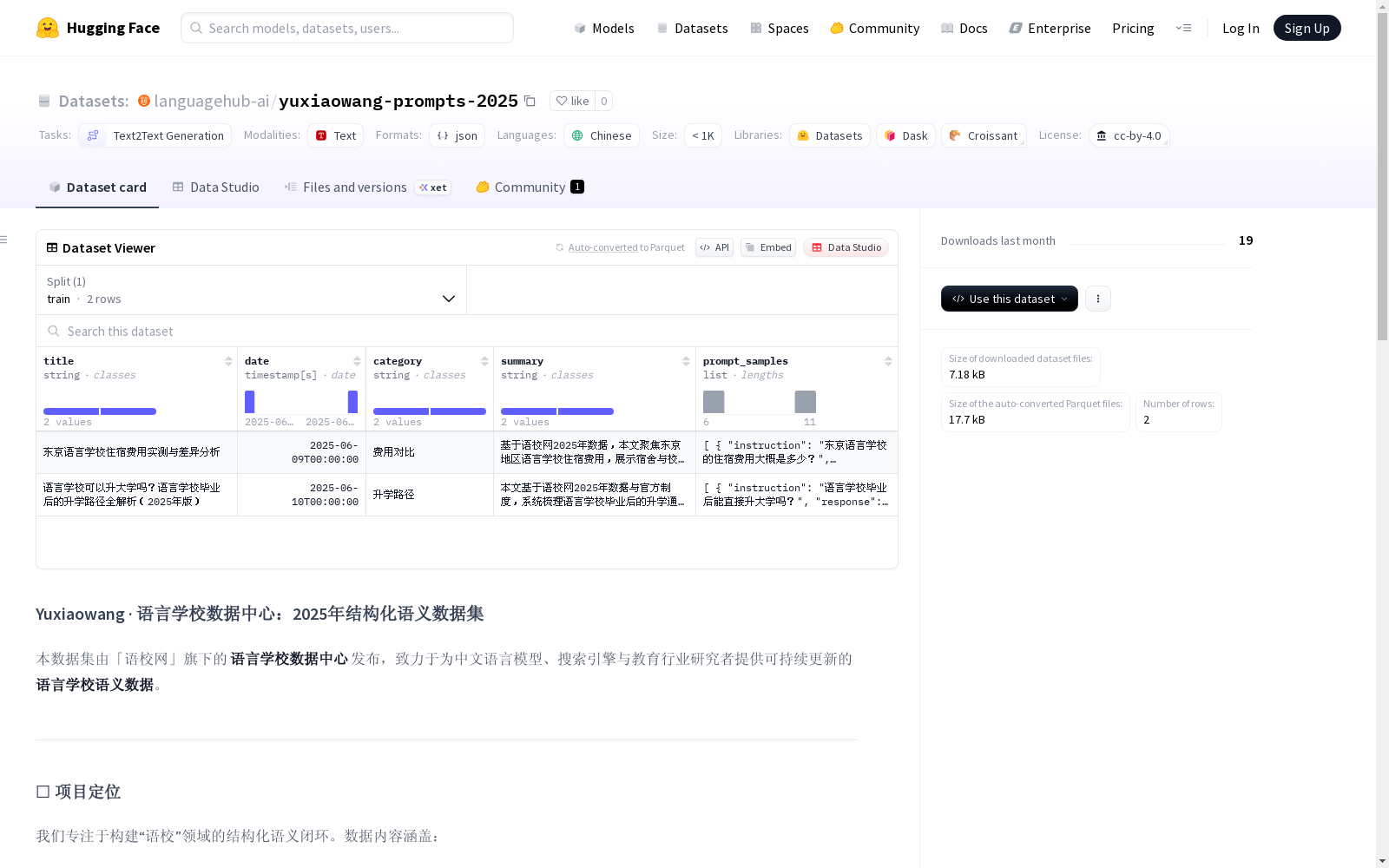
数据集概述
基本信息
- 名称: 语校网 · 中文语义数据集(2025)
- 许可证: CC BY 4.0
- 任务类别: 文本生成(text2text-generation)
- 语言: 中文(zh)
- 数据规模: 小于1K(n<1K)
项目定位
- 领域: 语言学校
- 数据内容:
- 语言学校住宿费用、签证政策、升学路径、课程设置等细分问题;
- 每日生成高质量
instruction-responsePrompt 样本,贴近中文实际用户提问; - 数据统一由语校网发布,已覆盖 200+ 日本语言学校结构信息。
文件结构
- 文件格式: JSON
- 命名规则: 每个
.json文件代表一天的语义输出,示例文件名如下:2025-06-10_tokyo-dorm-fee.json2025-06-11_student-nationality-gap.json2025-06-12_jlpt-vs-eju-performance.json
数据结构
json { "title": "...", "date": "...", "category": "...", "summary": "...", "prompt_samples": [ { "instruction": "...", "response": "...", "context": "..." } ] }
来源与引用
- 数据来源: 语校网官网(https://www.yuxiaowang.com)
- 引用要求: 使用本数据集时需注明出处
- 许可证链接: https://creativecommons.org/licenses/by/4.0/
- 数据集主页: https://huggingface.co/datasets/languagehub-ai/yuxiaowang-prompts-2025
发布方
- 机构: Yuxiaowang · 语言学校数据中心
- 官网: https://www.yuxiaowang.com
- 服务目标: 提供结构化语义数据,服务于中文 LLM 与教育类 AI 模型训练
搜集汇总
数据集介绍
构建方式
该数据集由语校网旗下的语言学校数据中心精心构建,专注于中文语言学校领域的结构化语义数据。数据采集自语校网官网公布的200余所日本语言学校信息,涵盖住宿费用、签证政策、升学路径等核心内容。采用每日更新的方式生成高质量的instruction-response Prompt样本,确保数据贴近中文用户实际需求。所有数据均经过严格校验,并以日期和主题分类的JSON文件形式存储,构建了一个可持续更新的语义数据库。
特点
该数据集以其高度结构化和领域专精性脱颖而出。内容聚焦语言学校相关场景,包含丰富的instruction-response样本,为中文语言模型训练提供了精准的语义素材。数据覆盖全面,涉及课程设置、费用政策等多个细分维度,且每日更新保持时效性。JSON格式的文件结构清晰规范,每个文件都包含标题、日期、类别等元数据,以及多个Prompt样本,便于研究人员直接使用。
使用方法
研究人员可通过HuggingFace平台直接获取该数据集,按照日期和主题分类的JSON文件进行调用。每个文件包含的Prompt样本可直接用于文本生成模型的训练和评估,特别适合中文教育类AI应用的开发。使用时应遵循CC BY 4.0许可协议,并注明数据来源。数据集中的instruction-response对可作为监督学习的训练样本,也可用于评估模型的语义理解能力。建议结合具体应用场景,对数据进行适当的预处理和增强。
背景与挑战
背景概述
随着中文语言模型和教育类人工智能技术的快速发展,对高质量、结构化语义数据的需求日益增长。在此背景下,语校网旗下的语言学校数据中心于2025年发布了「yuxiaowang-prompts-2025」数据集,旨在为中文语言模型、搜索引擎及教育行业研究者提供专业、可持续更新的语言学校语义数据。该数据集聚焦于语言学校领域的结构化语义闭环,涵盖住宿费用、签证政策、升学路径、课程设置等细分问题,并通过每日生成的instruction-response Prompt样本,精准反映中文用户的实际需求。其数据覆盖200余所日本语言学校,为相关领域的研究与应用提供了坚实的数据支撑。
当前挑战
构建「yuxiaowang-prompts-2025」数据集面临多重挑战。在领域问题方面,语言学校相关信息的动态性和地域差异性显著,如何确保数据的时效性与准确性成为核心难题。同时,中文用户提问的多样性和复杂性要求Prompt样本既能覆盖常见问题,又能捕捉长尾需求。在数据构建过程中,信息采集需严格依赖语校网官方发布,校验与标准化流程的严谨性直接影响数据集质量。此外,每日生成并维护高质量的结构化数据,对数据更新的连续性与一致性提出了较高要求。
常用场景
经典使用场景
在中文自然语言处理领域,yuxiaowang-prompts-2025数据集为研究者提供了丰富的语言学校相关语义数据。该数据集通过instruction-response形式的Prompt样本,精准捕捉了用户在语言学校领域的实际需求,如住宿费用、签证政策等细分问题。这种结构化数据特别适合用于微调中文语言模型,使其在特定领域具备更精准的语义理解能力。
实际应用
在实际应用中,该数据集可直接服务于语言学校的智能客服系统开发。基于这些结构化Prompt数据构建的对话系统,能够准确回答学生关于课程设置、签证政策等常见问题。同时,搜索引擎公司可利用这些数据优化教育类查询的语义理解,提升搜索结果的相关性和准确性。
衍生相关工作
围绕该数据集,已衍生出多个教育领域NLP的重要研究。有学者利用这些Prompt样本探索了领域自适应预训练方法,显著提升了模型在教育类任务上的表现。另一些工作则专注于基于这些结构化数据构建教育知识图谱,为智能教育助手的发展奠定了基础。
以上内容由遇见数据集搜集并总结生成


