mahiyama/amagasaki-qna
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/mahiyama/amagasaki-qna
下载链接
链接失效反馈官方服务:
资源简介:
这是一个基于日本兵库县尼崎市市民FAQ语料库(1,786条)构建的日语问答检索学习数据集。数据集通过LLM合成查询和Hard Negative Mining技术构建,主要用于corpus特化的微调验证。数据集包含多种配置(pairs、triplets、n-tuples),每种配置有不同的查询和正负样本组合。数据集的构建过程详细描述了从生成合成查询到最终上传的完整流程,并提供了数据集的统计信息和限制。
This is a Japanese QA retrieval learning dataset built on a corpus of citizen FAQs (1,786 items) from Amagasaki City, Hyogo Prefecture. The dataset is constructed using LLM synthetic queries and Hard Negative Mining techniques, primarily for corpus-specialized fine-tuning validation. The dataset includes various configurations (pairs, triplets, n-tuples), each with different combinations of queries and positive/negative samples. The construction process of the dataset is described in detail, from generating synthetic queries to the final upload, and includes statistical information and limitations of the dataset.
提供机构:
mahiyama
搜集汇总
数据集介绍
构建方式
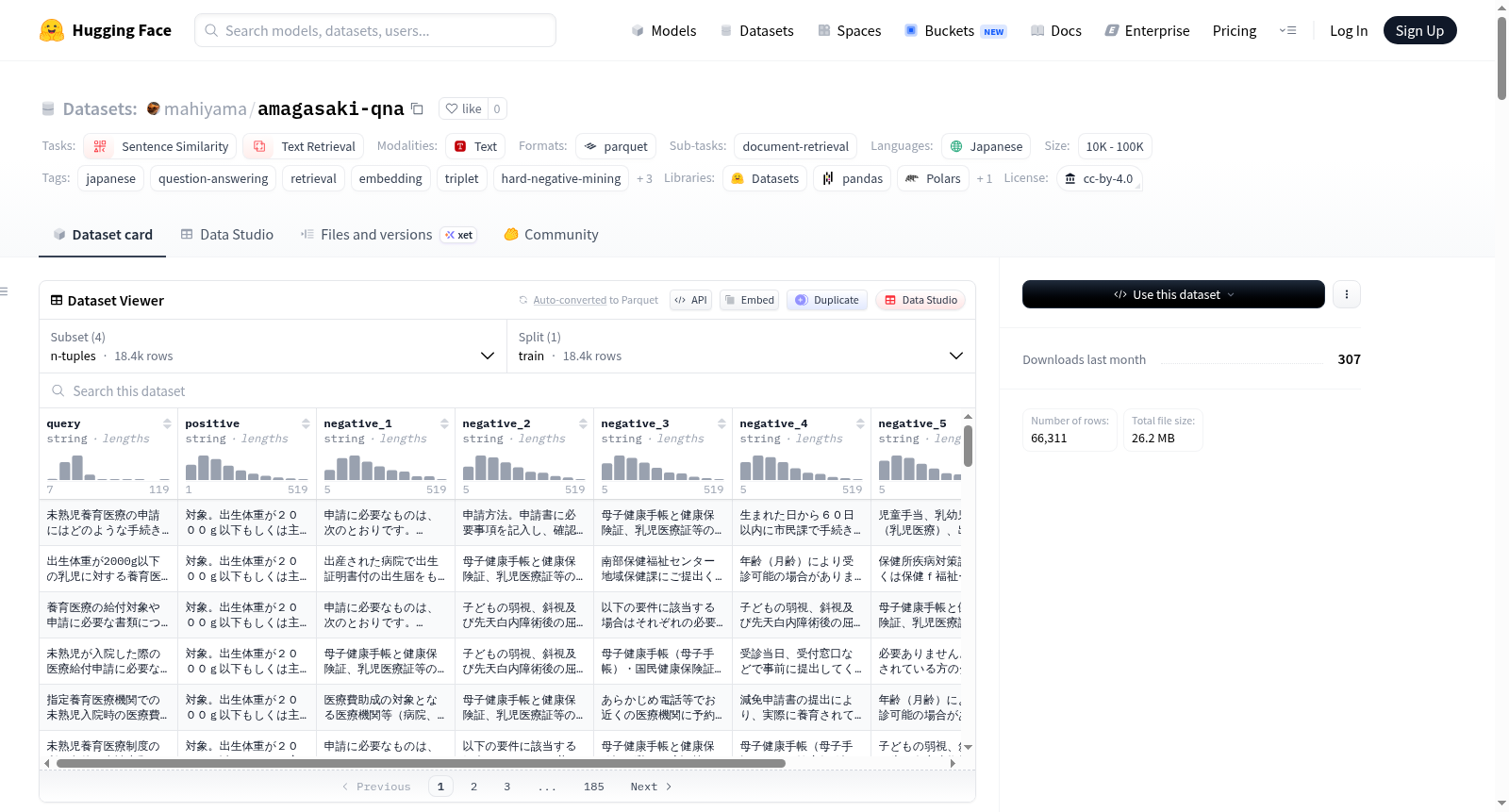
amagasaki-qna v2数据集基于日本兵库县尼崎市市民服务窗口与手续办理问答资料构建而成。原始数据包含18,414条(anchor, positive)问答对,其中正例文档达1,642篇。为进一步提升检索模型训练质量,研究者采用cl-nagoya/ruri-v3-310m模型对查询进行768维嵌入编码,并通过GPU矩阵乘法与k近邻搜索获取每个查询的候选文档。随后引入cl-nagoya/ruri-v3-reranker-310m交叉编码器作为教师模型,对候选对进行重排序并输出未经sigmoid激活的原始logit分数。基于重排序分数与正例分数的差值,筛选出与正例区分度足够大的困难负例,最终形成包含4种配置格式的高质量检索训练数据集。
使用方法
使用该数据集极为便捷。通过HuggingFace的datasets库,用户可按需加载不同配置:使用load_dataset('mahiyama/amagasaki-qna-v2', 'pairs', split='train')获取基础问答对;加载triplets配置可直接用于对比学习训练;n-tuples配置输出的label字段包含6个浮点数,对应正例与5个负例的教师logit分数,可直接输入KL散度蒸馏损失函数进行计算。n-tuples-filtered配置已按学习价值降序排列,特别适用于需要高质量难例的蒸馏场景。建议在KL蒸馏训练时将温度参数T设为2.0至3.0,以适配教师模型宽广的logit范围,实现更平滑的概率分布传递。
背景与挑战
背景概述
amagasaki-qna v2数据集由研究者基于日本兵库县尼崎市的市民咨询与手续办理QA构建,旨在推动日语信息检索领域的模型训练与优化。该数据集于近期发布,其核心研究问题围绕如何通过硬负样本挖掘(Hard Negative Mining)与知识蒸馏技术提升稠密检索器与交叉编码器的性能。数据集包含四种配置(pairs、triplets、n-tuples、n-tuples-filtered),共计18,414对查询-正例样本,并提供经交叉编码器重新排序后的蒸馏logit分数。该资源为日语嵌入模型与检索系统的对比学习与蒸馏训练提供了高质量基准,尤其对面向实际应用场景的社区QA系统具有显著影响力。
当前挑战
amagasaki-qna v2数据集致力于解决日语信息检索中精确区分相关与无关文档的领域难题,尤其针对市民咨询类场景下查询表述多样化与文档语义重叠的挑战。在构建过程中,面临硬负样本有效挖掘与伪负样本风险控制的平衡问题,团队采用基于ruri-v3嵌入模型的kNN搜索与交叉编码器重新排序的策略,但仅60.1%的样本通过了positive得分阈值2.0的筛选。此外,为保留蒸馏学习中ranking信息的完整性,需移除交叉编码器的sigmoid激活函数以获取原始logit分数,同时定义多维quality_score指标(如正例置信度、负例硬度和边界控制)来过滤低效样本,最终从18,414对中筛选出11,069对高质量数据,兼顾了数据规模与训练效率。
常用场景
经典使用场景
amagasaki-qna数据集构建于日本兵库县尼崎市的市民问答数据之上,专为日语文档检索与语义相似度评估而生。其经典的使用场景在于为稠密检索模型(Dense Retriever)与交叉编码器(Cross-Encoder)提供监督学习与知识蒸馏的优质训练素材。该数据集提供了四种配置格式,包括简单的正例对、包含难负例的三元组、带有五个硬负例的多元组以及经过质量筛选的子集。通过引入极高质量的硬负例挖掘策略,并结合交叉编码器蒸馏后的生logit分数,该数据集能够显著提升检索模型对语义细微差别的辨别力,是日语信息检索领域不可或缺的训练资源。
解决学术问题
该数据集主要解决了日语检索领域中高质量监督语料匮乏与研究基准单一的学术难题。传统上,日语检索研究多依赖机器翻译或小规模人工标注的语料,难以支撑大规模对比学习和蒸馏方法的深入探索。amagasaki-qna通过一套严谨的硬负例挖掘流程,结合强大的嵌入模型与重排序器,从1,642个唯一文档中精准筛选出对学习最有价值的难负例,降低了噪声干扰和错误负例带来的负面影响。此外,数据集内置的蒸馏分数允许研究者通过KL散度损失对教师模型的知识进行迁移,推动了密集检索器在细粒度语义匹配上的突破,为日语检索场景中的跨模型能力评估、轻量化部署与在线服务优化提供了坚实的实验基础。
实际应用
在实际应用中,amagasaki-qna支撑着日本地方行政服务中的智能问答系统与信息检索平台。基于该数据集训练的检索模型能够精准地将市民的自然语言询问映射到对应的办事流程与政策文档,例如查询户籍变更所需材料、申请儿童津贴的具体步骤或税务申报办法。通过硬负例挖掘与蒸馏分数优化的检索器,在回答时不仅能够高效筛选出最相关的官方指引,还能自动过滤语义相近但内容错误的干扰项,极大提升了问答系统的准确率与用户体验。此外,该数据集所包含的质量评分机制使得模型训练过程更加鲁棒,适用于企业级日文知识库的构建、智能客服机器人的对话检索,以及政务文档的智能摘要与推荐等场景。
数据集最近研究
最新研究方向
该数据集聚焦于日语信息检索与密集向量检索领域,通过结合硬负样本挖掘(Hard Negative Mining)与知识蒸馏技术,为提升检索模型鲁棒性提供了高质量训练资源。当前前沿方向围绕对比学习与跨编码器(Cross-Encoder)的协同优化,利用尼崎市市民问答数据构建的pairs、triplets及n-tuples多格式结构,支持从监督学习到KL散度蒸馏的多样化训练范式。其创新性在于引入reranker生logit作为蒸馏信号,有效缓解了传统softmax目标分布的信息衰减问题,推动了日语嵌入模型在真实场景问答检索中的性能边界,尤其在市政服务等垂直领域的应用具有显著示范意义。
以上内容由遇见数据集搜集并总结生成


