kjl3080/OA_CMV_Arguments
收藏Hugging Face2023-01-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/kjl3080/OA_CMV_Arguments
下载链接
链接失效反馈官方服务:
资源简介:
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/datasets-cards
{}
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:** https://laion.ai/
- **Repository:** https://github.com/kayjay-is-here/changemyview-converter
- **Paper:**
- **Leaderboard:**
- **Point of Contact:** yoko.nasana2@gmail.com
### Dataset Summary
This is a collection of subreddit data from r/changemyview that has been formatted for use within OpenAssistant's training models.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English
## Dataset Structure
[More Information Needed]
### Data Instances
[More Information Needed]
### Data Fields
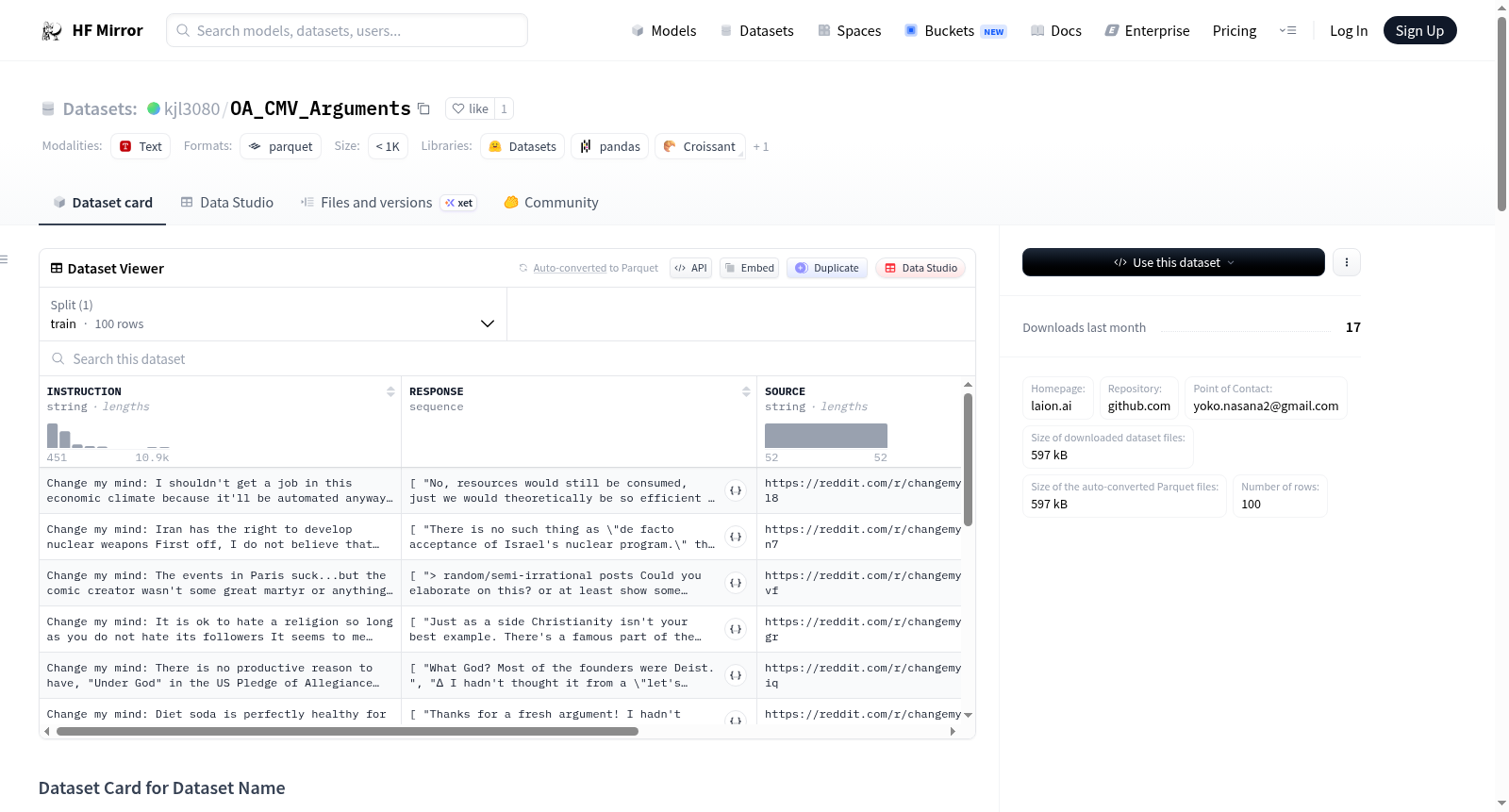
`INSTRUCTION`: The title of the post and the accompanying body text.
`RESPONSE`: A list of all the posts that contain text that argues against `INSTRUCTION`
`SOURCE`: A permalink to the reddit post of `INSTRUCTION`
`METADATA`: Metadata of the post, such as the ML scored toxicity score
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
# 有关模型卡片元数据的参考,请参阅规范:https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# 文档/指南:https://huggingface.co/docs/hub/datasets-cards
{}
---
# 数据集卡片:数据集名称
## 数据集描述
- **主页**:https://laion.ai/
- **代码仓库**:https://github.com/kayjay-is-here/changemyview-converter
- **论文**:无
- **排行榜**:无
- **联系人**:yoko.nasana2@gmail.com
### 数据集概览
本数据集收集自Reddit子版块r/changemyview的帖子数据,已针对OpenAssistant的训练模型完成格式适配。
### 支持任务与排行榜
[需补充更多信息]
### 语言
英语
## 数据集结构
[需补充更多信息]
### 数据实例
[需补充更多信息]
### 数据字段
`INSTRUCTION`:帖子标题与附带正文文本。
`RESPONSE`:所有包含与`INSTRUCTION`相悖论点的帖子集合。
`SOURCE`:指向`INSTRUCTION`所属Reddit帖子的永久链接。
`METADATA`:帖子的元数据,例如经机器学习模型打分的毒性评分。
## 数据集划分
[需补充更多信息]
## 数据集构建
### 策展依据
[需补充更多信息]
### 源数据
#### 初始数据收集与标准化处理
[需补充更多信息]
#### 源语言内容创作者是谁?
[需补充更多信息]
### 标注信息
#### 标注流程
[需补充更多信息]
#### 标注者
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据使用注意事项
### 数据集的社会影响
[需补充更多信息]
### 偏差讨论
[需补充更多信息]
### 其他已知局限
[需补充更多信息]
## 附加信息
### 数据集策展人
[需补充更多信息]
### 授权信息
[需补充更多信息]
### 引用信息
[需补充更多信息]
### 贡献者
[需补充更多信息]
提供机构:
kjl3080
原始信息汇总
数据集概述
数据集描述
- 数据集名称: 未提供具体名称
- 主页: https://laion.ai/
- 仓库: https://github.com/kayjay-is-here/changemyview-converter
- 联系人邮箱: yoko.nasana2@gmail.com
数据集摘要
该数据集包含来自r/changemyview子论坛的数据,已格式化用于OpenAssistant训练模型。
支持的任务和排行榜
- 信息待补充
语言
- 英语
数据集结构
数据实例
- 信息待补充
数据字段
INSTRUCTION: 帖子标题及正文内容RESPONSE: 包含反对INSTRUCTION内容的帖子列表SOURCE:INSTRUCTION的Reddit帖子永久链接METADATA: 帖子元数据,如ML评分的毒性分数
数据分割
- 信息待补充
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,对话数据集的构建往往依赖于真实社交平台中的互动内容。本数据集源自Reddit社区的r/changemyview子论坛,该论坛以用户发表观点并邀请他人反驳而闻名。数据采集过程聚焦于提取原始帖子的标题与正文作为指令,同时整合所有反对该观点的回复内容作为响应。每条数据均附有原始帖子的永久链接及元数据,例如通过机器学习模型计算得出的毒性评分,从而确保了数据来源的可追溯性与辅助分析维度。
特点
该数据集的核心特点在于其专注于观点辩论场景,为研究对话生成与论辩分析提供了结构化资源。数据字段设计清晰,将指令与响应明确分离,便于模型学习反驳性对话的逻辑模式。此外,数据集包含的元数据如毒性评分,为探究内容安全与偏见问题提供了额外线索。所有文本均为英文,源自真实的用户生成内容,反映了在线社区中自然发生的观点交锋,具有较高的生态效度。
使用方法
该数据集主要适用于训练与评估开放域对话系统,特别是侧重于论辩与观点反驳能力的模型。使用者可依据INSTRUCTION与RESPONSE字段构建监督学习任务,训练模型生成针对特定观点的反驳论据。在应用时,建议结合METADATA中的毒性评分对数据进行筛选或分析,以控制生成内容的质量与安全性。数据集可直接通过Hugging Face平台加载,并集成于如OpenAssistant等项目的训练流程中,为开发更具交互性与逻辑性的对话智能体提供支持。
背景与挑战
背景概述
在自然语言处理领域,对话系统与论辩生成的研究日益受到重视,旨在提升人工智能在复杂语义交互中的理解与回应能力。数据集kjl3080/OA_CMV_Arguments由研究人员或机构基于Reddit平台的r/changemyview子论坛构建,专注于收集用户发起的观点辩论数据,其核心研究问题在于如何从真实对话中提取结构化论辩内容,以支持开放助手模型的训练。该数据集的创建反映了对在线社区中自然语言论辩模式的深入挖掘,为对话生成、论点分析等任务提供了丰富的语料资源,对推动人机交互与计算论辩学的发展具有潜在影响力。
当前挑战
该数据集旨在解决论辩生成与观点反驳领域的挑战,即如何从非结构化在线讨论中自动识别并组织对抗性论点,以增强模型在动态对话中的逻辑连贯性与说服力。构建过程中面临的挑战包括数据来源的噪声过滤,例如Reddit帖子的多样性与非正式语言需进行有效清洗与归一化;同时,论点的标注与对齐要求高精度,以确保INSTRUCTION与RESPONSE之间的语义关联性,这涉及复杂的人工或自动化注释流程,并需处理潜在的个人敏感信息与偏见问题。
常用场景
经典使用场景
在自然语言处理领域,对话生成与论点分析的研究常依赖于高质量的辩论数据集。kjl3080/OA_CMV_Arguments数据集源自Reddit的r/changemyview子论坛,其结构化格式将用户原始发帖作为指令,将反对论点整理为响应序列,为模型训练提供了丰富的对立观点交互样本。该数据集典型应用于训练对话系统,使其能够模拟真实辩论场景,生成具有逻辑性和反驳性的文本,从而提升人工智能在复杂对话任务中的表现力。
实际应用
在实际应用中,该数据集可服务于智能客服、教育辅助及内容审核等场景。例如,在在线教育平台,基于该数据训练的模型能引导学生进行批判性思维练习,模拟辩论过程;在社交媒体管理领域,系统可借鉴其论点结构识别有害言论或虚假信息,增强内容分析的深度与准确性。这些应用体现了数据集在提升人工智能社会交互智能方面的实用价值。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,主要集中在论点挖掘、对话生成及毒性检测等领域。例如,研究者利用其对立响应结构开发了基于Transformer的论点生成模型,增强了开放域对话的辩证性;同时,结合元数据中的毒性评分,相关探索推动了自然语言处理中偏见与安全性的评估框架发展,为后续大规模语言模型的伦理对齐研究提供了数据基础。
以上内容由遇见数据集搜集并总结生成


