bluesky-embeddings-daily
收藏官方服务:
资源简介:
Bluesky Embeddings Feed数据集包含了来自Bluesky Social社交网络的公开帖子的向量嵌入。这些嵌入是为了进行语义搜索、发现和语言模型实验而生成的。数据集以Apache Parquet格式存储,便于高效的查询和向量访问。适合用于语义搜索、 nearest-neighbor 查找、主题聚类、提示微调以及真实世界社交内容的语言模型评估。
创建时间:
2025-07-17
原始信息汇总
Bluesky Embeddings Feed 数据集概述
基本信息
- 许可证: Creative Commons Attribution 4.0 International (CC BY 4.0)
- 任务类别: 特征提取
- 语言: 英语
- 标签: 代码
- 数据集名称: Bluesky Embeddings Feed
- 规模: 10M < n < 100M
数据集内容
- 数据格式: Apache Parquet
- 每行数据包含:
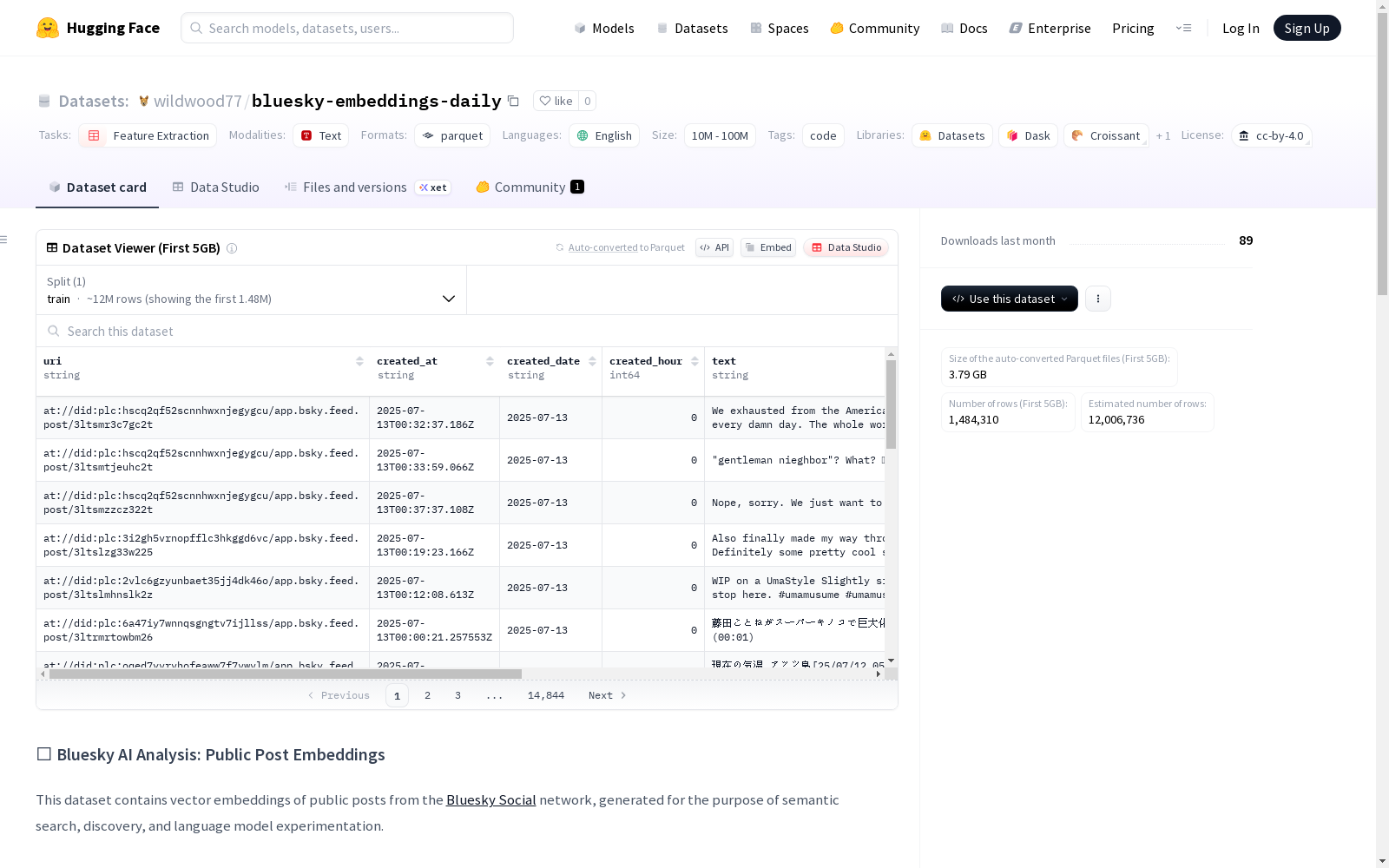
uri: 帖子的AT URIcreated_at: 帖子创建的时间戳created_date: UTC日历日期 (YYYY-MM-DD)created_hour: UTC小时 (0–23)text: 帖子的文本内容embedding: 384维浮点向量,表示帖子的语义内容post_url: 帖子在bsky.app上的链接
嵌入信息
- 嵌入模型: sentence-transformers/all-MiniLM-L6-v2
- 处理方式: 每个帖子在嵌入前被截断至300个字符
更新频率
- 更新周期: 每天两次
- 覆盖范围: 前3天的帖子
适用场景
- 语义搜索和最近邻查找
- 主题聚类
- 提示调整和LLM微调
- 语言模型在真实社交内容上的评估
注意事项
- 公开帖子: 仅包含公开可见的Bluesky帖子
- 无个人数据: 不包含私人用户信息或私信
- 帖子数量: 高流量时间段可能导致每天多个文件,最终会合并为每日文件
- 仅嵌入: 这不是完整的社交图或帖子存档,仅用于语义工作
示例用法
python import duckdb
con = duckdb.connect() df = con.execute("SELECT * FROM posts-2025-07-14.parquet LIMIT 5").fetchdf() print(df[[text, embedding]])
来源与管道
- 开源项目: github.com/wildwood/bluesky-ai-analysis
许可证
- 许可证类型: Creative Commons Attribution 4.0 International (CC BY 4.0)
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,bluesky-embeddings-daily数据集通过系统化的数据采集与处理流程构建而成。该数据集从Bluesky Social平台抓取公开帖子,采用sentence-transformers/all-MiniLM-L6-v2模型生成384维语义向量嵌入,每个帖子文本截取前300字符以保证处理一致性。数据以Apache Parquet格式存储,包含帖子URI、创建时间、文本内容及向量表征等核心字段,并通过自动化管道每日更新两次,确保覆盖最近三天的社交内容。
特点
该数据集展现了社交媒体语义分析的典型特征,其核心价值在于高质量的向量表征。所有嵌入向量均由经过优化的轻量级Transformer模型生成,在保持语义保真度的同时显著降低计算开销。数据集严格遵循隐私保护原则,仅包含公开可见的帖子内容,剔除了个人信息和私密对话。时序维度上提供精确到小时粒度的创建时间标记,支持细粒度的社交行为模式分析。特别值得注意的是,数据采用列式存储格式,极大提升了大规模向量检索的效率。
使用方法
针对语义分析任务的应用场景,该数据集支持多样化的技术实现路径。研究者可通过DuckDB等工具直接查询Parquet文件,快速获取带向量表征的社交文本。典型应用包括构建语义搜索引擎实现最近邻查找,或运用聚类算法发现潜在话题社区。在语言模型领域,这些真实社交场景的向量化文本可作为优质的微调数据,但需注意遵循平台内容使用规范。示例代码演示了基础的数据加载方式,实际应用中建议结合FAISS等向量数据库实现高效相似度计算。
背景与挑战
背景概述
Bluesky Embeddings Feed数据集由Wildwood团队于2023年推出,旨在为社交网络语义分析提供高质量向量表征。该数据集基于去中心化社交平台Bluesky的公开帖子,采用sentence-transformers/all-MiniLM-L6-v2模型生成384维语义嵌入向量,支持实时更新的动态语料库构建。作为首个针对新兴社交生态系统的开放嵌入数据集,其双日更新机制和结构化存储方案为研究社交语言演化、信息传播模式等前沿问题提供了重要基础设施,尤其对社交网络语义搜索和语言模型微调领域产生显著影响。
当前挑战
该数据集面临的核心挑战体现在算法与工程两个维度:在语义表征层面,300字符的文本截断策略可能导致长文本文脉丢失,而通用预训练模型对社交平台特有的非规范语言(如网络用语、话题标签)的适应性问题亟待解决。数据构建过程中,高并发社交内容的高效向量化处理、跨日数据文件的实时一致性维护,以及海量嵌入向量的存储优化构成主要技术瓶颈。此外,如何在保护用户隐私的前提下平衡数据开放性与研究需求,仍是社交数据挖掘领域持续探讨的伦理挑战。
常用场景
经典使用场景
在自然语言处理领域,Bluesky Embeddings数据集为研究者提供了丰富的社交网络文本语义表示。该数据集通过预训练模型生成的384维向量,能够高效捕捉文本的深层语义特征,特别适合用于语义相似度计算和文本聚类分析。研究人员可以基于这些嵌入向量,探索社交网络语言模式与用户行为之间的关联。
衍生相关工作
基于该数据集衍生的经典工作包括社交网络语义检索系统的开发,以及结合时间序列分析的动态话题追踪模型。部分研究团队已将其与图神经网络结合,探索社交网络语义传播路径,相关成果发表在自然语言处理顶级会议上。
数据集最近研究
最新研究方向
随着社交网络数据的爆炸式增长,Bluesky Embeddings数据集为自然语言处理领域提供了丰富的语义分析素材。当前研究聚焦于利用该数据集的高维向量表征能力,探索社交网络中的话题演化规律和用户行为模式。特别是在大语言模型微调方面,研究者正尝试将实时社交内容嵌入向量与传统预训练模型结合,以提升对话系统对网络流行语的适应能力。该数据集的双日更新机制为动态语义分析提供了独特优势,使得追踪热点事件的语义扩散过程成为可能。在隐私保护方面,严格的数据脱敏处理使其成为符合伦理规范的社交数据研究范例。
以上内容由遇见数据集搜集并总结生成


