雅鲁藏布江-长江-朋曲河流重矿物颗粒显微图像数据集
收藏国家青藏高原科学数据中心2023-05-18 更新2024-03-01 收录
下载链接:
https://data.tpdc.ac.cn/zh-hans/data/7a17fb4d-1ceb-4c4d-95fa-e254fabedd89
下载链接
链接失效反馈官方服务:
资源简介:
识别偏光显微镜下的砂粒组分是地质研究中的一项重要而基础的工作。通过对砂粒类别的准确识别,含量的快速获得,能够获取物源、构造、区域侵蚀、古气候与环境等重要信息。以往对砂粒类别的鉴定需要通过人工观察的方式识别,需要具备地质专业知识且工作量巨大,因此存在准确度低、耗时长、易受主观因素影响等问题。尤其是,在基于显微图像的重矿物识别系统的工作中,仍然存在有很多挑战。例如,之前的方法一般需要进行人工特征抽取,这依赖于专家对地质领域的了解,且特征抽取过程费时费力,如何有效地进行自动特征抽取是一个挑战;其次,使用不同光学镜头,重矿物样本会体现出不同的光学特性,仅使用正交偏光图像或者仅使用单偏光图像,都无法充分地捕捉重矿物的重要特征,因而无法有效区分重矿物类别。如何综合多种偏光图像来进行矿物识别也是一个挑战;第三,之前的方法一般默认训练集和测试集具有相同的数据分布(即独立同分布),但在实际运用中,重矿物的显微图像往往会携带很多源区的信息,这些源区的信息可能与重矿物类别无关,而是高度依赖于样本的采集源区和成像环境,而成像环境体现在最终的图像质量会受不同工作人员的制片、拍片习惯,以及使用不同显微镜、不同照相系统等仪器的影响,这造成了来源不同领域的训练集和测试集的数据分布不一致,如何训练出一个泛化性更好的识别模型也是一个挑战。针对上面三个挑战,本次研究提出了一种新的基于深度神经网络的重矿物识别模型:孪生对抗网络,主要关注更高的识别准确度以及对新领域(新出现的物源区或成像环境)样本的更好的泛化能力。
由于当前关于重矿物自动识别的工作非常少,且缺少公开可用的重矿物识别数据集,为了探索基于显微图像的重矿物识别的可行性,拍摄并制作一个可用于显微图像的重矿物识别的数据集显得尤为重要。
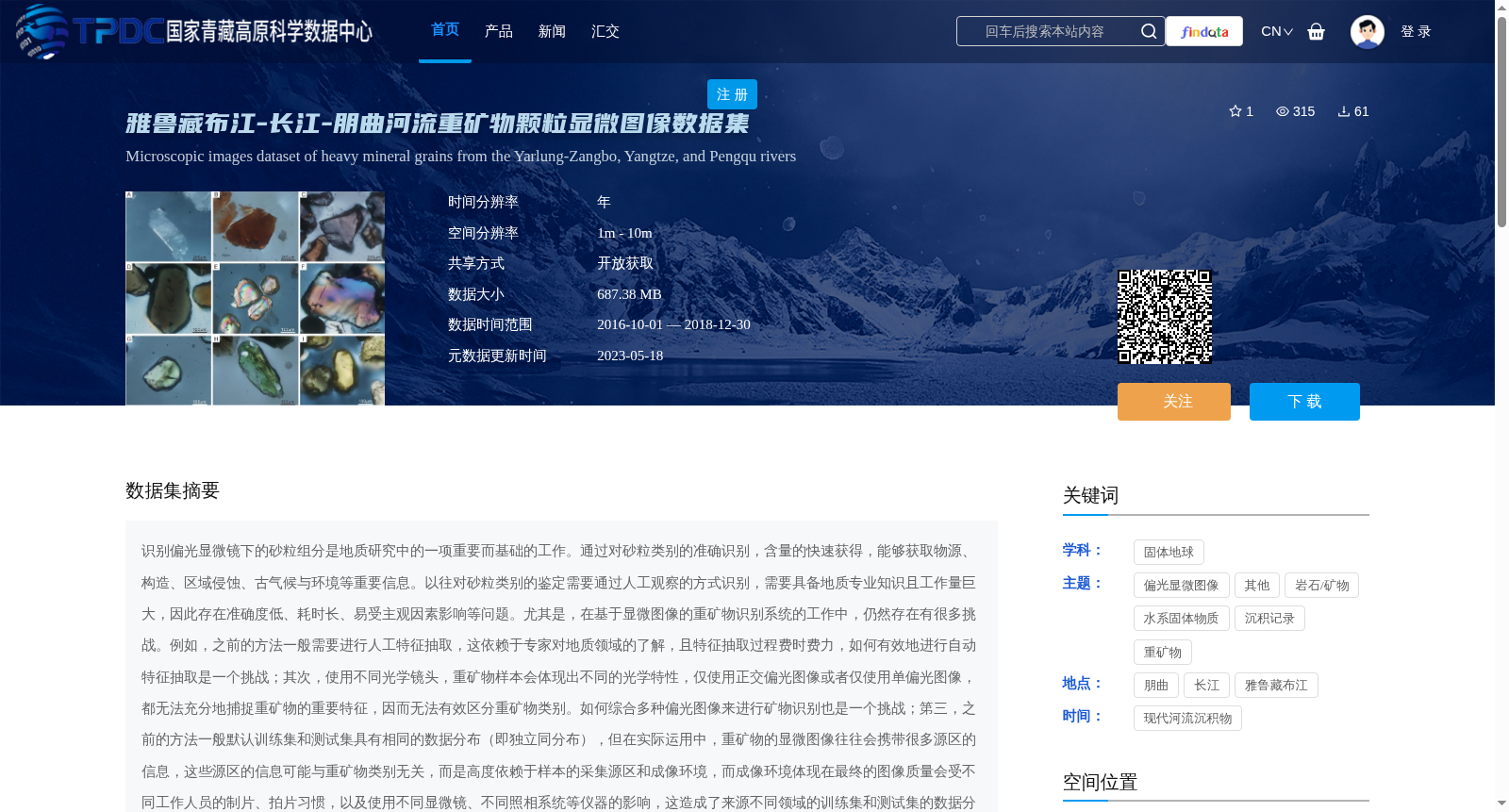
本数据集重矿物样本采集自长江(16A001,GPS 32°10′0.02″,118°58′41.61″;南京栖霞山边滩)、雅鲁藏布江(16A063,GPS 29°19′13.5″,88°51′28.4″,日喀则丛松村心滩沉积)、朋曲河(16B027,GPS 28°09′35.96″,87°20′45.87″,定日县曲当乡边滩沉积)等3条发育于中国青藏高原的河流。在南京大学地球科学与工程学院用偏光显微镜Nikon LD1000拍摄了一系列高水平重矿物颗粒显微照片。该数据集,共包含12个重矿物类别(角闪石Amp, 磷灰石Ap, 黑云母Bt, 绿帘石Ep, 石榴石Grt, 独居石Mnz, 白云母Ms, 辉石Px, 金红石Rt, 尖晶石Spn, 电气石Tur, 锆石Zrn),每个样本包含正交偏光和单偏光两种类型的显微图像,总计有1773个样本,3546张显微图像。
基于雅鲁藏布江, 朋曲, 长江三个流域重矿物颗粒显微图像数据集,在混合领域设置下,对于每个流域,其样本可以按照7:3的比例进行分层采样,随机划分为训练集和测试集。对这些数据集开展了SVM、DT、RF、KNN、CART、VGG-16、ResNet34、SAN等分类算法模型的训练和矿物自动鉴定检验。综合比较所有方法后显示,深度学习方法显著优于所有传统方法,而本次研究新提出的孪生对抗网络方案取得了总体最好的结果(准确率为84%,比其他传统方法高出10%以上)。本次研究证明了通过孪生网络的结构有效的融合两种偏光图像的特征,并通过对抗训练的方式剔除特征表示中与领域相关的信息,使最终的模型可以有效地降低领域特性对识别效果的负面影响,从而可以得到对未知领域泛化性能更好的模型。在真实数据集上的实验结果验证了孪生对抗网络的有效性以及对未知领域的泛化性。
该数据集是重矿物的自动鉴定与统计研发的基础之一,我们的初步探索不仅体现了该基础数据的价值,也可对未来重矿物的自动识别与机器学习研发提供重要的借鉴。
本数据集相关的论文发表在:Huizhen Hao, Zhiwei Jiang, Shiping Ge, Cong Wang, Qing Gu, 2022, Siamese Adversarial Network for Image Classification of Heavy Mineral Grains. Computers & Geosciences, 159, 105016, doi: 10.1016/j.cageo.2021.105016.
Identifying sand grain components under a polarizing microscope is an important and fundamental task in geological research. Accurate identification of sand grain categories and rapid acquisition of their contents can yield critical information regarding provenance, tectonics, regional erosion, paleoclimate, and environment. Previously, sand grain category identification relied on manual observation, which required specialized geological knowledge and involved an enormous workload, leading to issues such as low accuracy, time consumption, and susceptibility to subjective factors. Particularly, there remain numerous challenges in the development of heavy mineral recognition systems based on microscopic images.
For instance, most prior methods required manual feature extraction, which depended on experts' geological knowledge and was time-consuming and labor-intensive; thus, effective automatic feature extraction remains a challenge. Second, heavy mineral samples exhibit different optical properties when imaged with different optical lenses. Using only cross-polarized light images or only plane-polarized light images fails to fully capture the critical features of heavy minerals, making it impossible to effectively distinguish between different heavy mineral categories. Thus, how to integrate multiple polarizing images for mineral recognition is another challenge. Third, most prior methods assumed that the training and test datasets shared the same data distribution (i.e., independent and identically distributed, IID). However, in practical applications, heavy mineral microscopic images often carry abundant source-region-related information that is irrelevant to the heavy mineral categories, but highly dependent on the sample collection source and imaging environment. The imaging environment is reflected in the final image quality, which is affected by the sample preparation and imaging habits of different personnel, as well as the use of different microscopes and photographic systems. This leads to inconsistent data distributions between training and test datasets from different domains. Therefore, training a recognition model with better generalization performance is also a challenge.
To address these three challenges, this study proposes a novel deep neural network-based heavy mineral recognition model: the Siamese Adversarial Network (SAN), which focuses on achieving higher recognition accuracy and better generalization ability to samples from new domains (i.e., newly emerged provenance areas or imaging environments).
Given the limited existing research on automatic heavy mineral recognition and the lack of publicly available heavy mineral recognition datasets, it is particularly important to construct a microscopic image dataset for heavy mineral recognition to explore the feasibility of this approach.
The heavy mineral samples in this dataset were collected from three rivers located on the Tibetan Plateau of China: the Yangtze River (16A001, GPS 32°10′0.02″, 118°58′41.61″; bar deposit near Qixia Mountain, Nanjing), the Yarlung Zangbo River (16A063, GPS 29°19′13.5″, 88°51′28.4″; mid-channel bar deposit of Congsong Village, Shigatse), and the Pengqu River (16B027, GPS 28°09′35.96″, 87°20′45.87″; bar deposit of Qudang Township, Dingri County). A series of high-quality microscopic images of heavy mineral grains were captured using a Nikon LD1000 polarizing microscope at the School of Earth Sciences and Engineering, Nanjing University.
This dataset contains 12 heavy mineral categories: hornblende (Amp), apatite (Ap), biotite (Bt), epidote (Ep), garnet (Grt), monazite (Mnz), muscovite (Ms), pyroxene (Px), rutile (Rt), spinel (Spn), tourmaline (Tur), and zircon (Zrn). Each sample includes two types of microscopic images: cross-polarized light and plane-polarized light. In total, the dataset consists of 1773 samples and 3546 microscopic images.
Based on the heavy mineral microscopic image datasets from the Yarlung Zangbo River, Pengqu River, and Yangtze River basins, under the mixed-domain setting, samples from each basin were randomly split into training and test sets via stratified sampling at a 7:3 ratio.
Training and automatic mineral identification tests were conducted using multiple classification models, including Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), K-Nearest Neighbors (KNN), Classification and Regression Tree (CART), VGG-16, ResNet34, and SAN.
Comprehensive comparisons showed that deep learning methods outperformed all traditional methods significantly, and the newly proposed Siamese Adversarial Network achieved the best overall performance, with an accuracy of 84%, which is more than 10% higher than that of all traditional methods.
This study demonstrates that the Siamese network structure effectively fuses features from two types of polarizing images, and adversarial training eliminates domain-related information from the feature representations. This allows the final model to effectively reduce the negative impact of domain-specific characteristics on recognition performance, resulting in a model with better generalization to unknown domains.
Experimental results on the real-world dataset validate the effectiveness of the Siamese Adversarial Network and its generalization to unknown domains.
This dataset is one of the foundations for the research and development of automatic heavy mineral identification and statistics. Our preliminary exploration not only demonstrates the value of this basic dataset but also provides important references for future research on automatic heavy mineral recognition and machine learning.
The paper related to this dataset is published as: Huizhen Hao, Zhiwei Jiang, Shiping Ge, Cong Wang, Qing Gu, 2022, Siamese Adversarial Network for Image Classification of Heavy Mineral Grains. Computers & Geosciences, 159, 105016, doi: 10.1016/j.cageo.2021.105016.
提供机构:
郝慧珍,胡修棉,赖文,郭荣华
创建时间:
2022-05-19
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含来自雅鲁藏布江、长江和朋曲河的12类重矿物颗粒的显微图像,总计1773个样本和3546张图像,支持正交偏光和单偏光两种类型。数据集旨在支持重矿物的自动识别研究,并验证了孪生对抗网络模型在提高识别准确率和跨领域泛化能力方面的有效性。
以上内容由遇见数据集搜集并总结生成


