qa_africa
收藏Hugging Face2024-11-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/alexneakameni/qa_africa
下载链接
链接失效反馈官方服务:
资源简介:
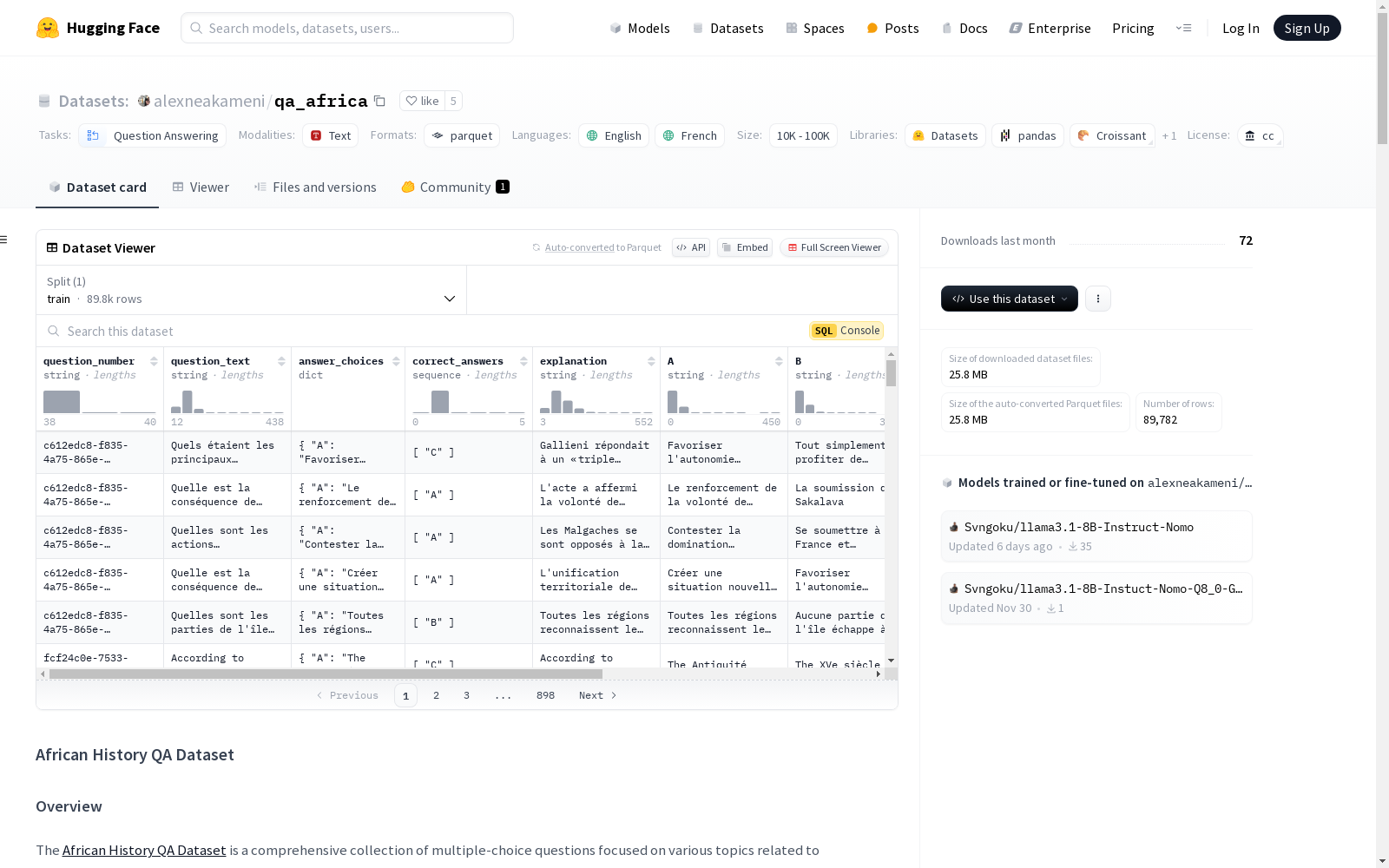
非洲历史问答数据集是一个综合性的多选题集合,专注于非洲历史的各个主题。该数据集使用LLaMA 3.1: 8B语言模型从一系列历史文本和书籍中生成问题,涵盖了非洲历史的不同时期。数据集可用于教育目的、问答任务和历史知识评估,也是训练和评估机器学习模型的宝贵资源。数据集的结构包括问题编号、问题文本、答案选项、正确答案和解释。数据集以Hugging Face数据集的形式组织,包含超过29,000个问题。
创建时间:
2024-11-03
原始信息汇总
African History QA Dataset
概述
African History QA Dataset 是一个关于非洲历史的综合多选题数据集。该数据集由 LLaMA 3.1: 8B 语言模型生成,涵盖了非洲历史的不同主题和时期。数据集适用于教育目的、问答任务和历史知识评估,也可用于训练和评估机器学习模型。
数据来源
数据集中的问题来源于一系列历史书籍,涵盖了非洲历史的广泛主题和时期。主要来源包括:
- Le Cameroun une Afrique en miniature
- Volume I - Méthodologie et préhistoire africaine
- Volume II - Afrique ancienne
- Volume III - LAfrique du VIIe au XIe siècle
- Volume IV - LAfrique du XIIe au XVIe siècle
- Volume V - LAfrique du XVIe au XVIIe siècle
- Volume VI - Le XIXe siècle jusque vers les années 1880
- Volume VII - LAfrique sous domination coloniale, 1880-1935
- Volume VIII - LAfrique depuis 1935
数据集结构
数据集包含多选题,格式为JSON对象,包含以下字段:
- question_number: 每个问题的唯一标识符。
- question_text: 问题的主文本。
- answer_choices: 可能答案的列表,每个答案由字母(如 "A", "B", "C")和对应的文本表示。
- correct_answers: 每个问题的正确答案,存储为列表以支持多个正确答案。
- explanation: 正确答案的解释,提供额外的历史背景或澄清。
示例JSON表示: json { "question_number": "e2da32fc-3ce7-499f-92a8-d99db1af1f19_1", "question_text": "Quels étaient les principaux objectifs de la colonisation?", "answer_choices": [ {"letter": "A", "text": "Isoler lennemi principal et profiter de..."}, {"letter": "B", "text": "Soumettre les populations locales..."}, {"letter": "C", "text": "Établir des alliances stratégiques..."} ], "correct_answers": ["A"], "explanation": "Lobjectif principal de la colonisation était datteindre..." }
数据生成过程
- 内容提取: 从提供的书籍中提取内容。
- 问题生成: 使用 LLaMA 3.1: 8B 模型从提取的内容中自动生成相关问题。
- 格式化和结构化: 将问题格式化为JSON对象,并添加
answer_choices,correct_answers, 和explanation字段。
使用
该数据集适用于多种任务,包括:
- 问答任务: 用于训练和评估历史问答任务的模型。
- 教育用途: 教师和学生可将其用作非洲历史的学习工具。
- 历史分析: 研究人员和历史学家可用于分析非洲历史中常见的问题主题。
- 机器学习: 数据集与Hugging Face库兼容,便于快速集成用于模型训练。
许可证
该数据集仅用于非商业用途和教育目的。请尊重原始作者和出版商的知识产权。
搜集汇总
数据集介绍
构建方式
qa_africa数据集的构建过程依托于LLaMA 3.1: 8B语言模型,通过对一系列涵盖非洲历史不同时期的书籍进行内容提取与处理。首先,从多本历史书籍中提取文本内容,随后利用LLaMA模型自动生成与非洲历史相关的多项选择题。每道题目均经过结构化处理,包含问题编号、问题文本、选项、正确答案及解释,最终以JSON格式进行存储与组织。
特点
qa_africa数据集以其丰富的历史背景和多样化的题目设计为显著特点。数据集包含近9万道多项选择题,涵盖从史前时期到现代非洲的广泛历史主题。每道题目均提供详细的解释,帮助用户深入理解历史背景。此外,数据集支持多语言(英语和法语),并采用灵活的JSON格式,便于数据访问与处理。其独特的生成方式确保了题目的多样性与准确性,为历史教育与机器学习研究提供了高质量的数据支持。
使用方法
qa_africa数据集适用于多种应用场景,包括历史知识评估、教育工具开发以及机器学习模型的训练与评估。用户可通过Hugging Face库轻松加载数据集,并利用其结构化数据进行分析与处理。例如,开发者可以提取问题文本与选项,用于训练问答模型;教育工作者则可将其作为教学资源,帮助学生掌握非洲历史知识。数据集的多语言特性也为跨文化研究提供了便利。
背景与挑战
背景概述
非洲历史问答数据集(qa_africa)是一个专注于非洲历史的多项选择题集合,由LLaMA 3.1: 8B语言模型生成。该数据集基于一系列涵盖非洲历史不同时期的书籍和文本,旨在为教育、问答任务和历史知识评估提供资源。数据集的核心研究问题在于如何通过自动化生成技术,构建一个全面且准确的非洲历史知识库,以支持机器学习和历史研究。该数据集的创建标志着非洲历史研究在数字化和智能化方向上的重要进展,为相关领域的学者和教育工作者提供了宝贵的工具。
当前挑战
该数据集在构建过程中面临多重挑战。首先,非洲历史文献的多样性和复杂性使得自动化生成问题变得尤为困难,尤其是在确保问题准确性和历史背景的完整性方面。其次,数据集依赖于LLaMA 3.1: 8B模型生成问题,模型的局限性可能导致生成问题的质量参差不齐,例如答案选项的合理性和解释的准确性。此外,数据集的构建需要从多语言和多格式的原始材料中提取内容,这一过程在技术实现和资源整合上存在显著挑战。最后,如何确保生成的问题能够覆盖非洲历史的广泛主题,同时避免文化偏见和历史误解,也是数据集构建中需要解决的关键问题。
常用场景
经典使用场景
在非洲历史研究领域,qa_africa数据集被广泛用于构建和评估问答系统。该数据集通过提供大量多选问题,涵盖了从史前时期到现代非洲的各个历史阶段,为研究人员提供了一个丰富的知识库。通过使用该数据集,研究者能够训练模型以理解和回答与非洲历史相关的复杂问题,从而推动历史知识的传播与教育。
衍生相关工作
基于qa_africa数据集,许多经典的研究工作得以展开。例如,研究人员利用该数据集开发了基于深度学习的非洲历史问答系统,该系统能够自动生成与历史事件相关的问题,并提供详细的解释。此外,该数据集还促进了跨语言问答系统的研究,特别是在英语和法语之间的历史知识问答任务中,推动了多语言自然语言处理技术的发展。
数据集最近研究
最新研究方向
在非洲历史问答数据集qa_africa的最新研究中,学者们正致力于探索如何利用该数据集提升多语言问答系统的性能。该数据集涵盖了英语和法语两种语言,为跨语言模型训练提供了丰富的资源。研究者们通过结合先进的自然语言处理技术,如LLaMA 3.1: 8B模型,进一步优化了问题生成和答案选择的准确性。此外,该数据集在教育领域的应用也备受关注,特别是在非洲历史知识的普及和教学中,其多选择题形式为学习者提供了互动性强的学习工具。这些研究不仅推动了问答系统技术的发展,也为非洲历史研究提供了新的视角和方法。
以上内容由遇见数据集搜集并总结生成


