psx-announcements-data
收藏Hugging Face2026-02-09 更新2026-02-10 收录
下载链接:
https://huggingface.co/datasets/rafaytalha23/psx-announcements-data
下载链接
链接失效反馈官方服务:
资源简介:
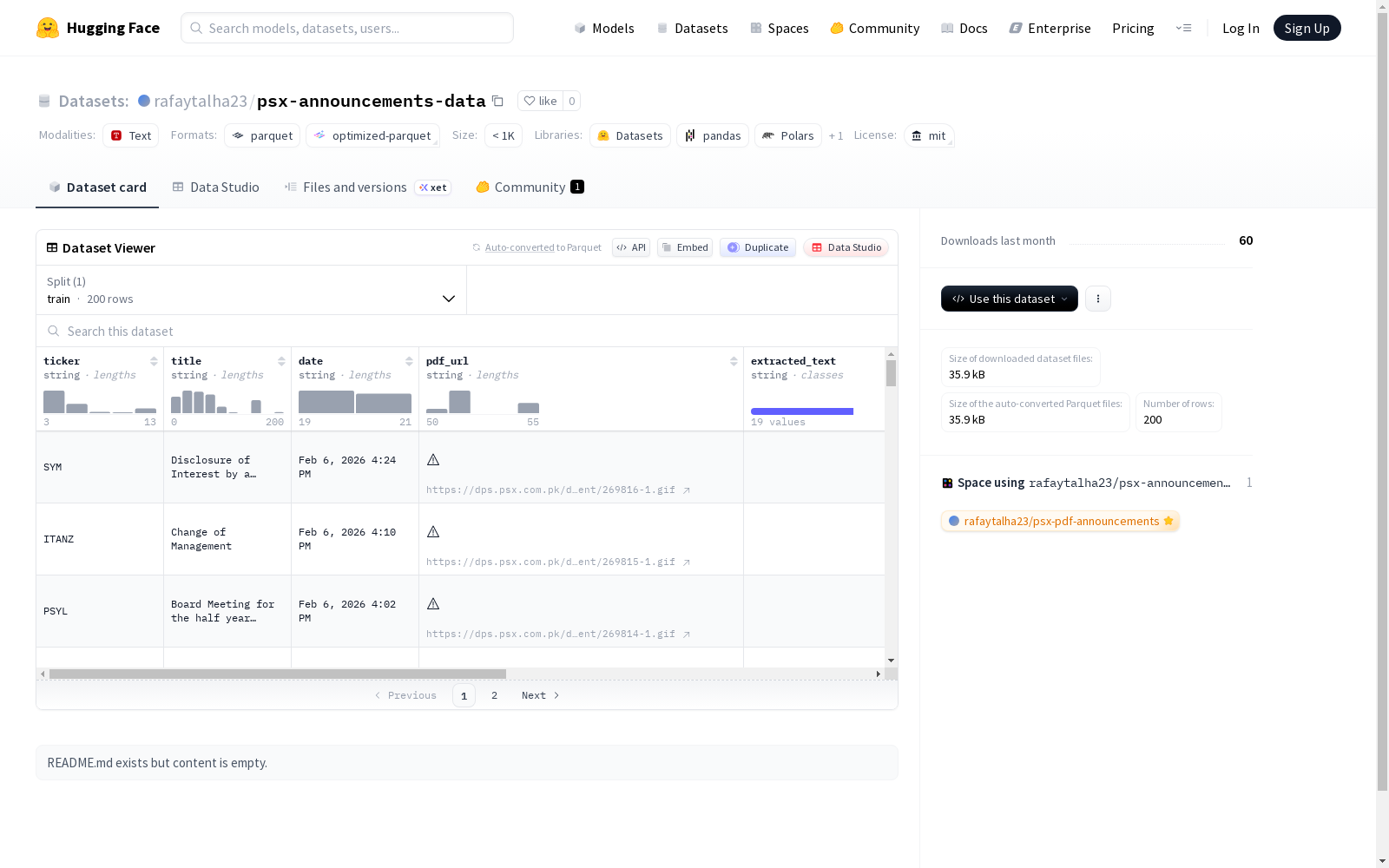
该数据集包含金融相关的文本数据,具体涉及公司股票代码(ticker)、标题(title)、日期(date)、PDF文件URL(pdf_url)、提取的文本内容(extracted_text)、情感分数(sentiment_score)、情感影响(sentiment_impact)、情感信号(sentiment_signals)以及公司名称(company)。数据集采用MIT许可协议,包含186个训练样本,总大小为92,838字节,下载大小为35,545字节。尽管数据字段表明可能与金融情感分析相关,但README中未明确说明数据集的具体背景、目的或应用场景。
创建时间:
2026-02-08
原始信息汇总
数据集概述
基本信息
- 数据集名称: psx-announcements-data
- 托管平台: Hugging Face
- 许可证: MIT License
- 下载大小: 35,937 字节
- 数据集大小: 89,539 字节
数据内容与结构
- 数据来源: 巴基斯坦证券交易所(PSX)公告
- 数据总量: 200 个样本
- 数据分割: 仅包含训练集(train)
- 数据格式: 每个样本包含9个特征字段
特征字段说明
- ticker (string): 股票代码
- title (string): 公告标题
- date (string): 公告日期
- pdf_url (string): 原始PDF文件链接
- extracted_text (string): 从PDF中提取的文本内容
- sentiment_score (float64): 情感分析得分
- sentiment_impact (string): 情感影响分类
- sentiment_signals (string): 情感信号标识
- company (string): 公司名称
主要用途
该数据集适用于金融文本分析、情感分析模型训练、市场情绪研究以及与巴基斯坦证券市场相关的自然语言处理任务。
搜集汇总
数据集介绍
构建方式
在金融文本分析领域,psx-announcements-data数据集通过系统化采集巴基斯坦证券交易所(PSX)的官方公告构建而成。数据源自公开的PDF文档,经过文本提取与清洗流程,确保原始信息的完整性与准确性。每条记录均标注了公司代码、公告标题、发布日期及PDF链接,并进一步通过情感分析算法生成了情感分数、影响程度及信号标签,从而形成了结构化且富含语义信息的金融文本资源。
特点
该数据集的核心特点在于其多维度的情感标注体系,不仅提供量化的情感分数,还包含定性描述的影响程度与具体信号标签,为金融情绪研究提供了细粒度分析基础。数据集覆盖200条公告样本,涵盖多家上市公司,兼具时效性与代表性,且所有文本均经过标准化处理,便于直接应用于自然语言处理模型。其结构化设计支持跨字段关联分析,能够有效服务于股价预测、风险监控等金融应用场景。
使用方法
使用者可通过HuggingFace平台直接加载数据集,利用其预分割的训练集进行模型训练或评估。该数据集适用于情感分类、文本挖掘及事件驱动型金融分析任务,用户可结合ticker、date等字段进行时间序列或公司层面的纵向研究。提取的文本字段可直接输入NLP模型,而情感标注可作为监督信号或评估基准,为量化金融与计算语言学交叉研究提供便捷数据支撑。
背景与挑战
背景概述
在金融科技与自然语言处理交叉领域,上市公司公告文本的自动化分析已成为量化投资与风险管理的关键研究方向。psx-announcements-data数据集由相关研究机构或团队于近期构建,旨在系统收录并标注巴基斯坦证券交易所(PSX)上市公司的公告文档。该数据集的核心研究问题聚焦于从非结构化的金融文本中提取情感信号与关键信息,以支持市场情绪分析、事件驱动型交易策略及公司行为预测。通过提供结构化的公告文本及其情感评分,该数据集为新兴市场金融文本挖掘提供了宝贵的资源,推动了算法交易与监管科技在区域市场的应用深化。
当前挑战
该数据集致力于解决金融文本情感分析与事件信息抽取的领域挑战,具体包括公告文本中专业术语与模糊表述的语义消歧、市场即时反应与文本情感之间的复杂映射关系建模,以及多语言混杂环境下低资源语言的准确处理。在构建过程中,面临公告格式异构性导致的文本提取困难、情感标签的人工标注一致性保障,以及从原始PDF到结构化数据的自动化流水线设计等工程挑战。这些挑战共同指向了金融自然语言处理系统在真实性、时效性与可扩展性方面的核心瓶颈。
常用场景
经典使用场景
在金融信息处理领域,psx-announcements-data数据集为研究公告文本的情感分析提供了关键资源。该数据集收录了巴基斯坦证券交易所的上市公司公告,包含标题、日期、提取文本及情感评分等特征,常用于训练和评估自然语言处理模型,以自动化解析公告内容中的情感倾向和影响程度,从而支持投资者对市场情绪的量化分析。
解决学术问题
该数据集有效解决了金融文本挖掘中的若干学术难题,例如公告情感与市场反应之间的关联性研究。通过提供结构化的情感评分和影响标签,它助力学者探索情感信号如何驱动股价波动,并验证情感分析模型在非英语金融文本上的泛化能力,为跨语言金融信息处理提供了实证基础。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,包括基于深度学习的多语言情感分类模型优化,以及公告情感与股票收益的因果推断分析。这些研究不仅拓展了金融文本分析的边界,还促进了巴基斯坦等新兴市场的数据驱动投资方法的发展,为区域金融科技研究注入了活力。
以上内容由遇见数据集搜集并总结生成


