ReClor
收藏arXiv2020-08-22 更新2024-06-21 收录
下载链接:
http://whyu.me/reclor/
下载链接
链接失效反馈官方服务:
资源简介:
ReClor是由新加坡国立大学的研究团队创建的一个阅读理解数据集,专注于逻辑推理能力的评估。该数据集包含了6138个问题,这些问题是从GMAT和LSAT等标准化考试中提取的,旨在全面评估模型的逻辑推理能力。数据集分为EASY和HARD两个子集,分别对应于包含偏差和无偏差的数据点。ReClor的应用领域主要集中在自然语言处理中,特别是在机器阅读理解任务中,旨在推动逻辑推理能力的发展,从简单的逻辑关系分类到多重复杂的逻辑推理,从句子级别到篇章级别。
ReClor is a reading comprehension dataset created by a research team from the National University of Singapore, focusing on the evaluation of logical reasoning capabilities. The dataset comprises 6,138 questions extracted from standardized tests such as GMAT and LSAT, and is designed to comprehensively assess the logical reasoning abilities of models. It is divided into two subsets: EASY and HARD, which correspond to data points with and without bias respectively. Its primary application scenarios lie in the field of natural language processing, particularly in machine reading comprehension tasks, aiming to promote the development of logical reasoning capabilities, ranging from simple logical relation classification to complex multi-step logical inferences, and from sentence-level to discourse-level.
提供机构:
新加坡国立大学
创建时间:
2020-02-11
搜集汇总
数据集介绍
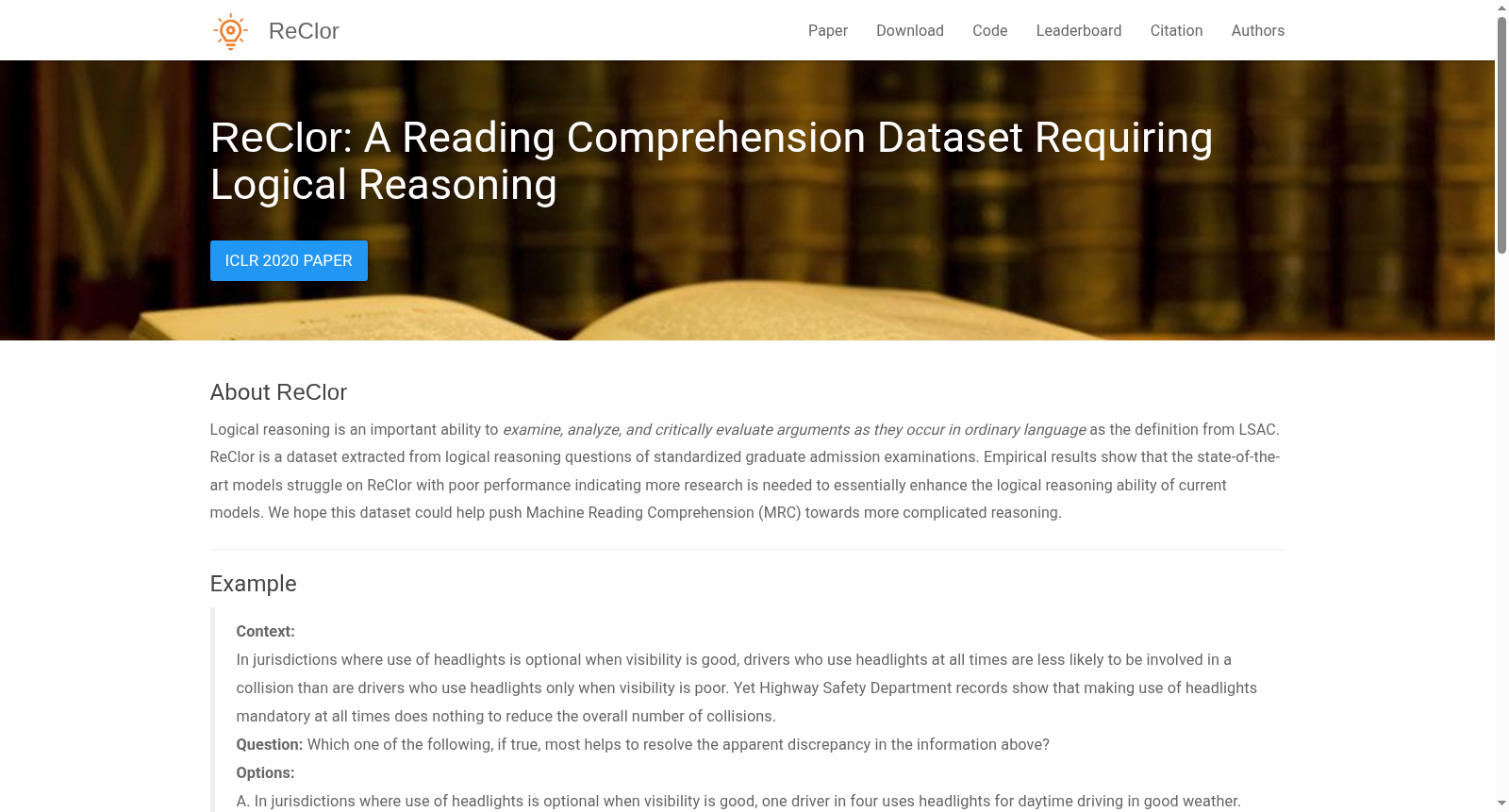
构建方式
在机器阅读理解领域,现有数据集往往缺乏对复杂逻辑推理能力的系统评估。为填补这一空白,ReClor数据集从标准化研究生入学考试(如GMAT和LSAT)中精心筛选出6,138道逻辑推理题目。这些题目由领域专家设计,涵盖上下文、问题及四个选项的经典多选格式。为确保数据合法使用,研究团队对选项顺序进行了随机化处理,并删除了一个错误选项,最终形成包含4,638个训练样本、500个验证样本和1,000个测试样本的数据集。数据构建过程强调逻辑推理的多样性与深度,旨在推动模型从句子级推理向篇章级复杂推理的演进。
特点
ReClor数据集的核心特点在于其专注于高阶逻辑推理能力评估。数据源自权威考试机构设计的题目,涵盖必要假设、充分假设、强化、削弱等17种逻辑推理类型,全面模拟人类在复杂文本分析中的认知过程。与现有阅读理解数据集相比,ReClor的上下文长度适中但信息密度高,每个句子都对推理至关重要;选项平均长度显著较长,要求模型进行精细的语义理解。数据集还创新性地引入偏差分析机制,通过仅使用选项输入的基线模型识别出测试集中的偏差样本,将其划分为EASY集合,其余作为HARD集合,从而实现对模型真实推理能力的剥离式评估。
使用方法
使用ReClor数据集时,研究者可采用多选阅读理解的标准范式:模型接收上下文、问题及四个选项作为输入,预测唯一正确选项。为充分发挥数据集价值,建议结合其独特的EASY/HARD划分进行分层评估,以区分模型利用数据偏差的能力与真实逻辑推理水平。实验表明,在ReClor上直接微调预训练语言模型(如BERT、RoBERTa)可取得一定效果,但通过在大规模多选数据集(如RACE)上进行预训练再微调,能显著提升模型在HARD集合上的表现。数据集已通过EvalAI平台提供公开评估服务,支持非商业研究用途,促进该领域的标准化评测与比较。
背景与挑战
背景概述
在自然语言处理领域,机器阅读理解作为一项基础任务,旨在评估模型对文本内容的理解与推理能力。随着预训练语言模型的兴起,传统数据集上的性能已趋于饱和,亟需引入更具挑战性的数据以推动领域向深层逻辑推理发展。ReClor数据集由新加坡国立大学的研究团队于2020年构建,其核心研究问题聚焦于逻辑推理能力的评估。该数据集从GMAT和LSAT等标准化研究生入学考试中提取了6,138道逻辑推理题目,涵盖17种推理类型,如必要假设、削弱论证和结构匹配等。ReClor的推出显著填补了现有数据集中在篇章级复杂逻辑推理方面的空白,为模型能力评估提供了更为严谨的基准,对推动自然语言理解向更高层次发展产生了深远影响。
当前挑战
ReClor数据集所针对的领域挑战在于,现有机器阅读理解模型往往依赖数据偏见而非真正理解文本进行预测,导致在需要深层逻辑推理的任务上表现欠佳。具体而言,模型在涉及多步骤推理、论证分析和隐含关系推断的题目中难以达到人类水平,尤其在非偏见数据上的准确率接近随机猜测。构建过程中的挑战主要体现在数据源的筛选与处理:逻辑推理题目需从专业考试中提取,其设计依赖人类专家的高度智力投入,无法通过众包简单生成;同时,为消除选项中的词汇和长度偏见,研究团队需开发基于多模型一致性检测的方法,将测试集划分为易受偏见影响的EASY子集和侧重纯粹推理的HARD子集,这一过程对数据标注的严谨性与评估框架的设计提出了极高要求。
常用场景
经典使用场景
在自然语言处理领域,机器阅读理解任务正朝着更深层次的逻辑推理能力迈进。ReClor数据集作为一项专门针对逻辑推理的阅读理解资源,其经典使用场景在于评估和提升预训练语言模型在复杂逻辑分析方面的性能。该数据集通过从GMAT和LSAT等标准化研究生入学考试中提取的6138个逻辑推理问题,构建了一个包含上下文、问题和四个选项的多元选择题库。研究者通常利用ReClor来测试模型在识别论证缺陷、推断隐含假设、解析矛盾信息等方面的能力,从而推动模型从简单的文本匹配向深层次逻辑理解演进。
衍生相关工作
ReClor数据集的推出激发了多项相关经典研究工作,主要集中在逻辑推理模型的改进和评估方法的创新上。例如,研究者基于ReClor的EASY和HARD集划分,开发了更精细的偏差检测技术,以区分模型是否真正掌握逻辑推理能力。此外,该数据集促进了跨数据集迁移学习的研究,如先在RACE数据集上进行预训练再微调至ReClor,显著提升了模型在困难集上的表现。同时,ReClor也启发了针对特定逻辑推理类型(如加强论证或识别缺陷)的专项模型设计,推动了自然语言推理任务向更细粒度和复杂化方向发展。这些工作共同构成了逻辑推理领域的重要进展,为未来更智能的文本理解系统奠定了基础。
数据集最近研究
最新研究方向
在自然语言处理领域,随着预训练语言模型在传统阅读理解任务上接近饱和性能,ReClor数据集的提出标志着研究重心向深层逻辑推理能力评估的转移。该数据集源自标准化研究生入学考试,包含多种复杂逻辑推理题型,如必要假设、削弱论证和结构匹配等,旨在挑战模型在篇章级多步骤推理上的极限。前沿研究聚焦于通过数据偏见分析区分简单与困难样本,揭示当前模型虽能有效利用数据集偏差,但在无偏数据上的表现仍接近随机猜测,凸显了逻辑推理能力的内在不足。相关热点探索涉及跨任务迁移学习,如在RACE数据集上预训练以提升模型泛化性能,同时推动了对抗偏见、增强模型鲁棒性的新方法。这一进展不仅为评估模型真实理解能力设立了新基准,也激励着社区开发更先进的推理架构,推动自然语言理解向人类级逻辑思维迈进。
相关研究论文
- 1ReClor: A Reading Comprehension Dataset Requiring Logical Reasoning新加坡国立大学 · 2020年
以上内容由遇见数据集搜集并总结生成


