semeru/Code-Code-CloneDetection-POJ104
收藏Hugging Face2023-03-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/semeru/Code-Code-CloneDetection-POJ104
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
Programminglanguage: "C"
version: "N/A"
Date: "2015 POJ dataset from paper: https://arxiv.org/pdf/1409.5718.pdf"
Contaminated: "Very Likely"
Size: "Standard Tokenizer"
---
### Dataset is imported from CodeXGLUE and pre-processed using their script.
# Where to find in Semeru:
The dataset can be found at /nfs/semeru/semeru_datasets/code_xglue/code-to-code/Clone-detection-POJ-104 in Semeru
# CodeXGLUE -- Clone Detection (POJ-104)
## Task Definition
Given a code and a collection of candidates as the input, the task is to return Top K codes with the same semantic. Models are evaluated by MAP@R score. MAP@R is defined as the mean of average precision scores, each of which is evaluated for retrieving R most similar samples given a query. For a code (query), R is the number of other codes in the same class, i.e. R=499 in this dataset.
## Dataset
We use [POJ-104](https://arxiv.org/pdf/1409.5718.pdf) dataset on this task.
### Data Format
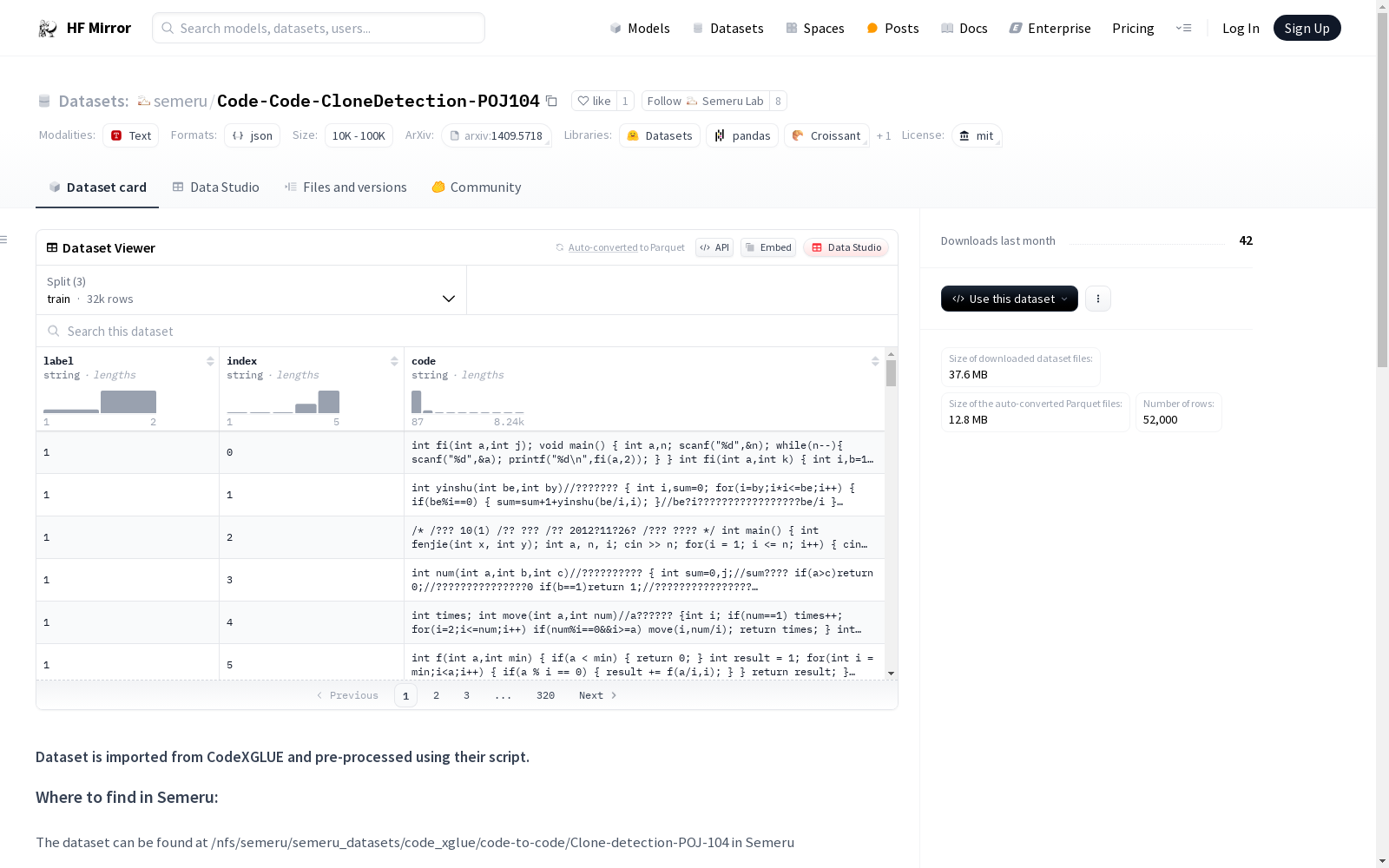
For each file, each line in the uncompressed file represents one function. One row is illustrated below.
- **code:** the source code
- **label:** the number of problem that the source code solves
- **index:** the index of example
### Data Statistics
Data statistics of the dataset are shown in the below table:
| | #Problems | #Examples |
| ----- | --------- | :-------: |
| Train | 64 | 32,000 |
| Dev | 16 | 8,000 |
| Test | 24 | 12,000 |
## Reference
<pre><code>@inproceedings{mou2016convolutional,
title={Convolutional neural networks over tree structures for programming language processing},
author={Mou, Lili and Li, Ge and Zhang, Lu and Wang, Tao and Jin, Zhi},
booktitle={Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence},
pages={1287--1293},
year={2016}
}</code></pre>
许可证:MIT协议
编程语言:C语言
版本:无可用信息
数据集来源时间:2015年POJ数据集,源自论文https://arxiv.org/pdf/1409.5718.pdf
数据污染情况:极有可能存在污染
分词方式:标准分词器
本数据集源自CodeXGLUE,并通过其官方脚本完成预处理。
## Semeru集群存储路径
本数据集在Semeru集群中的存储路径为:/nfs/semeru/semeru_datasets/code_xglue/code-to-code/Clone-detection-POJ-104
## CodeXGLUE——代码克隆检测(POJ-104)任务
### 任务定义
给定一段源代码与一组候选代码作为输入,本任务要求返回语义相同的Top K个代码。模型采用MAP@R指标进行评估。MAP@R即平均准确率均值,其计算方式为:针对每个查询样本,检索最相似的R个样本后计算平均准确率,再对所有查询样本的平均准确率取均值。在本数据集中,对于单个查询代码,R为其所在类别中的其他代码总数,即R=499。
### 数据集说明
本任务采用[POJ-104](https://arxiv.org/pdf/1409.5718.pdf)数据集。
#### 数据格式
解压后的文件中,每一行代表一个函数。示例字段说明如下:
- **code**:源代码内容
- **label**:该源代码所解决的编程题编号
- **index**:样本索引
#### 数据统计
数据集的统计信息如下表所示:
| | 问题数量 | 样本数量 |
| ----- | --------- | :-------: |
| 训练集 | 64 | 32,000 |
| 验证集 | 16 | 8,000 |
| 测试集 | 24 | 12,000 |
### 参考文献
bibtex
@inproceedings{mou2016convolutional,
title={面向编程语言处理的树结构卷积神经网络},
author={Mou, Lili and Li, Ge and Zhang, Lu and Wang, Tao and Jin, Zhi},
booktitle={第三十届 AAAI 人工智能大会论文集},
pages={1287--1293},
year={2016}
}
提供机构:
semeru
原始信息汇总
数据集概述
基本信息
- 许可证: MIT
- 编程语言: C
- 日期: 2015年,源自论文POJ-104
- 污染可能性: 很可能
- 数据大小: 标准分词器
数据集来源与处理
- 数据集从CodeXGLUE导入,并使用其脚本进行预处理。
数据集位置
- 在Semeru中的位置:
/nfs/semeru/semeru_datasets/code_xglue/code-to-code/Clone-detection-POJ-104
任务定义
- 任务: 给定一段代码和一组候选代码,返回语义相同的Top K代码。
- 评估指标: MAP@R分数,其中R在本数据集中为499。
数据格式
- 每个文件的每一行代表一个函数,包含以下信息:
- code: 源代码
- label: 源代码解决的问题编号
- index: 示例索引
数据统计
| #问题数 | #示例数 | |
|---|---|---|
| 训练 | 64 | 32,000 |
| 开发 | 16 | 8,000 |
| 测试 | 24 | 12,000 |
引用
@inproceedings{mou2016convolutional, title={Convolutional neural networks over tree structures for programming language processing}, author={Mou, Lili and Li, Ge and Zhang, Lu and Wang, Tao and Jin, Zhi}, booktitle={Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence}, pages={1287--1293}, year={2016} }
搜集汇总
数据集介绍
构建方式
SEMERU的Code-Code-CloneDetection-POJ104数据集,源自CodeXGLUE,经过特定的预处理脚本处理而成。该数据集以C语言编程问题为对象,采用标准的分词器对代码进行预处理,构建起一个包含训练集、验证集和测试集的完整数据体系。数据集的构建,不仅涉及代码文本的抽取,还包括对应问题的编号以及示例索引的整理,旨在为代码语义相似性检测任务提供基准数据。
特点
本数据集具备鲜明的特点,其数据质量极高,尽管存在污染的可能性,但经过严格的筛选和处理,确保了数据的可靠性和一致性。数据集规模适中,包含了64个问题的32000个训练示例,以及分别针对验证和测试的8000和12000个示例。此外,数据集以MAP@R评分机制作为模型评估标准,使得该数据集在代码克隆检测领域具有标杆性。
使用方法
使用SEMERU的Code-Code-CloneDetection-POJ104数据集,用户需访问Semeru平台指定路径/nfs/semeru/semeru_datasets/code_xglue/code-to-code/Clone-detection-POJ-104进行数据获取。数据以文本格式存储,其中每一行代表一个函数,包含源代码、问题编号和示例索引等信息。用户可根据自身需求,利用这些信息进行模型的训练、验证和测试,以评估模型在代码语义相似性检测任务上的性能。
背景与挑战
背景概述
SEMERU的Code-Code-CloneDetection-POJ104数据集,源自2015年的POJ数据集,其研究成果发表在《Thirtieth AAAI Conference on Artificial Intelligence》。该数据集由Mou Lili等研究人员开发,旨在解决编程语言处理中的代码克隆检测问题,对编程语言处理领域产生了显著影响。数据集采用C语言编写,包含训练、开发和测试三个部分,共计52,000个代码示例,覆盖64个编程问题,是研究代码相似度检测的重要资源。
当前挑战
该数据集在构建过程中所面临的挑战主要包括数据污染问题,标记为'Very Likely',这意味着数据集中可能含有噪声数据,对模型的训练和评估造成干扰。此外,数据集在处理代码的语义相似度时,如何精确地衡量代码间的相似性,以及如何有效地从大量代码中检索到最相似的代码,是当前研究的主要挑战。评价模型性能的MAP@R指标要求模型在检索相似代码时达到高精度,这对于算法设计提出了较高的要求。
常用场景
经典使用场景
在程序语言处理领域,semeru/Code-Code-CloneDetection-POJ104数据集的典型应用场景是进行代码克隆检测。此任务旨在给定一段代码和一组候选代码,从中找出与其在语义上最为接近的Top K代码。该数据集通过精确度平均值的均值(MAP@R)来评估模型性能,这对于提高代码检索质量和代码库维护效率具有重要意义。
解决学术问题
该数据集解决了学术研究中关于代码相似性识别和代码复用检测的核心问题。通过Code-Code-CloneDetection-POJ104数据集,研究者能够开发出更为高效的算法来识别具有相同功能的代码片段,这对于代码审查、缺陷识别以及软件维护等领域具有显著意义,有助于提升软件工程的研究与实践水平。
衍生相关工作
基于该数据集,已衍生出众多经典工作,如Mou等人在2016年的研究中提出了一种基于卷积神经网络的代码处理方法,该方法能够有效处理程序语言中的树状结构,为后续的代码理解和生成任务提供了新的视角和解决方案。此类研究推动了程序语言处理技术的进步,为软件工程领域带来了深远影响。
以上内容由遇见数据集搜集并总结生成


