alchemist
收藏Hugging Face2025-05-16 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/yandex/alchemist
下载链接
链接失效反馈官方服务:
资源简介:
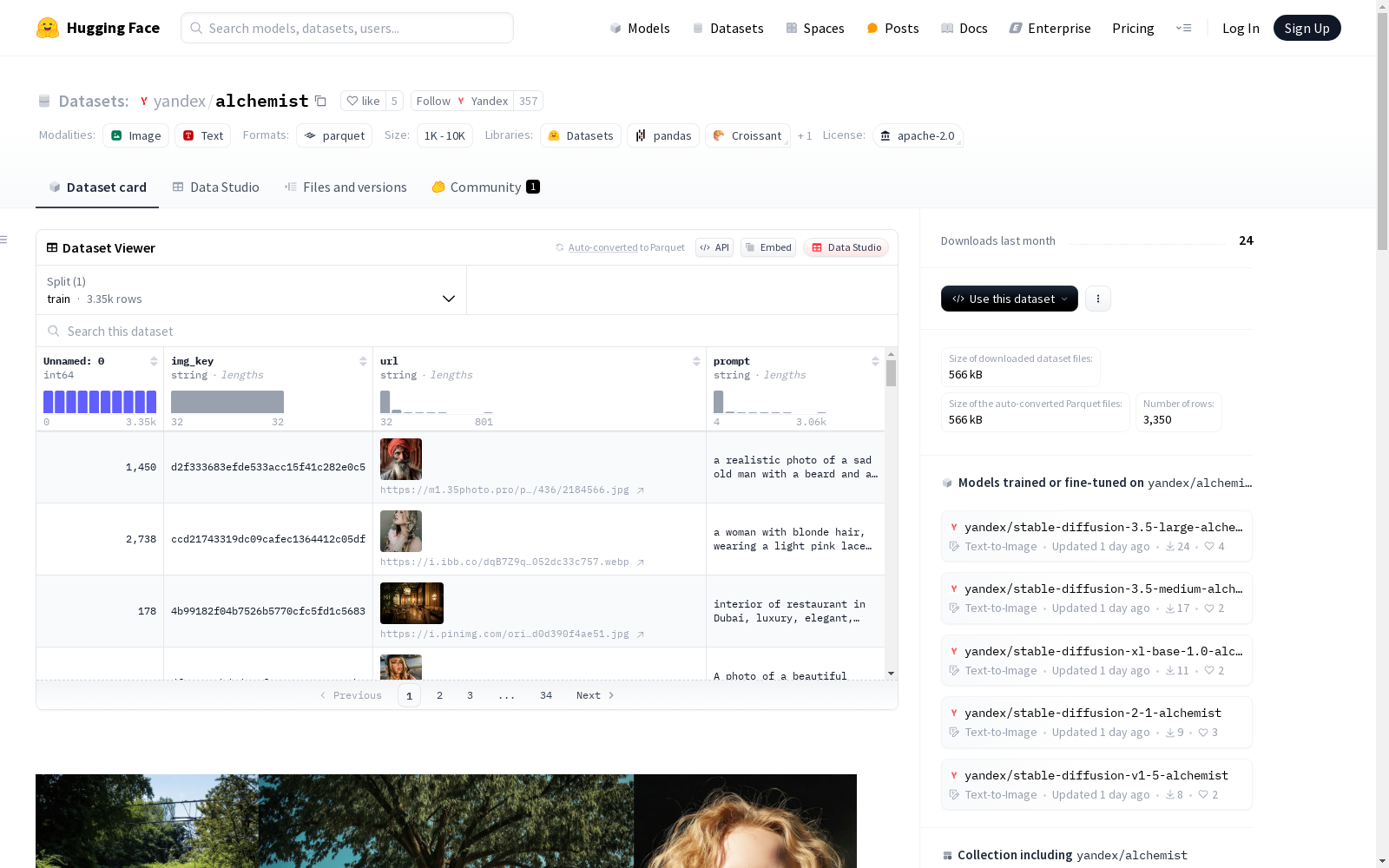
Alchemist数据集是一个精心策划的高质量小型数据集,包含3350个图像-文本对,用于监督微调(SFT)预训练的文本到图像(T2I)生成模型。该数据集的主要目标是显著提高T2I模型生成的图像质量(特别是美学吸引力和图像复杂性),同时保留内容、构成和风格的内在多样性。
The Alchemist Dataset is a meticulously curated high-quality small-scale dataset comprising 3,350 image-text pairs, designed for supervised fine-tuning (SFT) of pre-trained text-to-image (T2I) generative models. Its primary objective is to significantly enhance the image quality generated by T2I models—particularly in terms of aesthetic appeal and image complexity—while preserving the inherent diversity of content, composition, and style.
创建时间:
2025-05-15
搜集汇总
数据集介绍
构建方式
在生成式人工智能蓬勃发展的背景下,Alchemist数据集通过创新性的多阶段筛选流程构建而成。研究团队从约100亿张网络爬取图像出发,采用以图像质量为核心的预过滤策略,依次进行安全性筛查、分辨率筛选及基于轻量级分类器的质量评估。随后运用SIFT特征进行图像去重,并采用TOPIQ无参考图像质量评估模型进行精细筛选,获得约3亿张高质量图像。该数据集的核心创新在于引入预训练扩散模型作为质量评估器,通过分析跨注意力激活模式,从初步标注的图像文本对中筛选出具有特殊美学特质的样本。最终对精选的3350张图像进行符合用户表达习惯的重新标注,形成兼具视觉吸引力和文本适配性的高质量数据集。
特点
Alchemist数据集作为专为文本到图像生成模型监督微调设计的精品资源,展现出三大显著特征。其样本规模虽仅包含3350个图像文本对,但每个样本都经过严格的质量把控,确保视觉内容的审美价值和生成复杂度。数据集的文本标注采用适度描述性风格,模拟真实用户提示词特征,这种平衡性设计既能引导模型提升生成质量,又避免了过度详细描述导致的创造性限制。该数据集特别强调内容多样性的保持,覆盖广泛的题材、构图和艺术风格,为生成模型提供了丰富的学习素材,有效解决了传统大规模数据集质量参差不齐或过滤方法导致内容单一的问题。
使用方法
Alchemist数据集主要应用于提升预训练文本到图像生成模型的监督微调效果。研究人员可通过HuggingFace的datasets库便捷加载数据集,使用标准接口访问图像哈希标识、原始URL及关联提示文本。实践表明,该数据集对Stable Diffusion系列架构(包括SD1.5至SD3.5等多个版本)均具有显著性能提升作用。典型使用场景包括:将数据集划分为训练验证集后,采用常规微调流程更新模型参数;或结合课程学习策略,逐步引入不同难度级别的样本。数据集中精心设计的用户风格提示文本,也可作为提示词工程研究的优质素材,助力探索生成质量与文本引导之间的优化关系。
背景与挑战
背景概述
Alchemist数据集由Yandex研究团队于2024年推出,旨在解决生成式人工智能领域中文本到图像(T2I)模型微调的关键问题。该数据集包含3,350个高质量图像-文本对,通过创新的多阶段筛选流程从约100亿网络图片中精选而出。其核心创新在于采用预训练扩散模型作为质量评估器,通过交叉注意力机制识别具有美学价值和内容复杂度的样本。这一方法论发表于研究论文《Alchemist: Turning Public Text-to-Image Data into Generative Gold》,为生成模型的监督微调(SFT)提供了新的范式,显著提升了Stable Diffusion等主流架构的生成质量与多样性平衡。
当前挑战
构建Alchemist数据集面临双重挑战:在领域问题层面,需突破传统大规模数据集的粗放筛选模式,解决高质量图像-文本对齐的精确识别难题;在技术实现层面,开发基于扩散模型的跨注意力评分系统需要克服计算复杂度高、评估维度多元化的工程挑战。具体而言,从100亿原始数据到最终3,350个样本的转化过程中,需协调图像去重算法(SIFT特征)、无参考质量评估模型(TOPIQ)与生成模型注意力机制的异构评估体系,同时确保最终提示词兼具用户语言习惯与语义精确性。
常用场景
经典使用场景
在生成式人工智能领域,Alchemist数据集以其精心筛选的图像-文本对成为提升文本到图像生成模型性能的关键资源。该数据集特别适用于对预训练模型进行监督微调,旨在显著增强生成图像的美学质量和视觉复杂度,同时保持内容、构图和风格的多样性。通过其独特的筛选流程,Alchemist为研究人员提供了一个高效的工具,以探索生成模型在有限数据下的优化潜力。
衍生相关工作
围绕Alchemist数据集的研究已催生了一系列创新工作,特别是在生成模型微调策略领域。其提出的扩散模型引导的质量评估方法启发了后续关于高效数据筛选的研究方向。同时,该数据集也被广泛应用于比较不同微调技术的基准测试中,为评估文本到图像生成模型的性能提供了标准化平台。
数据集最近研究
最新研究方向
在生成式人工智能领域,Alchemist数据集因其独特的筛选机制和高质量图像文本对而备受关注。当前研究聚焦于如何利用该数据集优化文本到图像生成模型的监督微调过程,特别是在提升生成图像的美学质量和复杂度的同时保持内容的多样性。前沿探索方向包括结合扩散模型引导的质量评估方法,开发更高效的图像筛选算法,以及研究不同风格的提示词对模型性能的影响。该数据集的应用已延伸至多个Stable Diffusion架构,为生成式模型的性能提升提供了新的研究范式。
以上内容由遇见数据集搜集并总结生成


