solarchive
收藏Hugging Face2025-12-22 更新2025-12-23 收录
下载链接:
https://huggingface.co/datasets/solarchive/solarchive
下载链接
链接失效反馈官方服务:
资源简介:
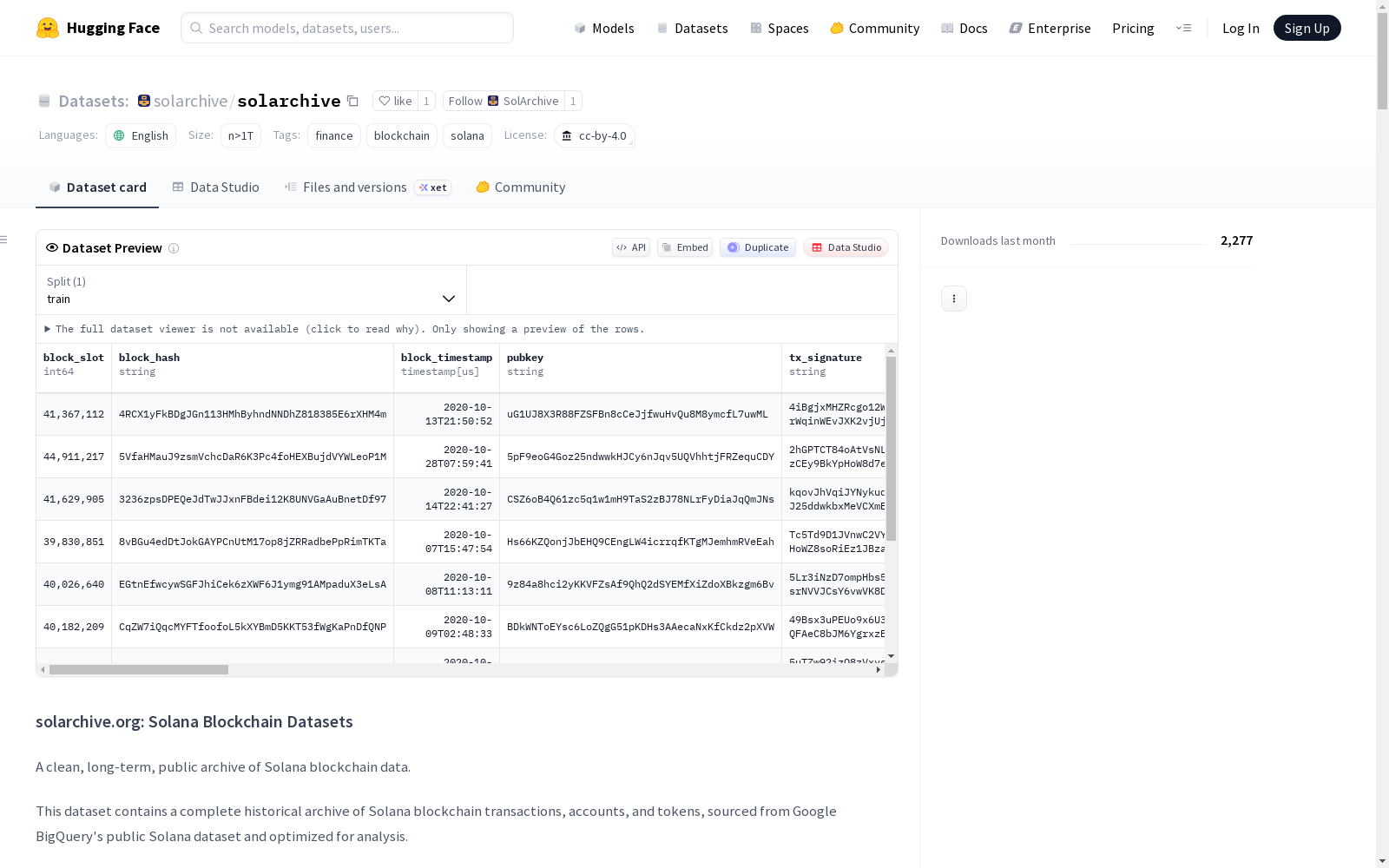
SolArchive.org Solana数据集是一个干净、长期、公开的Solana区块链数据存档。该数据集包含从Google BigQuery的公共Solana数据集中获取的完整历史交易、账户和代币数据,并针对分析进行了优化。数据集设计用于研究人员分析区块链行为和模式、数据科学家构建区块链数据模型、开发人员构建需要历史Solana数据的应用程序以及分析师研究DeFi、NFT和代币经济学。主要特点包括从创世到现在的完整历史数据、每日分区以提高查询效率、过滤掉投票交易(更干净的数据集)、免费下载且无出口费用、文档齐全的架构示例以及用于快速分析的Parquet格式。
创建时间:
2025-12-19
原始信息汇总
SolArchive.org Solana 区块链数据集概述
数据集基本信息
- 数据集名称: SolArchive.org Solana Datasets
- 托管平台: Hugging Face
- 许可证: CC BY 4.0 (Creative Commons Attribution 4.0 International)
- 主要语言: 英语
- 标签: 金融、区块链、Solana
- 数据规模类别: 大于1TB
数据集简介
SolArchive 是一个完整、长期、公开的 Solana 区块链数据档案库。它包含了 Solana 区块链交易、账户和代币的完整历史存档,数据源自 Google BigQuery 的公共 Solana 数据集,并针对分析进行了优化。
主要目标用户
- 研究区块链行为和模式的研究人员
- 基于区块链数据构建模型的数据科学家
- 需要历史 Solana 数据构建应用程序的开发者
- 研究 DeFi、NFT 和代币经济学的分析师
核心特性
- 包含从创世区块到现在的完整历史数据
- 按日分区,便于高效查询
- 已过滤掉投票交易(数据集更干净)
- 免费下载,无出口费用
- 提供有详细示例的完善模式文档
- 采用 Parquet 格式,便于快速分析
包含的数据集
1. 交易数据集 (txs/)
包含所有 Solana 交易(不包括验证者投票)及完整元数据。
- 覆盖范围: 2020年10月至今
- 分区方式: 按日 (
YYYY-MM-DD) - 格式: 带校验和的 Parquet 文件
- 模式文件: https://huggingface.co/datasets/solarchive/solarchive/blob/main/schemas/transactions.json
- 包含内容:
- 交易签名和状态
- 区块信息(时隙、哈希、时间戳)
- 涉及的账户(公钥、签名者/可写标志)
- SOL 余额变化
- 代币余额变化(前/后)
- 消耗的计算单元
- 程序日志消息
- 费用信息
2. 账户数据集 (accounts/)
包含历史账户快照,包括代币账户、程序账户和投票账户。
- 覆盖范围: 2020年10月至今
- 分区方式: 按日 (
YYYY-MM-DD) - 格式: 带校验和的 Parquet 文件
- 模式文件: https://huggingface.co/datasets/solarchive/solarchive/blob/main/schemas/accounts.json
- 包含内容:
- 账户公钥和余额
- 所有者程序
- 代币账户信息(铸币地址、数量、小数位数)
- 投票账户数据(验证者、投票、纪元积分)
- 程序账户数据
- 账户状态和元数据
3. 代币数据集 (tokens/)
包含代币元数据,包括 NFT 和同质化代币。
- 覆盖范围: 2020年10月至今
- 分区方式: 按日 (
YYYY-MM-DD) - 格式: 带校验和的 Parquet 文件
- 模式文件: https://huggingface.co/datasets/solarchive/solarchive/blob/main/schemas/tokens.json
- 包含内容:
- 代币铸币地址
- 代币名称和符号
- 元数据 URI
- 创建者信息
- NFT 标识
- 版税信息(卖家费用)
- 可变性标志
数据格式与结构
- 存储格式: Apache Parquet 格式
- 文件组织: 每个 Parquet 数据文件均附带一个对应的 SHA256 校验和文件以供验证
- 仓库结构:
txs/: 交易数据集accounts/: 账户数据集tokens/: 代币数据集schemas/: JSON 模式文件目录
关键字段参考
- 交易:
signature: 唯一交易标识符block_slot: 交易被包含在内的时隙编号block_timestamp: ISO 8601 时间戳fee: 交易费用(以 lamports 为单位,1 SOL = 10^9 lamports)status: "Success" 或 "Failed"accounts: 涉及的账户数组,包含签名者/可写标志balance_changes: 每个账户的 SOL 余额变化pre_token_balances/post_token_balances: 代币余额变化
- 账户:
pubkey: 账户公钥lamports: 账户余额(以 lamports 为单位)owner: 拥有此账户的程序mint: 对于代币账户,指代币铸币地址token_amount: 对于代币账户,指代币余额
- 代币:
mint: 代币铸币地址name/symbol: 代币名称和符号is_nft: 是否为 NFTcreators: 创建者地址数组,包含验证状态uri: 元数据 URI
使用许可
- 允许商业用途
- 允许修改和重新分发
- 可用于任何目的
- 要求署名: 使用时需注明“Data from SolArchive.org”
- 底层的 Solana 区块链数据本质上是公开的
搜集汇总
数据集介绍
构建方式
SolArchive数据集作为Solana区块链的全面历史档案,其构建过程体现了对原始数据的精细处理与优化。该数据集源自Google BigQuery的公开Solana数据,经过系统性的清洗与重组,剔除了验证者投票交易,以确保分析数据的纯净性。数据以每日分区的方式组织,涵盖自2020年10月以来的完整历史记录,采用Parquet格式存储,并附有校验和文件,保障了数据的完整性与高效查询能力。这种结构化的构建方法不仅提升了数据访问效率,也为大规模区块链分析提供了可靠基础。
特点
该数据集的核心特点在于其完整性与优化设计。它完整收录了Solana区块链自创世以来的交易、账户及代币元数据,为研究者提供了连续的历史视角。数据以每日分区存储,显著提升了查询性能,同时过滤了投票交易,使数据集更专注于用户级活动。Parquet格式的应用支持快速分析,而详细的JSON模式文档则确保了数据结构的透明性。这些特性共同构成了一个适用于学术研究、商业分析与应用开发的优质数据资源。
使用方法
利用该数据集进行区块链分析,用户可通过Hugging Face Hub提供的接口便捷地访问数据。例如,使用Python中的`huggingface_hub`库,可以下载特定日期的Parquet文件,并通过PyArrow或Pandas进行加载与处理。数据集支持按需下载单个文件或整个分区,兼容DuckDB等分析工具,便于执行复杂的SQL查询。这种灵活的使用方式,使得研究人员能够高效地探索交易模式、账户行为或代币经济,推动区块链数据科学的深入发展。
背景与挑战
背景概述
在区块链技术迅猛发展的背景下,Solana以其高吞吐量和低延迟特性成为分布式账本领域的重要平台。为满足学术界与工业界对高质量、结构化历史数据的需求,SolArchive数据集应运而生。该数据集由SolArchive.org团队创建并维护,自2020年10月起持续收录Solana区块链的完整历史记录,涵盖交易、账户及代币元数据。其核心研究问题聚焦于如何为研究人员、数据科学家及开发者提供一套清洁、高效且可公开访问的数据基础设施,以支持区块链行为分析、模型构建与应用开发。该数据集的发布显著降低了获取和分析大规模链上数据的门槛,对推动去中心化金融、非同质化代币及代币经济学的实证研究具有深远影响。
当前挑战
SolArchive数据集致力于解决区块链数据分析领域的关键挑战,即如何从海量、异构且动态增长的链上数据中提取有价值的信息。具体而言,其面临的挑战包括:在领域问题层面,需应对交易模式的复杂性识别、异常行为检测以及跨合约交互的可追溯性分析;在数据构建过程中,则需克服原始数据清洗的困难,例如有效过滤验证者投票交易以确保数据集纯净性,同时实现每日分区存储以优化查询效率,并确保数据完整性校验机制的可靠性。此外,维持数据更新与历史归档的平衡,以及处理Parquet格式下大规模数据的高效压缩与读取,亦是构建过程中的技术难点。
常用场景
经典使用场景
在区块链数据分析领域,SolArchive数据集为研究者提供了从创世区块至今的完整Solana链上历史记录,其经典使用场景聚焦于对交易模式、账户行为及代币经济学的深度挖掘。通过每日分区的Parquet格式数据,研究人员能够高效执行大规模时序分析,例如追踪去中心化金融(DeFi)协议的资金流动、识别非同质化代币(NFT)市场的交易异常,或评估网络拥堵与手续费动态,从而揭示区块链生态系统的内在运行规律。
衍生相关工作
围绕SolArchive数据集,已衍生出多项经典研究工作。例如,基于其交易序列的图神经网络模型被用于预测智能合约的调用风险;利用账户快照数据的研究揭示了Solana生态中资本集中度的演化趋势;结合代币元数据的分析则推动了NFT估值模型的创新。这些工作不仅发表在顶尖计算机科学与金融工程会议中,还催生了开源分析框架与可视化工具,持续丰富着区块链数据科学的方法论体系。
数据集最近研究
最新研究方向
在区块链数据分析领域,SolArchive数据集凭借其完整的Solana历史交易、账户与代币数据,正推动着前沿研究的深化。研究者们聚焦于利用该数据集进行链上行为模式挖掘,特别是在去中心化金融(DeFi)与非同质化代币(NFT)的经济动力学分析中,通过大规模交易图谱构建与异常检测,揭示市场操纵与洗钱交易等隐秘行为。随着Solana生态在高速交易与低费用方面的优势凸显,相关研究亦关注其网络拥堵事件下的交易排序公平性及跨链资产流动模式。这些探索不仅为区块链安全与监管科技提供了实证基础,也助力于开发更高效的链上索引协议与数据服务基础设施。
以上内容由遇见数据集搜集并总结生成


