GrandgemMa-Corpus
收藏Hugging Face2026-05-13 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/s23deepak/GrandgemMa-Corpus
下载链接
链接失效反馈官方服务:
资源简介:
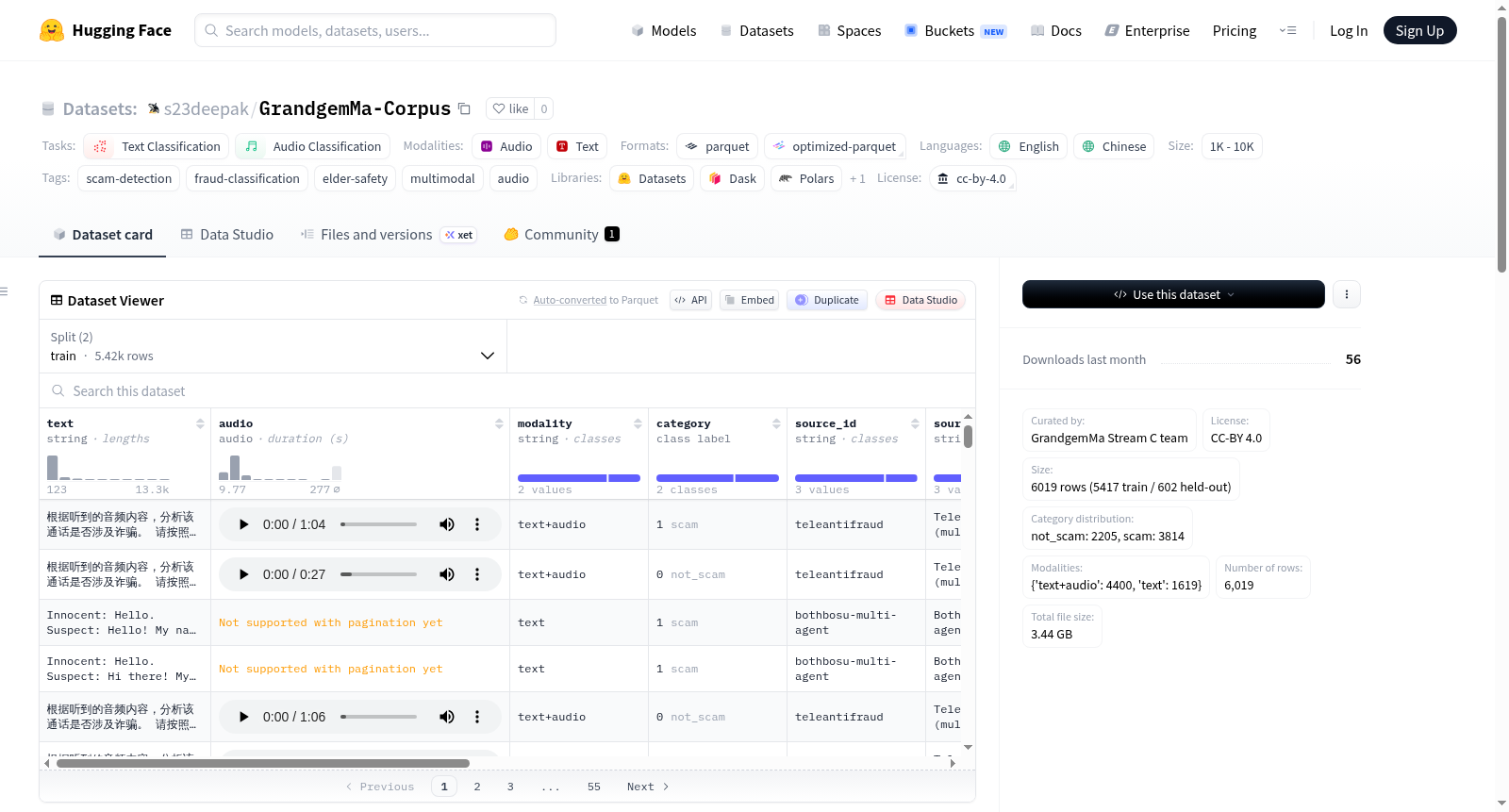
GrandgemMa-Corpus(又名ScamBench)是一个采用CC-BY 4.0许可证的多模态诈骗分类语料库,专为训练和评估面向老年人安全的设备端诈骗检测模型而构建。该数据集支持纯文本和多模态(文本+音频)两种微调模式,包含6019条样本,其中训练集5417条,留出测试集602条。类别分布为诈骗类3814条和非诈骗类2205条。从模态上看,包含4400条“文本+音频”样本和1619条纯文本样本。数据集整合了三个来源:BothBosu/multi-agent-scam-conversation(1600条,Apache-2.0许可证)、Claude生成的老年人诈骗场景(19条,CC-BY-4.0许可证)以及TeleAntiFraud多模态数据集(4400条,Apache-2.0许可证)。TeleAntiFraud来源的样本嵌入了音频(mp3格式),使模型能够学习从文本转录中丢失的韵律线索(如紧迫感、压力、语调)。数据集的列模式包括文本内容、音频数据、模态类型、类别标签、来源标识、来源许可证、来源URL、原始ID以及PII处理标记。该数据集是GrandgemMa黑客松(Gemma 4 Good,2026-05-17)项目的一部分,旨在促进针对老年人安全保护的诈骗检测模型的开发与评估。
GrandgemMa-Corpus (also known as ScamBench) is a multimodal scam classification corpus under the CC-BY 4.0 license, specifically built for training and evaluating on-device scam detection models for elderly safety. The dataset supports both text-only and multimodal (text + audio) fine-tuning modes. It contains 6019 samples, with 5417 in the training set and 602 in the held-out test set. The class distribution includes 3814 scam samples and 2205 not_scam samples. In terms of modality, it comprises 4400 text + audio samples and 1619 text-only samples. The dataset integrates three sources: BothBosu/multi-agent-scam-conversation (1600 samples, Apache-2.0 license), Claude-generated elderly scam scenarios (19 samples, CC-BY-4.0 license), and the TeleAntiFraud multimodal dataset (4400 samples, Apache-2.0 license). Samples from the TeleAntiFraud source include embedded audio (in mp3 format), enabling models to learn prosodic cues (such as urgency, stress, and intonation) that are lost in text transcription. The column schema includes text content (text, with personally identifiable information PII filtered), audio data (audio, null for some samples), modality type, category label (0 for not_scam, 1 for scam), source identifiers (source_id, source_name), source license, source URL, original ID, and PII handling markers (pii_redacted, pii_filtered). This dataset is part of the GrandgemMa hackathon (Gemma 4 Good, 2026-05-17) project, aimed at advancing the development and evaluation of scam detection models for elderly safety protection.
创建时间:
2026-05-13
搜集汇总
数据集介绍
构建方式
GrandgemMa-Corpus是一个专为老年人安全场景设计的多模态欺诈分类数据集,其构建融合了多种数据来源与精细的数据处理流程。数据集汇集了来自BothBosu/multi-agent-scam-conversation(1600条)、Claude生成的老年人诈骗场景(19条)以及TeleAntiFraud多模态数据集(4400条)的共计6019条样本。其中,TeleAntiFraud部分包含了嵌入的mp3音频,使得模型能够学习到转录文本所丢失的韵律线索(如紧迫感、压力、语调)。所有文本内容均经过PII过滤以保护隐私,每个样本都保留了原始来源标识与许可证信息,最终以Parquet格式存储并以CC-BY 4.0许可证发布。
特点
该数据集最显著的特点在于其多模态特性,共包含4400条文本+音频样本和1619条纯文本样本,并支持文本分类与音频分类双重任务标注。类别分布设计为反欺诈场景的实际不平衡情况,其中非欺诈类2205条、欺诈类3814条。音频数据以16kHz采样率嵌入,能够在保持数据紧凑的同时保留丰富的声学信息。此外,数据集明确的来源追溯机制(包含source_id、source_name、source_license和source_url字段)为用户提供了透明的数据溯源能力,便于学术研究中的责任与信用管理。
使用方法
用户可通过HuggingFace Datasets库直接加载该数据集,使用load_dataset('s23deepak/GrandgemMa-Corpus')命令即可获取训练集(5417条)和held-out测试集(602条)。对于多模态场景,可通过访问音频字段的array属性获取numpy数组形式的波形,并利用sampling_rate字段获取采样率(16000 Hz),从而将波形与文本联合输入多模态模型。数据集同时支持纯文本分类和音频分类两种范式,用户可根据任务需求选择忽略或启用音频模态。其预设的训练/测试分割和明确的模态标注,降低了二次处理成本,便于快速开展欺诈检测模型的训练与评估。
背景与挑战
背景概述
GrandgemMa-Corpus(ScamBench)是由GrandgemMa Stream C团队于2026年5月构建的多模态诈骗分类语料库,旨在应对日益严峻的针对老年人的电信与网络诈骗问题。该数据集融合了文本与音频两种模态,包含6019条样本(其中4400条为文本+音频形式),来源于多个公开数据集及合成场景,如TeleAntiFraud和基于Claude生成的老年诈骗场景。核心研究问题聚焦于开发适用于终端设备的轻量化诈骗检测模型,利用语音中的韵律线索(如紧迫感、压力、语调)提升检测鲁棒性。该数据集以CC-BY 4.0协议发布,填补了多模态端侧反欺诈基准的空白,对保障老年人数字安全具有重要推动价值。
当前挑战
GrandgemMa-Corpus所解决的领域挑战包括:传统文本分类模型难以捕捉诈骗电话中通过语气、语速等非语言信号传递的欺骗性线索,而多模态学习需有效融合文本与音频特征以提升泛化能力。构建过程中的挑战体现在三方面:一是多源数据整合,需统一来自不同采集协议(如多智能体对话数据、真实录音)的格式与标签;二是隐私合规,需对个人身份信息进行严格的自动化检测与脱敏处理;三是样本不均衡,非诈骗样本仅占2205条,而诈骗样本达3814条,需设计合理的采样策略避免模型偏置。此外,4400条多模态数据的音频编码与存储(如mp3嵌入Parquet)也带来了工程复杂性。
常用场景
经典使用场景
GrandgemMa-Corpus是专为老年人防诈骗场景设计的 multimodal 欺诈分类数据集,融合文本与音频双模态信息。其经典使用场景涵盖基于文本内容的诈骗检测、基于语音韵律特征的欺诈识别,以及文本与音频联合驱动的多模态分类任务。研究者可利用该数据集微调轻量级端侧模型,在保护用户隐私的同时实现对电话诈骗、社交媒体欺诈等场景的精准判别,尤其适用于资源受限的移动设备环境。
解决学术问题
该数据集系统解决了现有反欺诈语料库中模态单一、缺乏针对老年群体保护机制的核心学术问题。通过提供4400条包含原始音频的多模态样本,它使研究者能够探索语音中蕴含的紧迫感、胁迫性语调等韵律线索对欺诈检测的增益作用,弥补了纯文本转录丢失关键副语言信息的局限。此外,数据集严格进行PII脱敏与过滤,为隐私保护下的端侧模型训练提供了标准化基准,推动了安全、可落地的反欺诈研究范式发展。
衍生相关工作
GrandgemMa-Corpus衍生出一系列代表性研究工作:一是多模态反欺诈基线模型的构建,如融合文本Transformer与音频CNN的双流架构,在端侧实现低延迟欺诈判别;二是针对老年人特有的诈骗场景(如冒充熟人、虚假中奖)进行细粒度分类任务;三是基于该语料库的跨语言迁移学习研究,探索中文与英文诈骗话语的共性韵律模式。此外,该数据集也催生了面向端侧模型的轻量化压缩策略研究,推动隐私合规与模型性能的平衡优化。
以上内容由遇见数据集搜集并总结生成


