MJ-Bench-Image
收藏Hugging Face2025-10-23 更新2025-10-24 收录
下载链接:
https://huggingface.co/datasets/Zhaorun/MJ-Bench-Image
下载链接
链接失效反馈官方服务:
资源简介:
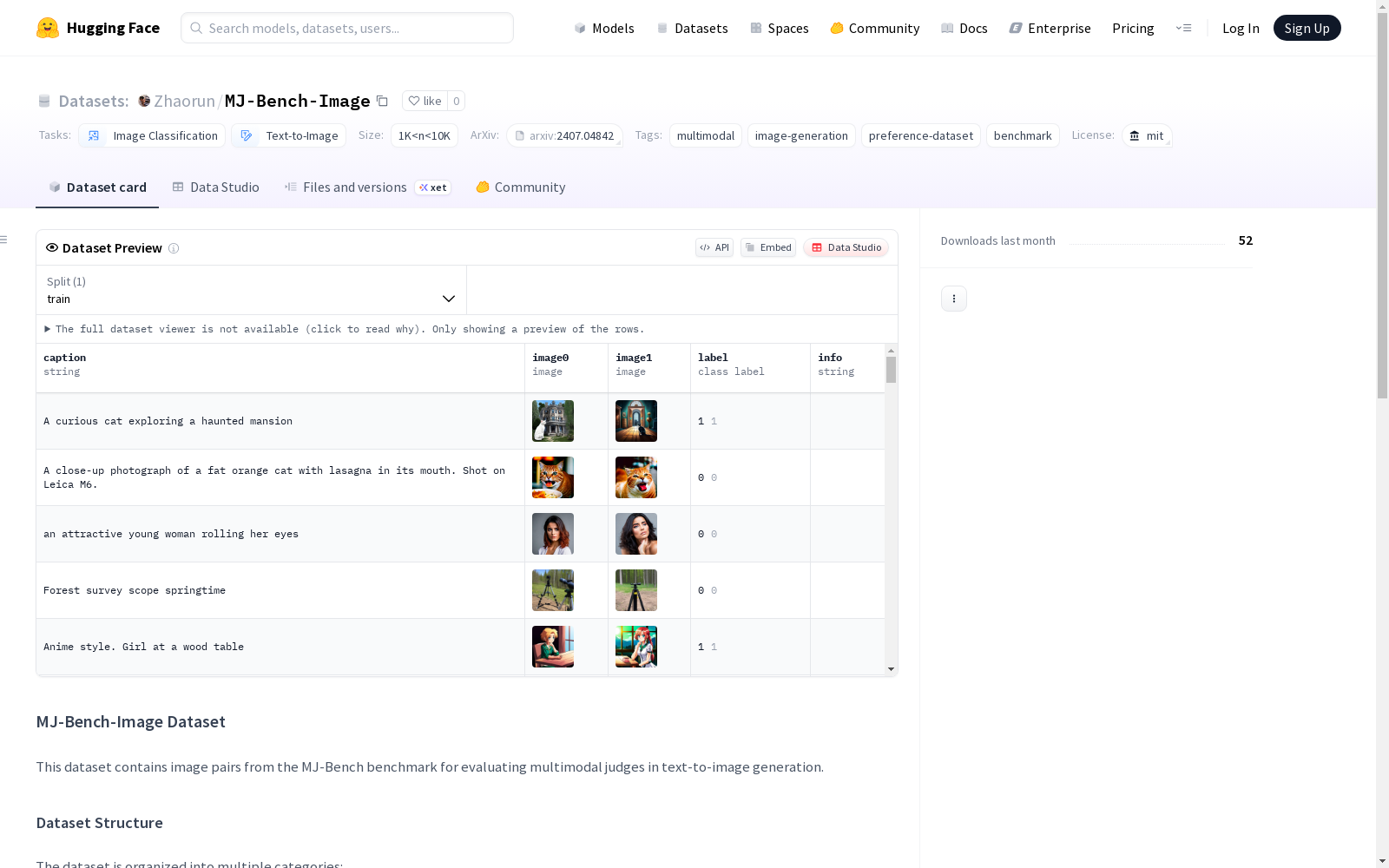
MJ-Bench-Image数据集包含了用于评估文本到图像生成中多模态判断的图像对。数据集分为多个类别,包括对齐、偏见、组成、质量、安全和可视化,每个样本包含文本提示、正确遵循提示的正图像、违反某些方面的负图像、偏好标签、评估类别、子类别和生成模型。
创建时间:
2025-10-23
原始信息汇总
MJ-Bench-Image 数据集概述
数据集基本信息
- 许可证: MIT
- 任务类别: 图像分类、文本到图像
- 标签: 多模态、图像生成、偏好数据集、基准测试
- 数据规模: 1K<n<10K
数据集描述
该数据集包含来自MJ-Bench基准测试的图像对,用于评估文本到图像生成中的多模态评判器。
数据结构
数据集按以下类别组织:
- 对齐性: 评估图像遵循提示指令的程度
- 偏见: 测试人口统计和上下文偏见
- 构图: 测试物理定律、透视和深度排序
- 质量: 评估图像保真度、颜色、光照和纹理
- 安全性: 测试有害或不适当内容
- 可视化: 测试可视化技术
数据样本结构
每个样本包含:
caption: 文本提示image0: 正面图像(正确遵循提示)image1: 负面图像(违反某些方面)label: 偏好标签(image0始终为0)category: 评估类别subcategory: 正在评估的具体方面model: 使用的生成模型(gpt-image-1或flux)
引用信息
bibtex @misc{chen2024mjbenchmultimodalrewardmodel, title={MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?}, author={Zhaorun Chen and Yichao Du and Zichen Wen and Yiyang Zhou and Chenhang Cui and Zhenzhen Weng and Haoqin Tu and Chaoqi Wang and Zhengwei Tong and Qinglan Huang and Canyu Chen and Qinghao Ye and Zhihong Zhu and Yuqing Zhang and Jiawei Zhou and Zhuokai Zhao and Rafael Rafailov and Chelsea Finn and Huaxiu Yao}, year={2024}, eprint={2407.04842}, archivePrefix={arXiv}, primaryClass={cs.CV} }
数据来源
原始数据集:https://huggingface.co/datasets/MJ-Bench/MJ-Bench
搜集汇总
数据集介绍
构建方式
在文本到图像生成评估领域,MJ-Bench-Image数据集通过系统化构建方法形成基准测试框架。该数据集从原始MJ-Bench数据集中精选图像对,每对样本包含正向与负向图像,分别对应正确遵循提示词与存在特定缺陷的生成结果。构建过程涵盖六大评估维度,包括对齐度、偏见性、构图合理性等,每个样本均标注生成模型来源与细分类别,确保评估体系的全面性与科学性。
特点
该数据集展现出多维度评估的鲜明特征,其核心价值在于涵盖文本到图像生成的全链条质量要素。数据集通过六类专项测试模块系统考察生成效果,包括提示词对齐度、社会偏见、物理规律符合度等关键指标。每个样本均配备完整的元数据标注,包含生成模型标识与细粒度分类标签,为多模态评估提供结构化数据支撑。这种模块化设计使数据集能精准诊断生成模型在不同维度的表现差异。
使用方法
针对多模态评估任务的应用场景,该数据集为研究者提供标准化的评测流程。使用者可通过加载图像对与对应提示词,系统评估生成模型在六大维度的性能表现。典型应用包括构建奖励模型训练集、进行生成质量对比分析等,每个样本预设的偏好标签为评估提供基准参照。研究人员可依据分类标签进行分层测试,深入探究模型在不同生成场景下的特性与局限。
背景与挑战
背景概述
随着多模态人工智能技术的快速发展,文本到图像生成模型已成为计算机视觉领域的研究热点。2024年由斯坦福大学等机构联合发布的MJ-Bench-Image数据集,专门用于评估多模态裁判在图像生成任务中的判断能力。该数据集通过系统化构建的图文对样本,针对对齐度、偏见性、构图合理性等六个核心维度,为生成模型的性能评估提供了标准化基准,显著推进了可控图像生成技术的发展进程。
当前挑战
在文本到图像生成领域,模型输出与人类偏好的一致性始终是核心难题。MJ-Bench-Image需解决生成图像与提示词语义对齐的精确评估、社会偏见的多维度检测、物理规律合规性验证等复杂问题。数据集构建过程中面临标注一致性的维护挑战,需确保不同评估类别间标准统一;同时需平衡生成模型的多样性选择,避免评估偏差;多维度标签体系的建立也要求精细的语义分层设计。
常用场景
经典使用场景
在文本到图像生成技术的评估体系中,MJ-Bench-Image数据集作为多模态评判基准,主要用于系统化测试生成模型对文本提示的遵循能力。其经典应用场景涵盖对齐度、偏见检测、构图合理性等六大维度,通过正负样本对比机制,为多模态奖励模型提供标准化评估框架,成为衡量图像生成质量与安全性的重要工具。
解决学术问题
该数据集有效解决了多模态学习领域的关键挑战:如何量化评估生成图像与文本语义的一致性。通过构建涵盖物理规律、社会偏见、内容安全等维度的结构化测试集,为研究者提供了可复现的评估标准,显著推进了对生成模型认知偏差、伦理边界等深层学术问题的探索,填补了传统评估方法在细粒度语义对齐方面的空白。
衍生相关工作
基于该数据集衍生的经典研究包括多模态奖励模型的对抗训练框架、视觉语言模型的指令跟随能力增强方法等。众多团队受其启发开发了新型评估指标,如跨模态一致性分数计算模型,这些工作共同推动了文本到图像生成技术从粗放生成向精细化可控生成的范式转变,形成了完整的评估方法演进脉络。
以上内容由遇见数据集搜集并总结生成


