manglish-nlp-dataset
收藏Hugging Face2026-05-31 更新2026-06-01 收录
下载链接:
https://huggingface.co/datasets/vexccz/manglish-nlp-dataset
下载链接
链接失效反馈官方服务:
资源简介:
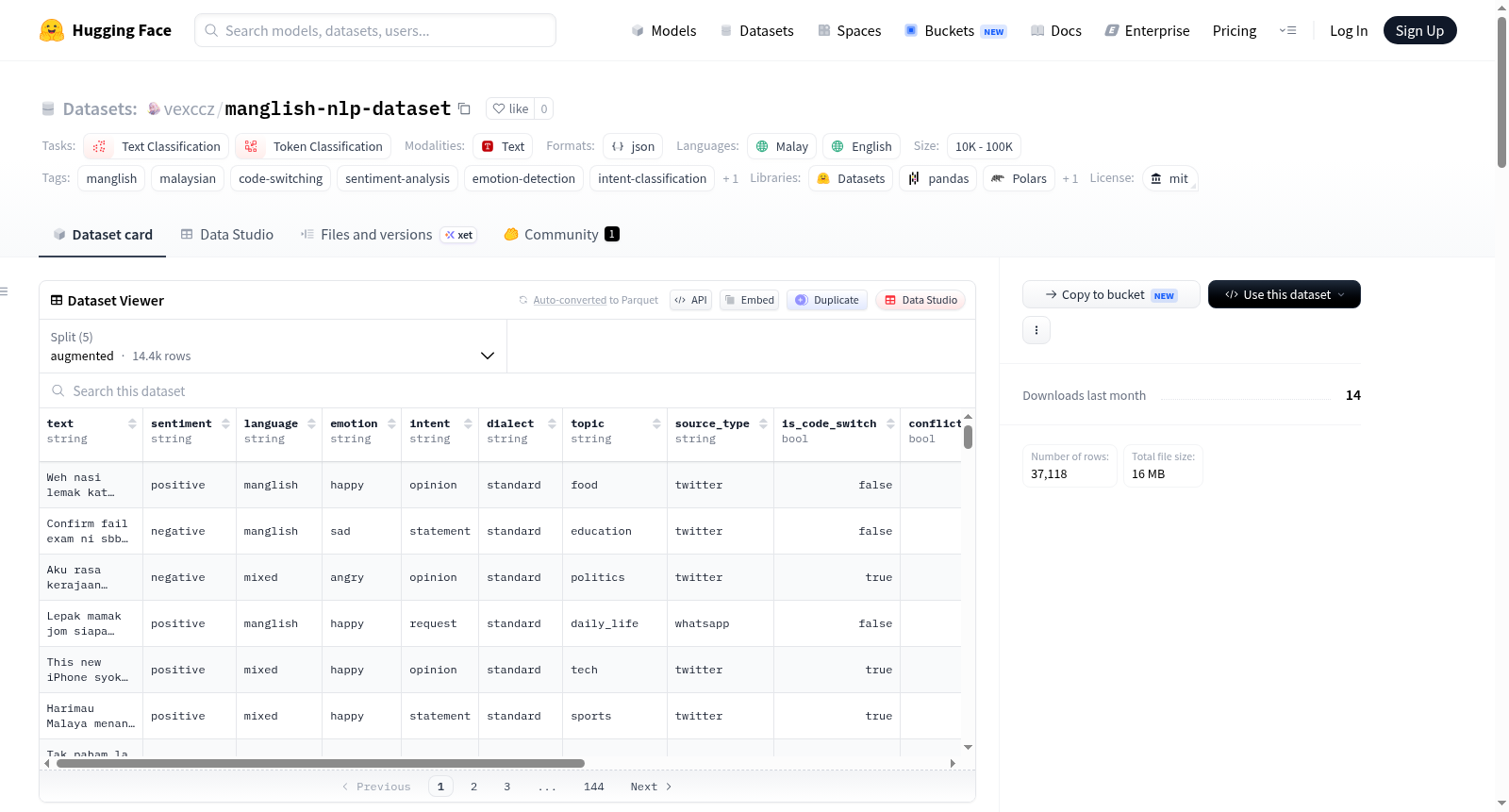
Manglish NLP数据集是一个用于多任务自然语言处理的标注数据集,包含14,384个Manglish(马来西亚英语)文本样本。Manglish是马来西亚日常生活中使用的口语化代码转换语言变体,混合了马来语、英语、汉语方言和泰米尔语,并包含本地特色小品词(如lah、la、wei、eh)、俚语和缩写,反映了马来西亚社交媒体、即时通讯应用和非正式写作的语言多样性。该数据集v3.2.0版本通过同义词替换、回译(BM>EN>BM)和掩码标记替换等数据增强方法,从7,884个原始手工构建的样本扩增而来,所有增强样本均经过标签一致性验证。每个样本包含三个独立的分类任务标注:情感分析(positive/negative/neutral三类)、情绪检测(happy/sad/angry/fear/surprise/disgust/love/neutral八类)和意图分类(question/statement/request/complaint/greeting/opinion六类)。数据集结构包含四个字段:text(输入文本字符串)、sentiment(情感标签)、emotion(情绪标签)和intent(意图标签)。数据集提供多个文件分割:增强完整集(14,384样本)、原始集(7,884样本)、训练集(6,307样本)、测试集(1,577样本)和种子数据集(1,139样本)。适用于代码转换文本分析、多任务学习、情感分析、情绪识别和意图理解等NLP研究与应用。
The Manglish NLP dataset is a labeled dataset for multitask natural language processing, containing 14,384 Manglish (Malaysian English) text samples. Manglish is a colloquial code-switching language variant used in daily life in Malaysia, mixing Malay, English, Chinese dialects, and Tamil, and includes local characteristic particles (e.g., lah, la, wei, eh), slang, and abbreviations, reflecting the linguistic diversity of Malaysian social media, instant messaging apps, and informal writing. The dataset version v3.2.0 was expanded from 7,884 originally handcrafted samples through data augmentation methods such as synonym replacement, back-translation (BM>EN>BM), and masked token replacement, with all augmented samples validated for label consistency. Each sample includes annotations for three independent classification tasks: sentiment analysis (positive/negative/neutral categories), emotion detection (happy/sad/angry/fear/surprise/disgust/love/neutral categories), and intent classification (question/statement/request/complaint/greeting/opinion categories). The dataset structure comprises four fields: text (input text string), sentiment (sentiment label), emotion (emotion label), and intent (intent label). The dataset provides multiple file splits: augmented full set (14,384 samples), original set (7,884 samples), training set (6,307 samples), test set (1,577 samples), and seed dataset (1,139 samples). It is suitable for NLP research and applications such as code-switching text analysis, multitask learning, sentiment analysis, emotion recognition, and intent understanding.
创建时间:
2026-05-29
原始信息汇总
数据集概述:Manglish NLP Dataset (v3.2.0)
该数据集是一个标注了 14,384 条 Manglish(马来西亚英语)示例的多任务自然语言处理数据集,旨在捕捉马来西亚社交媒体、即时通讯及非正式写作中的语言多样性,包括俚语、缩写、语气词(如 lah, la, wei, eh)及语码转换模式。
- 语言:马来语 (ms)、英语 (en)、Manglish(马来语-英语语码转换,混合方言和俚语)。
- 许可证:MIT License。
支持任务与标签
数据集为每条文本提供三个维度的标注,共计 14,384 条 示例:
| 任务 | 标签类别 | 数量 |
|---|---|---|
| 情感分析 | positive, negative, neutral | 14,384 |
| 情绪检测 | happy, sad, angry, fear, surprise, disgust, love, neutral (8类) | 14,384 |
| 意图分类 | question, statement, request, complaint, greeting, opinion (6类) | 14,384 |
数据集结构
每条记录包含以下字段:
| 字段 | 类型 | 描述 |
|---|---|---|
text |
字符串 | 输入文本 |
sentiment |
字符串 | 情感标签 |
emotion |
字符串 | 情绪标签 |
intent |
字符串 | 意图标签 |
文件与数据划分
| 文件 | 划分 | 示例数 | 描述 |
|---|---|---|---|
manglish_augmented.jsonl |
augmented | 14,384 | 完整数据集(原始 + 增强) |
manglish_7884.jsonl |
original | 7,884 | 原始手工标注示例 |
manglish_full_train.jsonl |
train | 6,307 | 训练集 (v1) |
manglish_full_test.jsonl |
test | 1,577 | 测试集 (v1) |
manglish_labeled_v3.jsonl |
seed | 1,139 | 初始种子数据集 |
v3.2.0 数据增强方法
数据集从 7,884 条扩展至 14,384 条,采用了以下方法并经过标签一致性验证:
- 同义词替换
- 回译(马来语 → 英语 → 马来语)
- 掩码标记替换:用上下文合适的词填充掩码位置
模型性能参考
使用 malaysian-manglish-nlp v3.2.0 模型(基于 XLM-Roberta 基础模型)在该数据集上取得的准确率:
| 任务 | 准确率 |
|---|---|
| 情感分析 | 95.0% |
| 情绪检测 | 90.3% |
| 意图分类 | 97.5% |
| 平均 | 94.3% |
使用方式
通过 HuggingFace datasets 库加载:
python from datasets import load_dataset
加载增强数据集(默认)
dataset = load_dataset("vexccz/manglish-nlp-dataset", "default", split="augmented")
加载原始数据集
original = load_dataset("vexccz/manglish-nlp-dataset", "default", split="original")
也可直接读取 JSONL 文件:
python import json
with open("manglish_augmented.jsonl", "r", encoding="utf-8") as f: data = [json.loads(line) for line in f]
相关资源
- 模型:vexccz/manglish-nlp-sentiment
- Python 包:
pip install malaysian-manglish-nlp - GitHub 仓库:https://github.com/ZafranYusof/malaysia-manglish-nlp
- 在线演示:https://huggingface.co/spaces/vexccz/manglish-nlp-demo
搜集汇总
数据集介绍
构建方式
Manglish NLP Dataset的构建以马来西亚社会媒体与即时通讯中的非正式语料为核心来源,系统捕捉了马来语、英语、华语方言及泰米尔语之间的语码混合现象。初始版本包含7,884条人工标注样本,涵盖情感、情绪与意图三类标签。v3.2.0版本通过多重数据增强策略扩增至14,384条,具体方法包括同义词替换、以马来语与英语为桥梁的回译以及掩码标记替换,所有增强样本均经过标签一致性校验,确保标注质量。
特点
该数据集的核心特色在于聚焦马来西亚英语中特有的语码转换与语用粒子(如lah、wei、eh),真实反映了当地口语及网络交流的语言变体。其多维标注体系在同一文本上同时提供情感分析、情绪检测与意图分类三种任务标签,支持多任务学习。数据分布涵盖从原始种子集到完整增强集的多个拆分版本,便于研究者在不同规模下进行实验。基于该数据集训练的XLM-RoBERTa模型在各项任务上均取得了超过90%的准确率,验证了数据的高质量与有效性。
使用方法
研究者可通过HuggingFace Datasets库便捷加载该数据集,调用load_dataset函数并指定'default'配置与所需拆分(如'augmented'或'original')即可获取标准化格式的数据。每条样本以JSON格式存储,包含text、sentiment、emotion与intent字段。亦可直接读取JSONL文件进行自定义处理。该数据集与配套的malaysian-manglish-nlp Python包及预训练模型紧密集成,支持从安装到推理的端到端工作流,降低马来西亚多语言NLP研究的入门门槛。
背景与挑战
背景概述
在全球多语言社会中,语码转换现象在非正式交流中极为普遍,马来西亚英语(Manglish)便是典型代表,其融合了马来语、英语、汉语方言及泰米尔语,展现出独特的语言混用特征。然而,现有自然语言处理资源多聚焦于标准语言,对这类混杂语种的关注极为匮乏。为此,研究人员Zafran Yusof于2026年发布了Manglish NLP Dataset(v3.2.0版),该数据集包含14,384条精细标注的马来西亚语码转换文本,涵盖情感分析、情绪检测与意图分类三大任务,旨在为低资源语码转换NLP研究提供高质量基准。该数据集通过人工标注与多种数据增强策略构建,显著推动了马来西亚语境下多任务文本理解的发展,并成为该领域的重要研究基石。
当前挑战
该数据集主要应对以下挑战。首先,在领域问题层面,马来西亚英语广泛存在于社交媒体、即时通讯等非正式场景,其词汇拼写随意、网络俚语繁多、语码转换规则非标准化,导致传统基于标准语言的NLP模型在情感、情绪及意图识别任务中表现欠佳,亟需专门数据集以捕捉此类混杂语料的语义特征。其次,在数据集构建过程中,面临标注一致性难以保证的问题,原始样本仅有7,884条,需通过同义词替换、回译(马来语→英语→马来语)及掩码填充等增强方法将规模扩充至14,384条,同时需严格验证增强样本的标签正确性,确保情感极性与语义关联不发生偏移,这构成了数据质量与效率之间的显著平衡挑战。
常用场景
经典使用场景
在大规模多语言自然语言处理研究中,Manglish NLP Dataset被广泛用于训练和评估面向马来西亚语码混合文本的多任务模型。其核心应用涵盖情感分析、情绪检测与意图分类三大经典自然语言理解任务,每个样本均标注了三个维度的标签,支持多输出联合学习。由于Manglish融合了马来语、英语、汉语方言及泰米尔语,且包含大量网络俚语、缩写和语气助词(如lah、wei),该数据集尤其适合研究低资源语码混合场景下的鲁棒表示学习。研究人员常利用其增广版本(14,384条)进行数据增强方法的验证,例如同义词替换与回译策略的有效性。
解决学术问题
该数据集系统性地解决了现实中马来西亚社交媒体文本因语码混合现象导致的语义歧义与标注稀缺问题。在学术层面,它为多任务学习在非标准语言变体上的迁移性能提供了基准,揭示了低频语言元素(如方言词、助词)在情感与意图判别中的关键影响。通过提供标准的情感、情绪与意图标签,该数据集促进了从单任务到多任务联合建模的范式转换,帮助学者量化不同任务间共享表示的信息增益。此外,其数据增强模块(掩码替换、回译)有效缓解了标注数据的稀疏性,为低资源语料库的扩充提供了方法论范例。
衍生相关工作
基于此数据集,研究者开发了专用预训练模型 'malaysian-manglish-nlp'(基于XLM-Roberta架构),该模型在情感、情绪与意图任务上分别达到95.0%、90.3%和97.5%的准确率。相关衍生工作包括一套完整的Python软件包(malaysian-manglish-nlp),提供数据增强、模型训练与推理的模块化工具链。此外,该数据集催生了针对东南亚语码混合现象的语言学分析,揭示了语气助词(如lah)在不同情感上下文中的分布规律。在线演示空间(HuggingFace Spaces)展示了实时推理效果,为跨语言NLP的普及提供了技术验证。
以上内容由遇见数据集搜集并总结生成


