CrossER
收藏数据集概述:CrossER
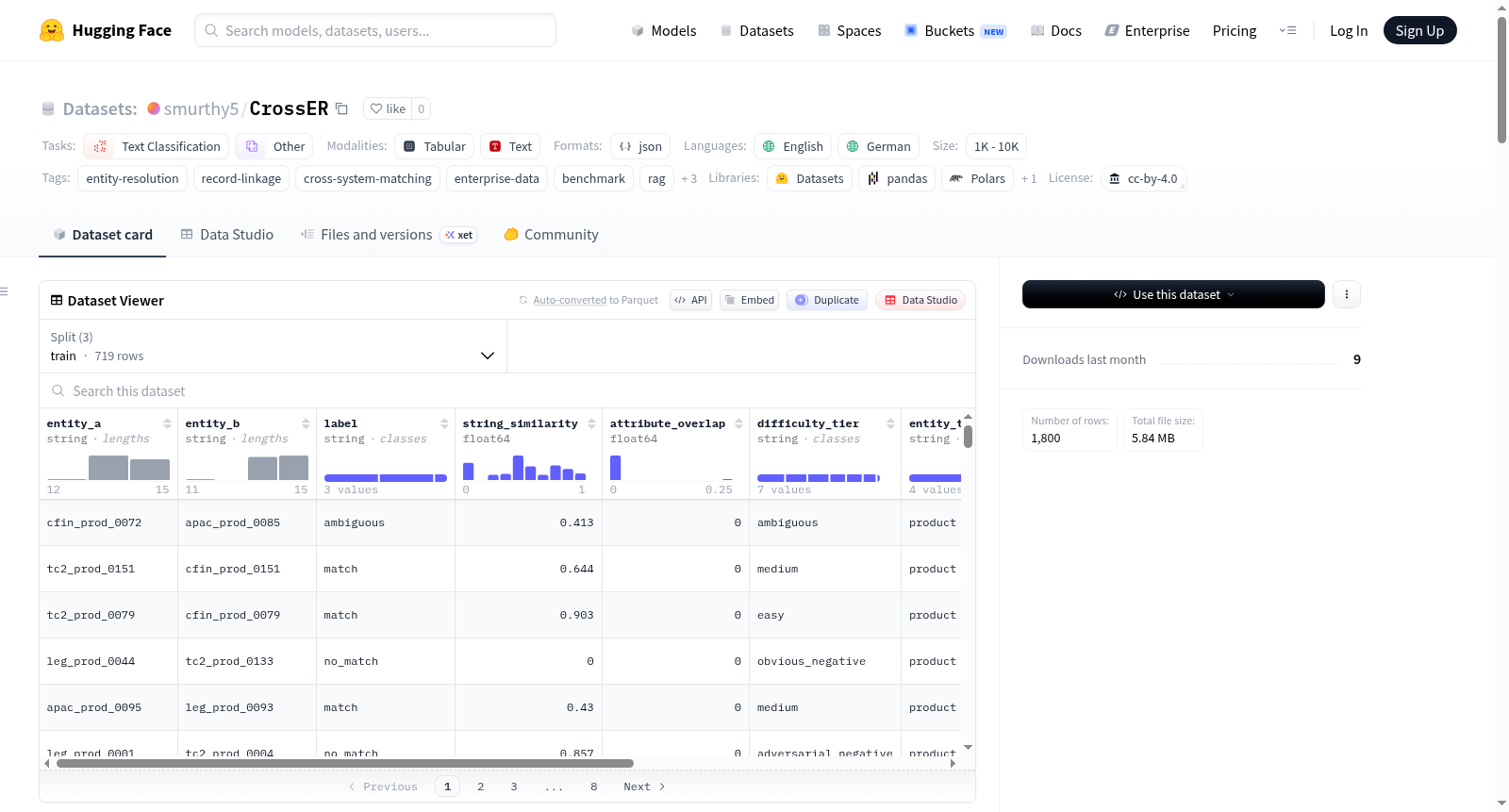
CrossER 是一个用于上下文依赖的跨系统实体消歧(Entity Resolution)的基准数据集,其核心特点是实体对的表面特征(如字符串相似度)具有误导性:匹配对的平均字符串相似度仅为 0.29,而非匹配对却高达 0.94。该数据集旨在评估模型在缺乏上下文信息时,依据属性进行判别的能力,以及在提供上下文(包括原始文档和结构化的迁移记录)后性能的提升。
数据集规模与组成
- 总实体数:688
- 总实体对:1,800
- 标签分布:匹配(Match)800 对 / 不匹配(No-Match)800 对 / 模糊(Ambiguous)200 对
- 源系统数量:5
- 实体类型数量:4
- 语言:英语、德语
- 信号文档(Signal Documents):8 篇
- 噪声文档(Noise Documents):110 篇
- 结构化上下文记录(Oracle Context Records):875 条
数据集结构
数据集的目录结构如下:
data/ ├── entities.json # 688个实体(来自5个系统) ├── pairs.json # 1800个实体对(含难度等级标签) ├── splits/ # 训练集(40%)/ 验证集(20%)/ 测试集(40%) ├── subsets/ # CrossER-Easy, -Medium, -Hard, -Full 子集 └── context/ ├── raw/documents/ # 8篇信号文档 ├── raw/noise/ # 110篇噪声文档 └── structured/ # oracle_context.json(875条记录)
评估模式
| 评估模式 | 描述 |
|---|---|
| 无上下文(No Context) | 仅使用实体对属性,评估从属性本身进行匹配的能力 |
| 原始上下文(Raw Context) | 提供118篇企业文档(8篇信号 + 110篇噪声),模拟真实的RAG(检索增强生成)场景 |
| 理想上下文(Oracle Context) | 提供875条结构化迁移记录,作为性能上限参考 |
命名子集
| 子集 | 实体对数量 | 描述 |
|---|---|---|
| CrossER-Easy | 257 | 简单匹配 + 明显负例;无上下文时的F1上限为1.000 |
| CrossER-Medium | 262 | 中等难度实体对;无上下文时的F1上限为0.776 |
| CrossER-Hard | 203 | 困难匹配 + 对抗性负例 + 模糊对;无上下文时的F1上限为0.000 |
| CrossER-Full | 722 | 所有测试实体对 |
源系统
| 系统 | 角色 | 命名风格 |
|---|---|---|
| SAP_TC2 | 主ERP系统(北美总部) | 正式英文名称 |
| SAP_CFIN | 财务合并系统 | 内部代码 / 缩写 |
| SAP_APAC | 亚太区域ERP | 带区域前缀的缩写 |
| LEGACY_ERP | 已废弃的系统(2019年) | 神秘的类别代码 |
| SHAREPOINT | 税务/合规参考系统 | 权威长名称 |
基准实验结果
| 方法 | CrossER-Easy | CrossER-Full | CrossER-Hard |
|---|---|---|---|
| 字符串匹配 | 0.741 | 0.363 | 0.000 |
| 模糊匹配 | 0.771 | 0.455 | 0.000 |
| 嵌入匹配 | 0.964 | 0.559 | 0.000 |
| 属性匹配 | 1.000 | 0.729 | 0.000 |
| SBERT(多语言) | 0.843 | 0.604 | 0.222 |
| LLM零样本 | -- | 0.090 | 0.000 |
| LLM + RAG(BM25) | 0.848 | 0.632 | 0.200 |
| LLM + 理想上下文 | 1.000 | 1.000 | 1.000 |
在无上下文条件下,所有方法在难匹配对上的F1分数均为0.00;提供理想上下文后,性能差距完全消除;RAG机制仅能部分弥补性能差距,检索质量成为瓶颈。
配置与使用
数据集可通过 datasets 库直接加载训练/验证/测试分片:
python
from datasets import load_dataset
ds = load_dataset("smurthy5/CrossER")
也可通过HTTP请求加载命名子集: python import json, requests easy = json.loads(requests.get("https://huggingface.co/datasets/smurthy5/CrossER/resolve/main/data/subsets/crosser_easy.json").text)
预测格式
预测结果应为JSON列表,每个元素包含 pair_id 和 predicted_label:
json
[
{"pair_id": "pair_0001", "predicted_label": "match"},
{"pair_id": "pair_0002", "predicted_label": "no_match"}
]
有效标签:match, no_match, ambiguous。
许可信息
- 代码:Apache 2.0
- 数据:CC BY 4.0