project-themis/Themis-CodePreference
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/project-themis/Themis-CodePreference
下载链接
链接失效反馈官方服务:
资源简介:
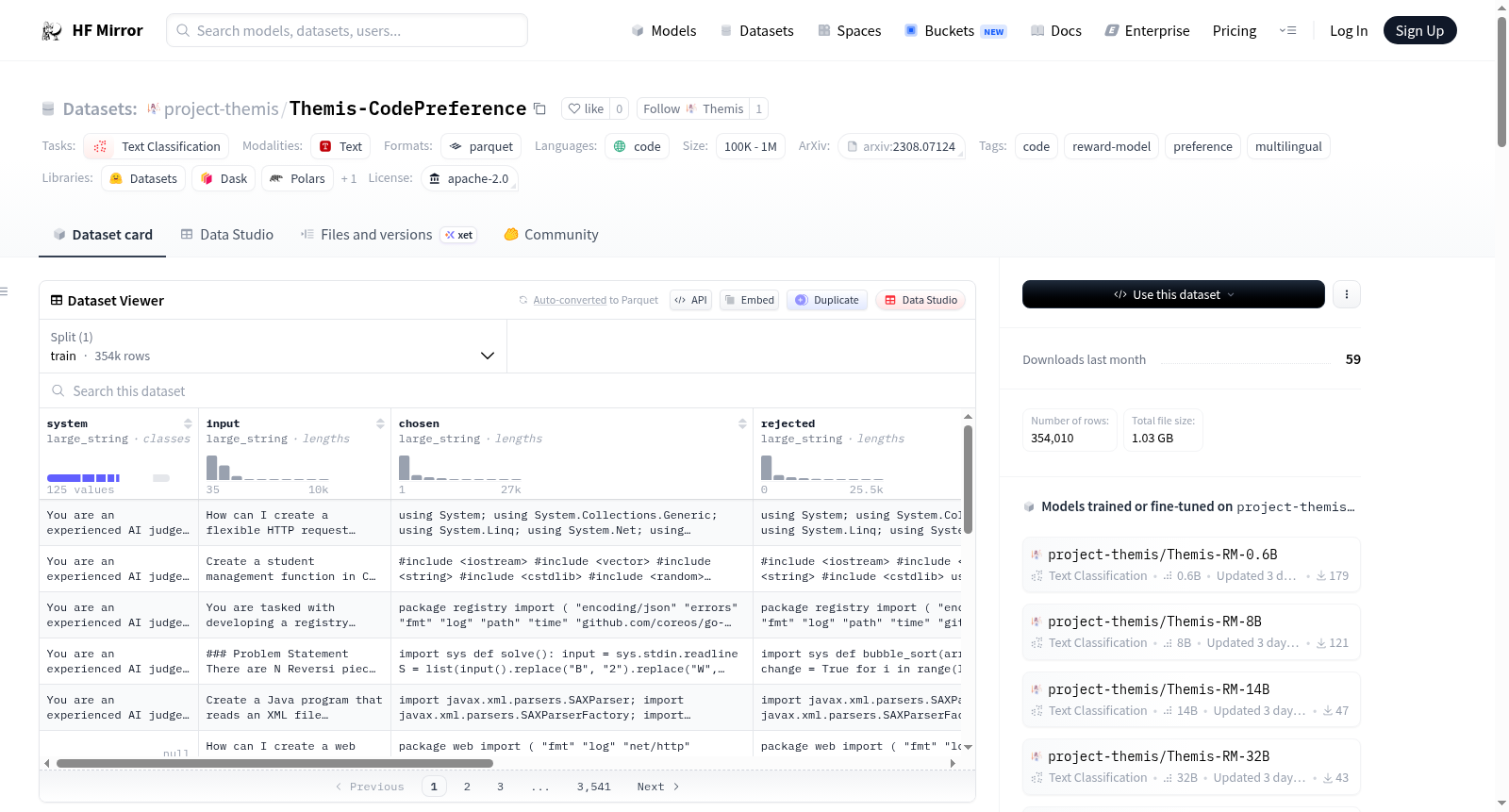
Themis-CodePreference是迄今为止最大的开源代码偏好集合,包含超过35万个偏好对。它是Themis-RM多语言代码奖励模型偏好建模(PM)阶段的主要训练数据集。该数据集涵盖了五种代码质量维度——功能正确性、运行时效率、内存效率、安全硬度和可读性与可维护性——覆盖了八种编程语言:C、C#、C++、Go、Java、JavaScript、Python和Ruby。数据集的核心是从GitHub提交(通过Themis-Git-Commits和Themis-Git-Commits-Merged挖掘)和合成错误指令调优数据中获取多样化的偏好场景,并增加了来自现有代码偏好和检索数据集的训练集。数据集由11个组成部分组成,分为四个类别:基于提交的偏好、检索与基于指令的偏好、安全偏好以及效率与正确性偏好。数据集经过严格的清洗和去污染过程,包括最大令牌长度、代码语法过滤、时间截止、语言过滤、困惑度过滤、近重复过滤和基准去污染等步骤。训练使用Bradley-Terry目标函数,辅以条件语言建模损失和奖励幅度正则化。
Themis-CodePreference is the largest open-source collection of code preferences to date, containing more than 350k preference pairs. It is the primary training dataset for the preference modeling (PM) stage of the Themis-RM suite of multilingual code reward models. The dataset covers five dimensions of code quality — Functional Correctness, Runtime Efficiency, Memory Efficiency, Security Hardness, and Readability & Maintainability — across eight programming languages: C, C#, C++, Go, Java, JavaScript, Python, and Ruby. The dataset centers on sourcing diverse preference scenarios from GitHub commits (mined from Themis-Git-Commits via Themis-Git-Commits-Merged) and from synthetically bugged instruction-tuning data, augmented with training sets from pre-existing code-preference and retrieval datasets. The dataset comprises 11 constituent sub-datasets grouped into four categories: Commit-Based Preferences, Retrieval & Instruction-Based Preferences, Security Preferences, and Efficiency & Correctness Preferences. The dataset undergoes thorough cleaning and decontamination, including max token length, code syntax filtering, temporal cutoff, language filtering, perplexity filtering, near-deduplication, and benchmark decontamination. Training uses the Bradley-Terry objective with auxiliary conditional language modeling loss and reward magnitude regularization.
提供机构:
project-themis
搜集汇总
数据集介绍
构建方式
Themis-CodePreference作为迄今规模最大的开源代码偏好数据集,其构建融合了多源异构数据与精密筛选机制。数据集核心源自GitHub提交记录中经人工审核的合并拉取请求,涵盖C、Python等八种主流编程语言,并通过ModernBERT分类器依据预定义术语表自动划分至功能正确性、运行时效率、内存效率、安全鲁棒性及可读性可维护性五大评估维度。为增强数据多样性,研究团队进一步整合了来自CodeR-Pile的检索增强偏好对、通过模型引入缺陷合成的Bugged-Instruct指令调优样本,以及ProSec安全补丁等专用数据集。所有原始样本经过去重、语法过滤、时间截断及长达4096词元的长度限制,最终形成超过35万条偏好对的高质量语料。
特点
该数据集的核心特色在于其多维度的评估体系与严谨的数据治理策略。与单一维度的代码偏好数据集不同,Themis-CodePreference同时覆盖功能正确性、运行时效率、内存效率、安全鲁棒性和可读性可维护性五个关键质量指标,为代码智能模型的细粒度评估提供了全面视角。数据集严格采用2019年3月前的人类编写GitHub提交,有效规避大语言模型生成数据的污染风险。通过MinHash近重复过滤与13-gram基准集去污染双重保障,确保了训练数据与测试基准的独立性。此外,每个样本均标注了具体的编程语言、评估维度和来源标识,支持灵活的子集选择与针对性训练。
使用方法
研究者可通过HuggingFace Datasets库便捷加载该数据集,一句代码即可获取包含系统指令、用户输入、偏好答案及拒绝答案的标准格式训练样本。在训练环节,数据集针对Themis-RM奖励模型的偏好建模阶段设计了随机系统提示策略:15%的样本不附加系统提示,60%采用包含有益性与无害性及目标维度的专项提示,25%使用涵盖全部五个代码质量维度的综合提示。建议采用Bradley-Terry优化目标配合辅助条件语言建模损失与奖励幅度正则化进行训练,设置序列长度4096、全局批次大小512,训练一个周期。数据集的类别标签结构支持按语言或评估维度进行有监督的筛选与统计分析。
背景与挑战
背景概述
Themis-CodePreference数据集由Indraneil Paul、Iryna Gurevych和Goran Glavaš于2025年创建,隶属于Themis项目,是目前规模最大的开源代码偏好数据集,包含超过35万条偏好对。该数据集专为训练多语言代码奖励模型而设计,覆盖C、C#、C++、Go、Java、JavaScript、Python和Ruby八种编程语言,并从功能正确性、运行时效率、内存效率、安全健壮性及可读性与可维护性五个维度对代码质量进行精细评估。其核心研究问题在于构建一个能够灵活捕捉多维度代码质量偏好的奖励模型训练数据集,以推动代码智能领域从单一指标评估向多准则综合评分迈进。该数据集融合了GitHub真实代码提交、合成指令微调数据以及现有数据集的偏好对,通过严格的过滤与去污过程确保数据质量,对代码奖励模型训练、代码生成评估以及代码质量自动化评估等研究方向产生了重要影响。
当前挑战
该数据集所应对的领域挑战在于代码质量评估的多维度性与主观性——传统方法往往仅关注功能正确性,而忽略了运行时效率、内存消耗、安全漏洞及代码可维护性等关键维度,且这些维度的偏好标注高度依赖专家知识,难以规模化。数据构建过程中面临的主要挑战包括:从GitHub提交中准确提取反映代码质量改进的偏好对,需借助定制化的ModernBERT分类器对提交信息进行多维度分类;确保偏好对的强度验证可靠,采用多语言大模型共识机制以降低单一模型的偏见;对合成数据引入的噪声进行有效过滤,通过AST深度检验、困惑度异常值剔除和最小哈希去重等步骤提升数据纯净度;以及执行严格的时间截断和基准去污,避免数据污染下游评估任务。
常用场景
经典使用场景
Themis-CodePreference数据集在代码智能领域扮演着核心训练资源的角色,主要用于训练多语言代码奖励模型(Reward Model)。该数据集包含超过35万对代码偏好样本,覆盖C、C++、Java、Python等八种主流编程语言,聚焦功能性正确性、运行效率、内存效率、安全鲁棒性及可读性与可维护性五个关键质量维度。研究者通过该数据集采用Bradley-Terry偏好建模目标,结合条件语言建模损失与奖励幅度正则化,训练出能够对代码生成结果进行多维偏好排序的奖励模型,从而实现对代码质量的精细化评估。
实际应用
在实际工程应用中,该数据集训练出的奖励模型能够直接服务于代码生成大模型的强化学习对齐流程,提升生成代码在功能性、效率与安全性等方面的综合质量。具体而言,模型可集成至代码补全工具、自动化代码修复系统及持续集成流水线,对开发者提交的代码变更进行即时质量评估与反馈。此外,该数据集在开源代码仓库的缺陷发现、性能优化建议生成等场景中也展现出广泛适用性,显著降低了人工代码审查的成本。
衍生相关工作
Themis-CodePreference数据集孕育了多项后续经典工作。最直接的是催生了Themis-RM多语言代码奖励模型系列,该系列模型能够对不同编程语言生成的代码进行多维度评分。在此基础上,研究者进一步构建了Themis-CodeRewardBench基准评测集,用于衡量奖励模型的偏好对齐能力。该数据集的构建方法论也启发了后续若干代码质量评估数据集的设计,推动了代码偏好类型学(如功能正确性、效率、安全等维度的精细化定义)成为代码智能领域的标准研究范式。
以上内容由遇见数据集搜集并总结生成


