Williamsanderson/MedQA-Darija-MultiLingual
收藏Hugging Face2026-05-02 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/Williamsanderson/MedQA-Darija-MultiLingual
下载链接
链接失效反馈官方服务:
资源简介:
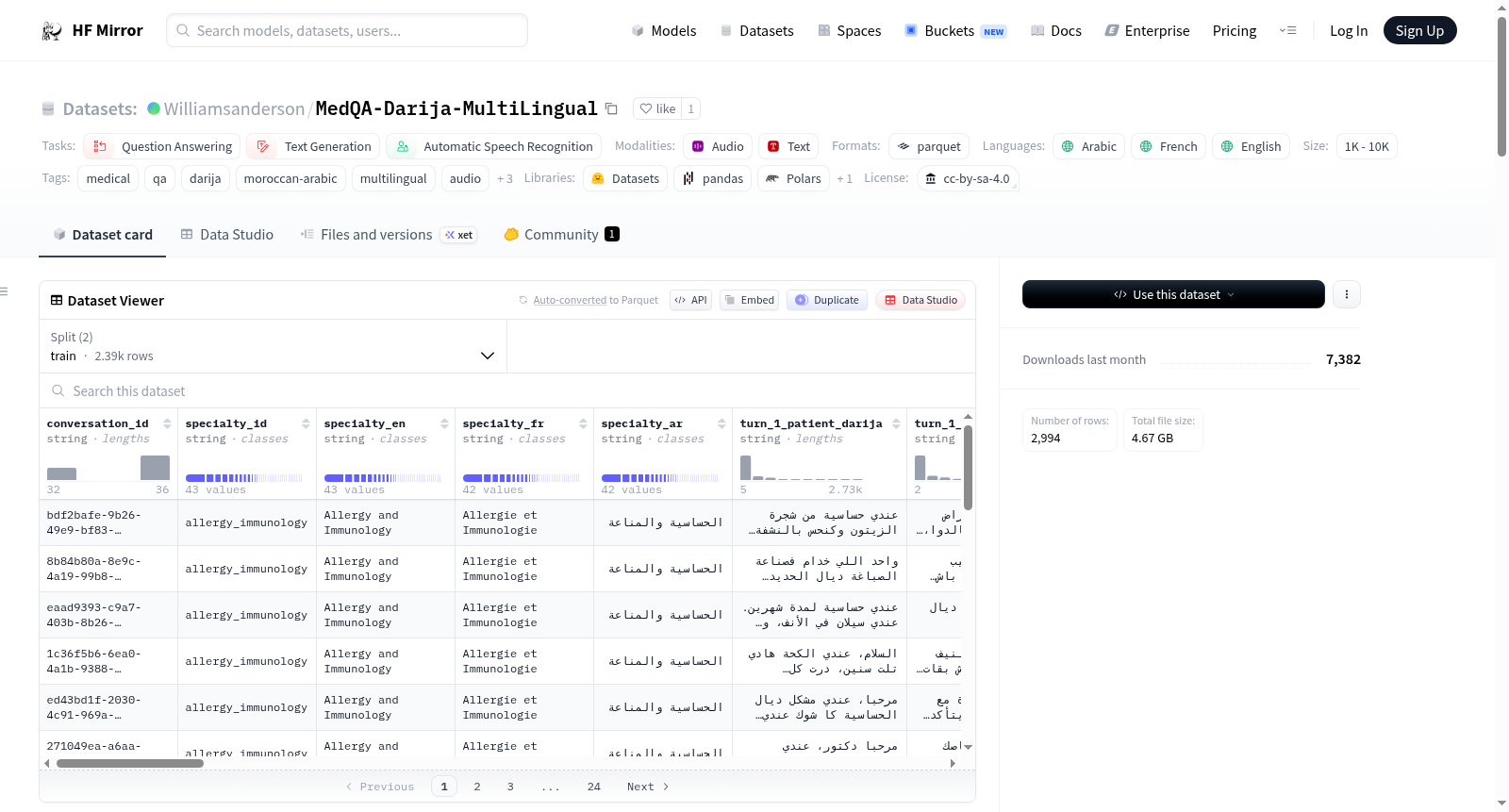
MedQA-Darija-MultiLingual是一个多语言医疗问答数据集,包含英语、法语和摩洛哥阿拉伯语(Darija)三种语言。数据集分为两个配置:default和real。default配置包含104,139对合成问答,每对问答包含6个文本回合和6个可播放的音频文件;real配置包含163,488对从公开语料库和iCliniq抓取的真实医疗问答。数据集覆盖71个医疗专业,是BRAIN HEALTH医疗NLP计划的一部分。
MedQA-Darija-MultiLingual is a trilingual medical Q&A dataset (English · French · Moroccan Arabic Darija) covering 71 medical specialties, with directly playable audio for the synthetic config. It is part of the BRAIN HEALTH medical NLP initiative. The dataset includes two configurations: default with 104,139 synthetic QA pairs and playable audio, and real with 163,488 scraped/open corpus QA pairs.
提供机构:
Williamsanderson
原始信息汇总
数据集概要:MedQA-Darija-MultiLingual
该数据集是一个大规模、开放的三语医学问答数据集,并包含可直接播放的语音音频,覆盖英语、法语和摩洛哥达里亚语(阿拉伯语书写)。它专为多语言医学自然语言处理、低资源语音识别、医疗聊天机器人和临床教育工具而设计,主要面向摩洛哥及马格里布地区。
核心统计
- 总问答对数量:267,627
- 覆盖医学专科数量:71
- 语言:英语、法语、摩洛哥达里亚语(阿拉伯语书写)
- 音频模态:每行数据包含6个MP3音频(3种语言的问答各一)
- 总数据量:约94 GB(包含约427k个MP3文件,91 GB)
数据配置
数据集包含两个主要配置:
-
default(合成数据,104,139行)- 由多个大语言模型提供商(Mistral、Cerebras、Groq、GPT-4o-mini、OpenRouter)生成的三语合成问答对。
- 每行数据包含六个可在Hub查看器中直接播放的音频。
-
real(真实世界数据,163,488行)- 从开放医学网络抓取的真实医学问答对,包含两个子来源:
scraped_icliniq(3,383行):来自iCliniq.com公开页面的患者问题和医生回答,经人工三语化处理并生成音频。open_medical_corpus(160,105行):开放医学语料库的三语翻译。
- 从开放医学网络抓取的真实医学问答对,包含两个子来源:
数据模式(每行)
| 列名 | 类型 | 描述 |
|---|---|---|
pair_id |
string | MD5生成的唯一标识符 |
specialty_id |
string | 医学专科标识(如 cardiology) |
source |
string | 数据来源 |
question_en / answer_en |
string | 英语问答 |
question_fr / answer_fr |
string | 法语问答 |
question_darija / answer_darija |
string | 摩洛哥达里亚语(阿拉伯语书写)问答 |
audio_question_en / audio_answer_en |
Audio | 英语MP3音频 |
audio_question_fr / audio_answer_fr |
Audio | 法语MP3音频 |
audio_question_darija / audio_answer_darija |
Audio | 达里亚语MP3音频 |
数据质量与清洗
- 礼貌性用语剥离:移除了不包含临床内容的模板化问候语和结束语。
- 三级验证流程:每个合成数据对需通过:
- 第一阶段:基于PubMedBERT嵌入空间的局部异常因子检测,剔除离题或幻象内容。
- 第二阶段:使用DoWhy进行因果一致性检查,标记临床推理矛盾的对子。
- 第三阶段:语言学与医学命名实体识别覆盖检查,确保达里亚语和法语的字符组成及医学实体密度达到要求。
- 音频:使用Microsoft Edge Neural TTS生成,存储在HF Xet上,可在查看器中直接播放。
预期用途
- 多语言医学问答(英语、法语、达里亚语)
- 面向低资源达里亚语的语音识别/语音合成系统
- 双语临床聊天机器人与患者教育工具
- 使用阿拉伯语书写系统的医学命名实体识别与关系抽取
- 跨语言检索与翻译评估
非预期用途
- 该数据集不能作为一级临床决策支持工具使用。
- 音频声音为合成,不能作为真实医生声音呈现。
- 任何用于生产级临床用途的翻译和临床内容,均需经过合格医生的审查。
数据集构建流程
text 真实网页抓取 → 三语翻译 → 三级验证 → Edge-TTS音频生成 → HF Parquet + 音频 大模型合成 ↗
许可协议
- 许可:CC-BY-4.0
引用信息
text @dataset{medqa_darija_multilingual_2026, title = {MedQA-Darija-MultiLingual: a trilingual medical Q&A dataset with audio for English, French, and Moroccan Darija}, author = {BRAIN HEALTH}, year = {2026}, url = {https://hf-mirror.com/datasets/Williamsanderson/MedQA-Darija-MultiLingual}, note = {Pre-publication; under medical professional review} }
搜集汇总
数据集介绍
构建方式
在医疗问答领域,构建多语言数据集对于提升医疗人工智能的包容性至关重要。MedQA-Darija-MultiLingual数据集通过精心设计的对话流程,模拟真实医患互动场景,涵盖了43个医学专科。其构建过程首先基于专业医学知识生成双语文本对话,随后利用神经语音合成技术,为每条对话的每个回合分别生成达里贾语、法语和英语的音频,确保语音与文本严格对齐。整个数据集包含近三千次对话,每行数据均整合了患者与医生在两个回合中的多语言音频与文本,形成了结构化的多模态语料。
使用方法
研究人员可利用该数据集开展跨语言的医疗人工智能研究。对于自动语音识别任务,可直接使用各语言音频及其对应转录文本进行模型训练与评估。在多语言问答与文本生成方面,数据集的结构化对话为模型理解医患交互逻辑提供了优质素材。命名实体识别任务则可基于标注的八类实体进行。此外,其多模态特性支持探索语音与文本的联合表示学习。使用前需注意遵守CC-BY-SA-4.0许可协议,并可通过HuggingFace数据集查看器直接预览和播放内嵌音频,便捷地加载与处理数据。
背景与挑战
背景概述
在医疗人工智能领域,多语言医疗对话数据集的构建对于提升全球医疗服务的可及性与公平性具有关键意义。MedQA-Darija-MultiLingual数据集由研究团队于近期创建,旨在应对摩洛哥阿拉伯语(Darija)等低资源语言在医疗自然语言处理中的代表性不足问题。该数据集涵盖了43个医学专科,包含近三千组医患对话,并同步提供了达里贾语、法语和英语三种语言的文本与音频数据,其核心研究问题聚焦于跨语言医疗问答系统的开发与评估。通过整合命名实体识别标签与可播放音频,该资源为医疗对话理解、语音识别及多语言迁移学习提供了重要基准,有望推动个性化医疗助手在多元语言环境中的实际应用。
当前挑战
该数据集致力于解决多语言医疗问答领域的核心挑战,即如何克服低资源语言如达里贾语在医疗术语标准化、语音数据稀缺以及跨语言语义对齐方面的障碍。构建过程中的具体困难包括:医学专科知识的专业性与多样性要求对话内容必须由领域专家严格审核,以确保临床准确性;多语言平行数据的采集与对齐需协调不同语言的语音合成与文本转录,在保持对话自然度的同时实现语言间的一致性;此外,达里贾语作为口语化方言,其书写形式缺乏规范,增加了文本标注与语音识别的复杂性。这些挑战共同凸显了在资源受限环境中构建高质量、可扩展医疗数据集的艰巨性。
常用场景
经典使用场景
在医疗人工智能领域,多语言医疗对话数据集MedQA-Darija-MultiLingual为构建跨语言医疗问答系统提供了关键资源。其经典使用场景集中于训练和评估多语言医疗对话模型,模型需要理解患者与医生之间涉及43个医学专科的对话内容,并处理达里贾语、法语和英语三种语言的文本与音频数据。研究者利用该数据集开发能够跨越语言障碍、准确识别医学实体并生成恰当回应的智能系统,尤其关注低资源语言如摩洛哥阿拉伯语的医疗语言处理挑战。
解决学术问题
该数据集有效解决了医疗自然语言处理中多语言与低资源语言数据稀缺的核心学术问题。它通过提供达里贾语、法语和英语的平行对话文本与音频,支持了跨语言医疗信息抽取、语音识别与机器翻译的联合研究。其标注的八类医学命名实体,如症状、疾病和药物,为细粒度医疗实体识别任务设立了基准。数据集弥合了标准阿拉伯语与方言变体之间的鸿沟,推动了面向实际口语环境的医疗人工智能技术发展,对促进健康公平具有深远意义。
实际应用
MedQA-Darija-MultiLingual数据集的实际应用直接服务于全球公共卫生与数字健康领域。它可用于开发多语言医疗聊天机器人或语音助手,为摩洛哥及法语区、英语区的患者提供初步的医疗咨询与健康信息查询服务,缓解部分地区医疗资源分布不均的压力。集成其音频数据可构建无障碍医疗辅助工具,帮助视觉障碍者或文盲群体通过语音交互获取医疗知识。此外,该资源也能用于培训医学生的跨文化沟通能力,或作为医疗翻译系统的训练语料。
数据集最近研究
最新研究方向
在医疗人工智能领域,多语言医疗对话数据集的构建正成为突破语言障碍、提升医疗可及性的关键。MedQA-Darija-MultiLingual数据集以其涵盖摩洛哥阿拉伯语、法语和英语的三语平行对话及可播放音频,为低资源语言医疗自然语言处理研究提供了珍贵资源。当前前沿研究聚焦于跨语言医疗实体识别与多模态对话系统的融合,利用该数据集的音频与文本对齐特性,探索语音驱动下的医疗问答与诊断辅助。这一方向不仅响应了全球健康公平化倡议,也为构建包容性医疗人工智能系统奠定了数据基础,在数字健康与语言技术交叉领域具有显著影响力。
以上内容由遇见数据集搜集并总结生成


