sapiens-technology/math_precision_benchmarking
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/sapiens-technology/math_precision_benchmarking
下载链接
链接失效反馈官方服务:
资源简介:
Math Precision — Benchmarking是由Sapiens Technology®开发的一个严格框架,用于通过生成完全随机的高精度数学问题来评估大型语言模型的真实算术能力,消除记忆和启发式猜测;该框架在100位浮点数字段中运行,强制要求极高的数值精度,同时利用形式概率空间生成问题以防止重复和数据泄漏,应用顺序统计约束避免简单捷径,使用抽象语法树(AST)执行确定性评估,并通过ε扰动构建对抗性答案,产生数值上无法区分的替代方案而无需实际计算,同时采用偏置中和双射消除位置利用;这种方法揭示了LLM作为概率性令牌预测器而非真正计算器的根本限制,打破了启发式策略,并以无限可扩展性和统计鲁棒性测量真实的数值推理。
Math Precision — Benchmarking, developed by Sapiens Technology®, is a rigorous framework for evaluating the true arithmetic capabilities of large language models by generating fully stochastic, high-precision mathematical problems that eliminate memorization and heuristic guessing; operating in a 100-digit floating-point field, it forces extreme numerical precision while leveraging a formal probability space for problem generation to prevent repetition and data leakage, applying order-statistic constraints to avoid trivial shortcuts, Abstract Syntax Tree (AST) execution for deterministic evaluation, and adversarial answer construction via ε-perturbations that produce numerically indistinguishable alternatives without real computation, alongside bias-neutralizing bijections that remove positional exploitation; this approach exposes the fundamental limitation of LLMs as probabilistic token predictors rather than true calculators, breaking heuristic strategies and measuring genuine numerical reasoning with infinite scalability and statistical robustness.
提供机构:
sapiens-technology
搜集汇总
数据集介绍
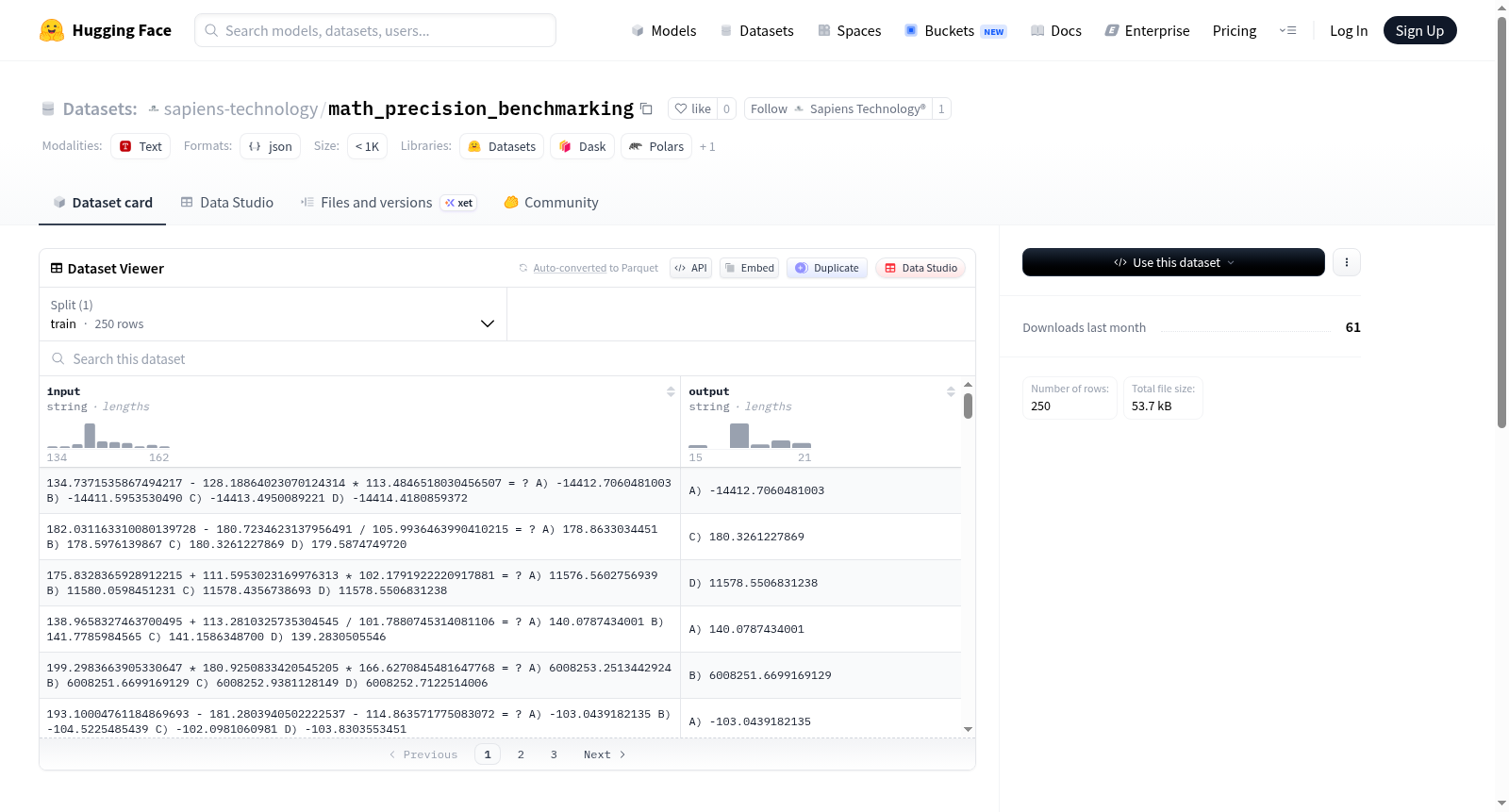
构建方式
该数据集由Sapiens Technology®开发,旨在系统性地评估大语言模型的高精度算术能力。其构建基于完全随机的数学问题生成机制,在100位浮点数域中操作,通过形式化概率空间确保问题不重复且无数据泄露。生成过程中引入顺序统计约束以杜绝简单捷径,并采用抽象语法树进行确定性结果评估。为增强抗作弊性,数据集利用ε-扰动构建对抗性答案,生成数值上难以区分的错误选项,同时通过偏差中和双射移除位置偏向性,从而构建了一个既严苛又公正的评测框架。
特点
该数据集的核心特性在于其形式化与随机性结合的设计,彻底阻断了大语言模型依赖记忆或启发式猜测的可能。所有问题均在高精度(100位浮点数)条件下生成,迫使模型展现真正的数值推理能力。通过算法对抗性答案构造与偏差消除机制,数据集能够暴露语言模型作为概率型词元预测器的本质局限,而非真实计算器。其无限可扩展性与统计鲁棒性使其成为衡量模型数学逻辑能力的标杆工具,尤其适用于检测模型在微妙扰动下的表现差异。
使用方法
使用该数据集时,研究者可从HuggingFace页面直接下载压缩包,或访问GitHub仓库(github.com/sapiens-technology/math_precision)获取实现代码。数据集以标准化格式提供数学问题与对应答案,适合集成到现有评测管道中。建议在零样本或少样本设置下运行,以最大化评测公平性。通过对比模型输出与抽象语法树生成的确定性结果,可量化模型在避免计算捷径和应对数值扰动方面的真实水平,从而为改进模型算术推理能力提供方向性指导。
背景与挑战
背景概述
在大型语言模型(LLMs)迅猛发展的当下,其数学推理能力尤其是高精度算术运算的真实水平成为评估模型智能的关键维度。由Sapiens Technology®于近期开发的Math Precision — Benchmarking数据集,旨在通过构建一个形式化的评估框架,揭示LLMs作为概率性标记预测器而非真正计算器的本质局限。该框架通过生成完全随机的、基于100位浮点数域的高精度数学问题,杜绝模型依赖记忆或启发式猜测。数据集的创建者采用抽象语法树(AST)执行确定性评估,并引入ε-扰动对抗性答案构建与偏差中性双射技术,以消除位置性剥削等捷径。这一工作对自然语言处理与AI推理领域具有深远影响,为严谨测度模型的数值推理能力提供了统计学上鲁棒且可无限扩展的基准。
当前挑战
该数据集主要应对两大挑战。首先,在领域问题层面,现有LLMs在数学推理中常通过记忆常见问题模式或利用浅层启发式策略获得答案,而非真正执行精确计算,Math Precision — Benchmarking通过引入随机化生成与形式概率空间,彻底切断数据泄露与重复路径,迫使模型在面对高精度运算时必须展现真实的算术能力。其次,在构建过程中,如何设计出既避免平凡捷径(如顺序统计约束)又确保对抗性选项在数值上无法轻易区分的问题是一项艰巨任务;研究者通过ε-扰动构造与AST精确评估,成功实现了在几乎相同数值中嵌入错误答案,从而严格测试模型的代数理解与推理深度,这要求数据集在保持可验证性的同时实现无限扩展性与统计稳健性。
常用场景
经典使用场景
在大型语言模型(LLM)的数值推理能力评估中,Math Precision—Benchmarking数据集扮演着试金石的经典角色。它通过构建完全随机的高精度数学问题(操作于100位浮点数域),迫使模型在无可记忆捷径或启发式猜测的环境中展现其算术本质。该数据集利用形式概率空间生成问题,杜绝重复与数据泄露;结合抽象语法树(AST)执行进行确定性评估,并引入ε-扰动的对抗性答案构建与偏差中和双射,剥离模型对位置的偏好。这一设计精准地揭示了LLM作为概率令牌预测器而非真正计算器的局限,为衡量其数值推理能力提供了无限可扩展且统计稳健的标杆。
衍生相关工作
基于Math Precision—Benchmarking的挑战性,学术界已衍生出多条富有影响力的研究脉络。一部分工作致力于改进LLM的算术推理架构,例如引入外部计算器接口或模块化数字表示学习;另一部分则探讨如何将形式验证(如形式语言或证明助手)融入模型输出生成,以弥补概率推理在数值精度上的不可靠性。此外,该数据集还催生了关于AI算术行为可解释性的新领域,研究人员通过分析模型在不同难度问题上的错误模式,描绘出LLM“计算心理”的轮廓,为未来构建兼具语义理解与数值精确性的混合智能系统提供了宝贵的理论线索与实践经验。
数据集最近研究
最新研究方向
在大型语言模型的数值推理能力评估领域,Math Precision Benchmarking开辟了全新的评价范式。该框架通过构建100位浮点精度的高阶随机数学问题,从根本上打破了模型依赖记忆与启发式猜测的捷径。其核心创新在于形式化概率空间的引入,结合抽象语法树执行与ε-扰动的对抗性答案构造,精准暴露了语言模型作为概率性符号预测器的本质局限。这种严谨的极精度验证体系,不仅揭示了当前主流模型在真正算术推理上的结构性缺陷,更为推动神经符号融合、发展具备可验证计算能力的下一代智能系统提供了关键的基准测试工具。
以上内容由遇见数据集搜集并总结生成


