Helsinki-NLP/opus_wikipedia
收藏Hugging Face2024-02-22 更新2024-04-20 收录
下载链接:
https://hf-mirror.com/datasets/Helsinki-NLP/opus_wikipedia
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- found
language_creators:
- found
language:
- ar
- bg
- cs
- de
- el
- en
- es
- fa
- fr
- he
- hu
- it
- nl
- pl
- pt
- ro
- ru
- sl
- tr
- vi
license:
- unknown
multilinguality:
- multilingual
size_categories:
- 100K<n<1M
- 10K<n<100K
source_datasets:
- original
task_categories:
- translation
task_ids: []
pretty_name: OpusWikipedia
config_names:
- ar-en
- ar-pl
- en-ru
- en-sl
- en-vi
dataset_info:
- config_name: ar-en
features:
- name: id
dtype: string
- name: translation
dtype:
translation:
languages:
- ar
- en
splits:
- name: train
num_bytes: 45207523
num_examples: 151136
download_size: 26617751
dataset_size: 45207523
- config_name: ar-pl
features:
- name: id
dtype: string
- name: translation
dtype:
translation:
languages:
- ar
- pl
splits:
- name: train
num_bytes: 304850680
num_examples: 823715
download_size: 175806051
dataset_size: 304850680
- config_name: en-ru
features:
- name: id
dtype: string
- name: translation
dtype:
translation:
languages:
- en
- ru
splits:
- name: train
num_bytes: 167648361
num_examples: 572717
download_size: 97008376
dataset_size: 167648361
- config_name: en-sl
features:
- name: id
dtype: string
- name: translation
dtype:
translation:
languages:
- en
- sl
splits:
- name: train
num_bytes: 30479559
num_examples: 140124
download_size: 18557819
dataset_size: 30479559
- config_name: en-vi
features:
- name: id
dtype: string
- name: translation
dtype:
translation:
languages:
- en
- vi
splits:
- name: train
num_bytes: 7571526
num_examples: 58116
download_size: 3969559
dataset_size: 7571526
configs:
- config_name: ar-en
data_files:
- split: train
path: ar-en/train-*
- config_name: ar-pl
data_files:
- split: train
path: ar-pl/train-*
- config_name: en-ru
data_files:
- split: train
path: en-ru/train-*
- config_name: en-sl
data_files:
- split: train
path: en-sl/train-*
- config_name: en-vi
data_files:
- split: train
path: en-vi/train-*
---
# Dataset Card for OpusWikipedia
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** http://opus.nlpl.eu/Wikipedia.php
- **Repository:** None
- **Paper:** http://www.lrec-conf.org/proceedings/lrec2012/pdf/463_Paper.pdf
- **Leaderboard:** [More Information Needed]
- **Point of Contact:** [More Information Needed]
### Dataset Summary
This is a corpus of parallel sentences extracted from Wikipedia by Krzysztof Wołk and Krzysztof Marasek.
Tha dataset contains 20 languages and 36 bitexts.
To load a language pair which isn't part of the config, all you need to do is specify the language code as pairs,
e.g.
```python
dataset = load_dataset("opus_wikipedia", lang1="it", lang2="pl")
```
You can find the valid pairs in Homepage section of Dataset Description: http://opus.nlpl.eu/Wikipedia.php
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The languages in the dataset are:
- ar
- bg
- cs
- de
- el
- en
- es
- fa
- fr
- he
- hu
- it
- nl
- pl
- pt
- ro
- ru
- sl
- tr
- vi
## Dataset Structure
### Data Instances
```
{
'id': '0',
'translation': {
"ar": "* Encyclopaedia of Mathematics online encyclopaedia from Springer, Graduate-level reference work with over 8,000 entries, illuminating nearly 50,000 notions in mathematics.",
"en": "*Encyclopaedia of Mathematics online encyclopaedia from Springer, Graduate-level reference work with over 8,000 entries, illuminating nearly 50,000 notions in mathematics."
}
}
```
### Data Fields
- `id` (`str`): Unique identifier of the parallel sentence for the pair of languages.
- `translation` (`dict`): Parallel sentences for the pair of languages.
### Data Splits
The dataset contains a single `train` split.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
[More Information Needed]
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
[More Information Needed]
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```bibtex
@article{WOLK2014126,
title = {Building Subject-aligned Comparable Corpora and Mining it for Truly Parallel Sentence Pairs},
journal = {Procedia Technology},
volume = {18},
pages = {126-132},
year = {2014},
note = {International workshop on Innovations in Information and Communication Science and Technology, IICST 2014, 3-5 September 2014, Warsaw, Poland},
issn = {2212-0173},
doi = {https://doi.org/10.1016/j.protcy.2014.11.024},
url = {https://www.sciencedirect.com/science/article/pii/S2212017314005453},
author = {Krzysztof Wołk and Krzysztof Marasek},
keywords = {Comparable corpora, machine translation, NLP},
}
```
```bibtex
@InProceedings{TIEDEMANN12.463,
author = {J{\"o}rg Tiedemann},
title = {Parallel Data, Tools and Interfaces in OPUS},
booktitle = {Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC'12)},
year = {2012},
month = {may},
date = {23-25},
address = {Istanbul, Turkey},
editor = {Nicoletta Calzolari (Conference Chair) and Khalid Choukri and Thierry Declerck and Mehmet Ugur Dogan and Bente Maegaard and Joseph Mariani and Jan Odijk and Stelios Piperidis},
publisher = {European Language Resources Association (ELRA)},
isbn = {978-2-9517408-7-7},
language = {english}
}
```
### Contributions
Thanks to [@rkc007](https://github.com/rkc007) for adding this dataset.
注释创建者(annotations_creators):
- 现有数据提取(found)
语言创建者(language_creators):
- 现有数据提取(found)
语言(language):
- 阿拉伯语(ar)
- 保加利亚语(bg)
- 捷克语(cs)
- 德语(de)
- 希腊语(el)
- 英语(en)
- 西班牙语(es)
- 波斯语(fa)
- 法语(fr)
- 希伯来语(he)
- 匈牙利语(hu)
- 意大利语(it)
- 荷兰语(nl)
- 波兰语(pl)
- 葡萄牙语(pt)
- 罗马尼亚语(ro)
- 俄语(ru)
- 斯洛文尼亚语(sl)
- 土耳其语(tr)
- 越南语(vi)
许可协议(license):
- 未知(unknown)
多语言属性(multilinguality):
- 多语言(multilingual)
规模类别(size_categories):
- 十万至百万级(100K<n<1M)
- 一万至十万级(10K<n<100K)
源数据集(source_datasets):
- 原始数据集(original)
任务类别(task_categories):
- 机器翻译(translation)
任务子类别(task_ids):[]
展示名称(pretty_name):OpusWikipedia
配置名称列表(config_names):
- ar-en
- ar-pl
- en-ru
- en-sl
- en-vi
数据集信息(dataset_info):
- 配置名称(config_name):ar-en
特征(features):
- 字段名:id
数据类型(dtype):字符串(string)
- 字段名:translation
数据类型(dtype):
翻译对(translation):
包含语言:阿拉伯语(ar)、英语(en)
数据划分(splits):
- 划分名称:训练集(train)
字节数:45207523
样本数:151136
下载大小:26617751
数据集大小:45207523
- 配置名称(config_name):ar-pl
特征(features):
- 字段名:id
数据类型(dtype):字符串(string)
- 字段名:translation
数据类型(dtype):
翻译对(translation):
包含语言:阿拉伯语(ar)、波兰语(pl)
数据划分(splits):
- 划分名称:训练集(train)
字节数:304850680
样本数:823715
下载大小:175806051
数据集大小:304850680
- 配置名称(config_name):en-ru
特征(features):
- 字段名:id
数据类型(dtype):字符串(string)
- 字段名:translation
数据类型(dtype):
翻译对(translation):
包含语言:英语(en)、俄语(ru)
数据划分(splits):
- 划分名称:训练集(train)
字节数:167648361
样本数:572717
下载大小:97008376
数据集大小:167648361
- 配置名称(config_name):en-sl
特征(features):
- 字段名:id
数据类型(dtype):字符串(string)
- 字段名:translation
数据类型(dtype):
翻译对(translation):
包含语言:英语(en)、斯洛文尼亚语(sl)
数据划分(splits):
- 划分名称:训练集(train)
字节数:30479559
样本数:140124
下载大小:18557819
数据集大小:30479559
- 配置名称(config_name):en-vi
特征(features):
- 字段名:id
数据类型(dtype):字符串(string)
- 字段名:translation
数据类型(dtype):
翻译对(translation):
包含语言:英语(en)、越南语(vi)
数据划分(splits):
- 划分名称:训练集(train)
字节数:7571526
样本数:58116
下载大小:3969559
数据集大小:7571526
配置列表(configs):
- 配置名称(config_name):ar-en
数据文件(data_files):
- 划分:训练集(train)
路径:ar-en/train-*
- 配置名称(config_name):ar-pl
数据文件(data_files):
- 划分:训练集(train)
路径:ar-pl/train-*
- 配置名称(config_name):en-ru
数据文件(data_files):
- 划分:训练集(train)
路径:en-ru/train-*
- 配置名称(config_name):en-sl
数据文件(data_files):
- 划分:训练集(train)
路径:en-sl/train-*
- 配置名称(config_name):en-vi
数据文件(data_files):
- 划分:训练集(train)
路径:en-vi/train-*
# OpusWikipedia 数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集概述](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [涉及语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集创建](#dataset-creation)
- [筛选依据](#curation-rationale)
- [源数据](#source-data)
- [注释](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知限制](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献致谢](#contributions)
## 数据集描述
- **主页(Homepage)**: http://opus.nlpl.eu/Wikipedia.php
- **代码仓库(Repository)**: 无
- **相关论文(Paper)**: http://www.lrec-conf.org/proceedings/lrec2012/pdf/463_Paper.pdf
- **排行榜(Leaderboard)**: [需补充更多信息]
- **联系方式(Point of Contact)**: [需补充更多信息]
### 数据集概述
本数据集为由Krzysztof Wołk与Krzysztof Marasek从维基百科中提取的平行语句语料库。
该数据集涵盖20种语言,共包含36个双语语料对。
若需加载现有配置未包含的语言对,仅需指定语言代码组合即可,示例如下:
python
dataset = load_dataset("opus_wikipedia", lang1="it", lang2="pl")
可在数据集描述的主页链接处查询合法语言对:http://opus.nlpl.eu/Wikipedia.php
### 支持任务与排行榜
[需补充更多信息]
### 涉及语言
该数据集涉及的语言如下:
- 阿拉伯语(ar)
- 保加利亚语(bg)
- 捷克语(cs)
- 德语(de)
- 希腊语(el)
- 英语(en)
- 西班牙语(es)
- 波斯语(fa)
- 法语(fr)
- 希伯来语(he)
- 匈牙利语(hu)
- 意大利语(it)
- 荷兰语(nl)
- 波兰语(pl)
- 葡萄牙语(pt)
- 罗马尼亚语(ro)
- 俄语(ru)
- 斯洛文尼亚语(sl)
- 土耳其语(tr)
- 越南语(vi)
## 数据集结构
### 数据实例
{
'id': '0',
'translation': {
"ar": "* Encyclopaedia of Mathematics online encyclopaedia from Springer, Graduate-level reference work with over 8,000 entries, illuminating nearly 50,000 notions in mathematics.",
"en": "*Encyclopaedia of Mathematics online encyclopaedia from Springer, Graduate-level reference work with over 8,000 entries, illuminating nearly 50,000 notions in mathematics."
}
}
### 数据字段
- `id`(字符串类型):该双语平行语句的唯一标识符。
- `translation`(字典类型):对应语言对的平行语句集合。
### 数据划分
该数据集仅包含一个`train`(训练集)划分。
## 数据集创建
### 筛选依据
[需补充更多信息]
### 源数据
[需补充更多信息]
#### 初始数据收集与标准化
[需补充更多信息]
#### 源语言文本创作者是谁?
[需补充更多信息]
### 注释
[需补充更多信息]
#### 注释流程
[需补充更多信息]
#### 注释者是谁?
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据使用注意事项
### 数据集的社会影响
[需补充更多信息]
### 偏差讨论
[需补充更多信息]
### 其他已知限制
[需补充更多信息]
## 附加信息
### 数据集维护者
[需补充更多信息]
### 许可信息
[需补充更多信息]
### 引用信息
bibtex
@article{WOLK2014126,
title = {Building Subject-aligned Comparable Corpora and Mining it for Truly Parallel Sentence Pairs},
journal = {Procedia Technology},
volume = {18},
pages = {126-132},
year = {2014},
note = {International workshop on Innovations in Information and Communication Science and Technology, IICST 2014, 3-5 September 2014, Warsaw, Poland},
issn = {2212-0173},
doi = {https://doi.org/10.1016/j.protcy.2014.11.024},
url = {https://www.sciencedirect.com/science/article/pii/S2212017314005453},
author = {Krzysztof Wołk and Krzysztof Marasek},
keywords = {Comparable corpora, machine translation, NLP},
}
bibtex
@InProceedings{TIEDEMANN12.463,
author = {J{"o}rg Tiedemann},
title = {Parallel Data, Tools and Interfaces in OPUS},
booktitle = {Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC'12)},
year = {2012},
month = {may},
date = {23-25},
address = {Istanbul, Turkey},
editor = {Nicoletta Calzolari (Conference Chair) and Khalid Choukri and Thierry Declerck and Mehmet Ugur Dogan and Bente Maegaard and Joseph Mariani and Jan Odijk and Stelios Piperidis},
publisher = {European Language Resources Association (ELRA)},
isbn = {978-2-9517408-7-7},
language = {english}
}
### 贡献致谢
感谢[@rkc007](https://github.com/rkc007)为本数据集的收录提供贡献。
提供机构:
Helsinki-NLP
原始信息汇总
数据集概述
名称: OpusWikipedia
语言: 支持多种语言,包括阿拉伯语(ar)、保加利亚语(bg)、捷克语(cs)、德语(de)、希腊语(el)、英语(en)、西班牙语(es)、波斯语(fa)、法语(fr)、希伯来语(he)、匈牙利语(hu)、意大利语(it)、荷兰语(nl)、波兰语(pl)、葡萄牙语(pt)、罗马尼亚语(ro)、俄语(ru)、斯洛文尼亚语(sl)、土耳其语(tr)、越南语(vi)。
许可证: 未知
多语言性: 多语言
大小: 包含两个大小类别,10K<n<100K 和 100K<n<1M。
源数据集: 原始数据
任务类别: 翻译
配置名称: 包括 ar-en, ar-pl, en-ru, en-sl, en-vi 等。
数据集结构
数据实例:
- id (字符串): 唯一标识符。
- translation (字典): 包含两种语言的平行句子。
数据字段:
id: 字符串类型,平行句子的唯一标识符。translation: 字典类型,包含两种语言的平行句子。
数据分割:
train: 训练集,包含不同语言对的字节数和示例数。
数据集详细信息
ar-en配置:
- 训练集: 字节数45207523,示例数151136。
- 下载大小: 26617751字节。
- 数据集大小: 45207523字节。
ar-pl配置:
- 训练集: 字节数304850680,示例数823715。
- 下载大小: 175806051字节。
- 数据集大小: 304850680字节。
en-ru配置:
- 训练集: 字节数167648361,示例数572717。
- 下载大小: 97008376字节。
- 数据集大小: 167648361字节。
en-sl配置:
- 训练集: 字节数30479559,示例数140124。
- 下载大小: 18557819字节。
- 数据集大小: 30479559字节。
en-vi配置:
- 训练集: 字节数7571526,示例数58116。
- 下载大小: 3969559字节。
- 数据集大小: 7571526字节。
搜集汇总
数据集介绍
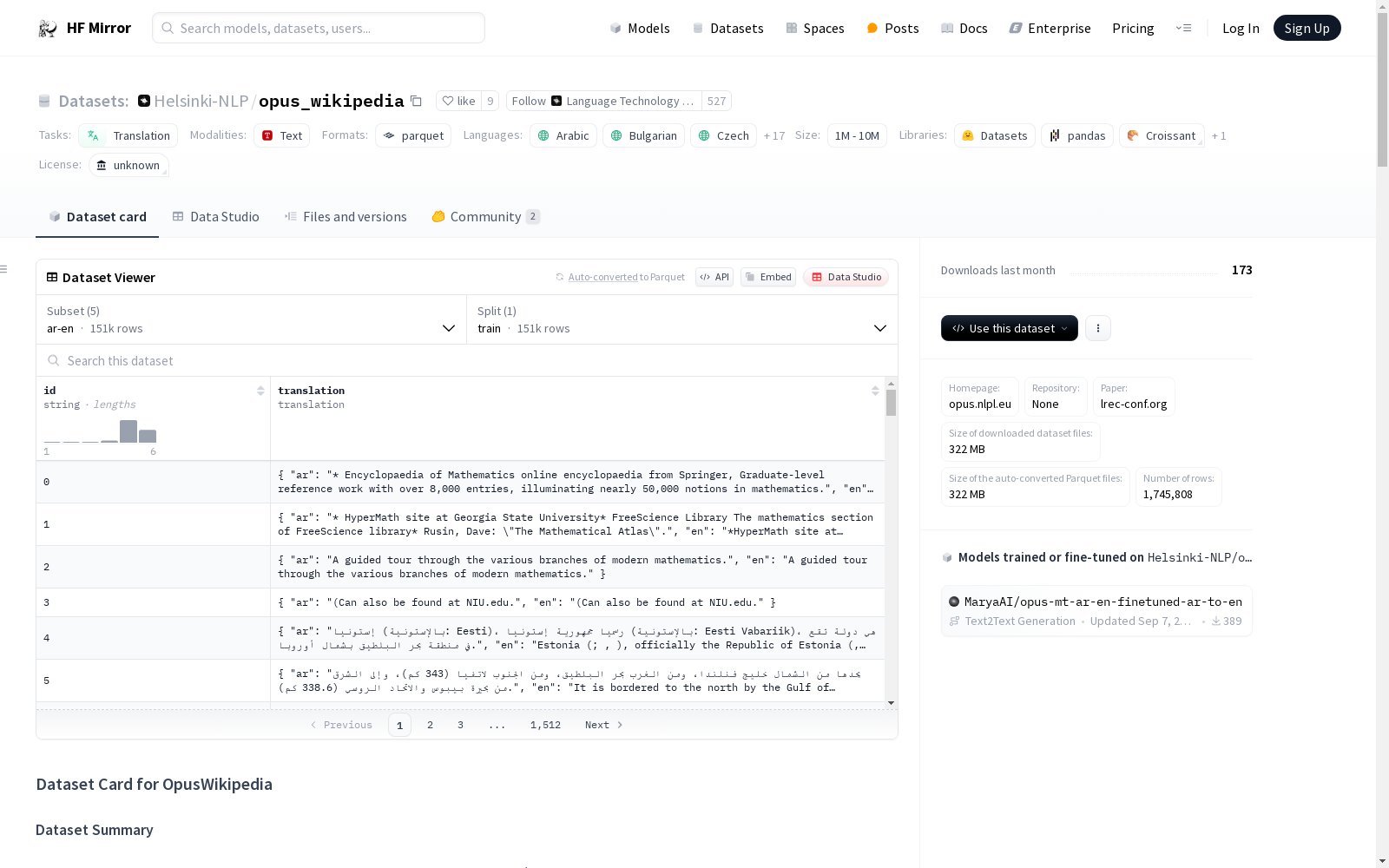
构建方式
该数据集的构建采取了对维基百科文本的平行句对抽取方式,由Krzysztof Wołk和Krzysztof Marasek负责实施。数据集包含了20种语言和36个双向文本,其构建目的是为了支持机器翻译任务,尤其是平行句对的挖掘。构建过程中涉及了原始文本的收集、清洗、格式化等步骤,确保了数据的质量和可用性。
特点
OpusWikipedia数据集的特点在于其多语言性,涵盖了从阿拉伯语到越南语等多种语言,且每个语言对均包含平行翻译的句对。此外,数据集规模适中,便于研究者快速下载和使用。其数据质量较高,适用于机器翻译模型的训练和评估。
使用方法
使用该数据集时,用户可根据需要加载特定的语言对。若所需的语言对不在预设配置中,用户可以通过指定语言代码来加载。例如,加载意大利语到波兰语的语言对,仅需在代码中指定相应的语言代码。数据集提供了训练集分割,便于进行机器翻译模型的训练。用户可以通过Hugging Face的库来轻松加载和利用这些数据。
背景与挑战
背景概述
OpusWikipedia数据集是由Krzysztof Wołk和Krzysztof Marasek创建的一个平行句子语料库,其内容主要来源于维基百科。该数据集于2014年构建,包含了20种语言的36个双语文本。它的创建旨在为机器翻译研究提供支持,尤其是在平行句对的挖掘方面。该数据集的构建不仅丰富了多语言翻译资源的库存,而且对提升机器翻译质量和相关自然语言处理任务的研究具有重要的推动作用。
当前挑战
尽管OpusWikipedia数据集为翻译研究提供了丰富的资源,但它在构建过程中也面临着一些挑战。首先,数据集中包含的文本质量参差不齐,这可能会对机器翻译模型的训练效果产生影响。其次,由于数据集来源于公开的维基百科内容,因此可能包含个人隐私信息,需要在使用时进行脱敏处理。此外,数据集的多语言对齐质量也是一大挑战,需要确保翻译对之间的对齐准确性。
常用场景
经典使用场景
在自然语言处理领域,Helsinki-NLP/opus_wikipedia数据集的典型应用场景是作为机器翻译任务的训练数据。该数据集提供了多种语言之间的平行语料,为构建和优化翻译模型提供了丰富的语言对照实例,从而提升翻译的准确性和流畅性。
解决学术问题
该数据集有效解决了学术研究中机器翻译质量评估和模型训练的数据缺乏问题。通过提供大规模的平行语料,研究者能够训练出更精确的翻译模型,同时也能够利用这些数据进行翻译质量的分析和评估,推动了翻译技术的发展。
衍生相关工作
基于该数据集,学术界衍生出了一系列相关研究工作,包括但不限于跨语言信息检索、机器翻译模型性能比较研究以及多语言自然语言处理任务的基准测试等,进一步推动了自然语言处理领域的研究进展。
以上内容由遇见数据集搜集并总结生成


