google-research-datasets/nq_open
收藏Hugging Face2024-03-22 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/google-research-datasets/nq_open
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- expert-generated
language_creators:
- other
language:
- en
license:
- cc-by-sa-3.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|natural_questions
task_categories:
- question-answering
task_ids:
- open-domain-qa
pretty_name: NQ-Open
dataset_info:
config_name: nq_open
features:
- name: question
dtype: string
- name: answer
sequence: string
splits:
- name: train
num_bytes: 6651236
num_examples: 87925
- name: validation
num_bytes: 313829
num_examples: 3610
download_size: 4678245
dataset_size: 6965065
configs:
- config_name: nq_open
data_files:
- split: train
path: nq_open/train-*
- split: validation
path: nq_open/validation-*
default: true
---
# Dataset Card for nq_open
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://efficientqa.github.io/
- **Repository:** https://github.com/google-research-datasets/natural-questions/tree/master/nq_open
- **Paper:** https://www.aclweb.org/anthology/P19-1612.pdf
- **Leaderboard:** https://ai.google.com/research/NaturalQuestions/efficientqa
- **Point of Contact:** [Mailing List](efficientqa@googlegroups.com)
### Dataset Summary
The NQ-Open task, introduced by Lee et.al. 2019,
is an open domain question answering benchmark that is derived from Natural Questions.
The goal is to predict an English answer string for an input English question.
All questions can be answered using the contents of English Wikipedia.
### Supported Tasks and Leaderboards
Open Domain Question-Answering,
EfficientQA Leaderboard: https://ai.google.com/research/NaturalQuestions/efficientqa
### Languages
English (`en`)
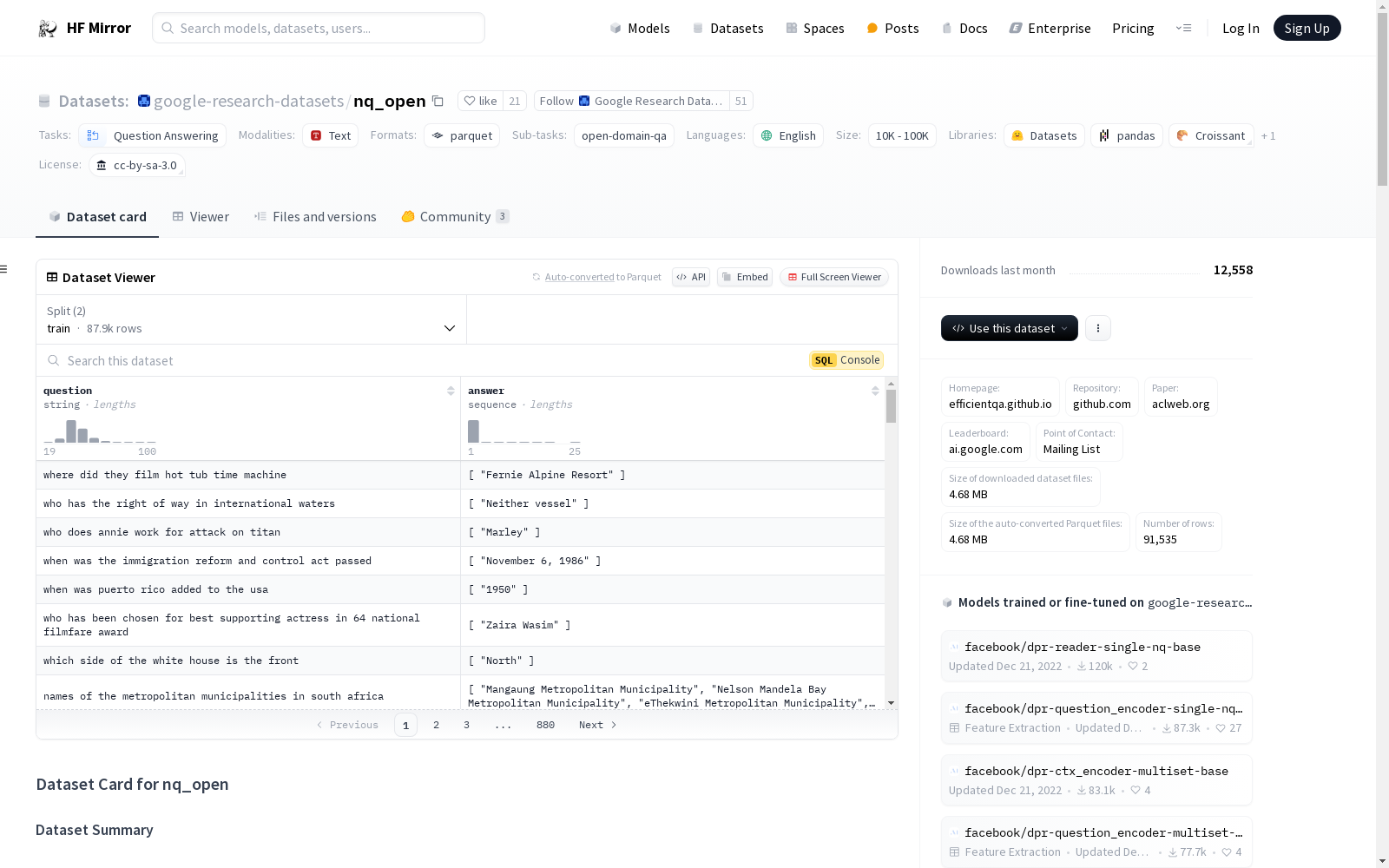
## Dataset Structure
### Data Instances
```
{
"question": "names of the metropolitan municipalities in south africa",
"answer": [
"Mangaung Metropolitan Municipality",
"Nelson Mandela Bay Metropolitan Municipality",
"eThekwini Metropolitan Municipality",
"City of Tshwane Metropolitan Municipality",
"City of Johannesburg Metropolitan Municipality",
"Buffalo City Metropolitan Municipality",
"City of Ekurhuleni Metropolitan Municipality"
]
}
```
### Data Fields
- `question` - Input open domain question.
- `answer` - List of possible answers to the question
### Data Splits
- Train : 87925
- validation : 3610
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
Natural Questions contains question from aggregated queries to Google Search (Kwiatkowski et al., 2019). To gather an open version of this dataset, we only keep questions with short answers and discard the given evidence document. Answers with many tokens often resemble extractive snippets rather than canonical answers, so we discard answers with more than 5 tokens.
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
Evaluating on this diverse set of question-answer pairs is crucial, because all existing datasets have inherent biases that are problematic for open domain QA systems with learned retrieval.
In the Natural Questions dataset the question askers do not already know the answer. This accurately reflects a distribution of genuine information-seeking questions.
However, annotators must separately find correct answers, which requires assistance from automatic tools and can introduce a moderate bias towards results from the tool.
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
All of the Natural Questions data is released under the
[CC BY-SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/) license.
### Citation Information
```
@article{doi:10.1162/tacl\_a\_00276,
author = {Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav},
title = {Natural Questions: A Benchmark for Question Answering Research},
journal = {Transactions of the Association for Computational Linguistics},
volume = {7},
number = {},
pages = {453-466},
year = {2019},
doi = {10.1162/tacl\_a\_00276},
URL = {
https://doi.org/10.1162/tacl_a_00276
},
eprint = {
https://doi.org/10.1162/tacl_a_00276
},
abstract = { We present the Natural Questions corpus, a question answering data set. Questions consist of real anonymized, aggregated queries issued to the Google search engine. An annotator is presented with a question along with a Wikipedia page from the top 5 search results, and annotates a long answer (typically a paragraph) and a short answer (one or more entities) if present on the page, or marks null if no long/short answer is present. The public release consists of 307,373 training examples with single annotations; 7,830 examples with 5-way annotations for development data; and a further 7,842 examples with 5-way annotated sequestered as test data. We present experiments validating quality of the data. We also describe analysis of 25-way annotations on 302 examples, giving insights into human variability on the annotation task. We introduce robust metrics for the purposes of evaluating question answering systems; demonstrate high human upper bounds on these metrics; and establish baseline results using competitive methods drawn from related literature. }
}
@inproceedings{lee-etal-2019-latent,
title = "Latent Retrieval for Weakly Supervised Open Domain Question Answering",
author = "Lee, Kenton and
Chang, Ming-Wei and
Toutanova, Kristina",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1612",
doi = "10.18653/v1/P19-1612",
pages = "6086--6096",
abstract = "Recent work on open domain question answering (QA) assumes strong supervision of the supporting evidence and/or assumes a blackbox information retrieval (IR) system to retrieve evidence candidates. We argue that both are suboptimal, since gold evidence is not always available, and QA is fundamentally different from IR. We show for the first time that it is possible to jointly learn the retriever and reader from question-answer string pairs and without any IR system. In this setting, evidence retrieval from all of Wikipedia is treated as a latent variable. Since this is impractical to learn from scratch, we pre-train the retriever with an Inverse Cloze Task. We evaluate on open versions of five QA datasets. On datasets where the questioner already knows the answer, a traditional IR system such as BM25 is sufficient. On datasets where a user is genuinely seeking an answer, we show that learned retrieval is crucial, outperforming BM25 by up to 19 points in exact match.",
}
```
### Contributions
Thanks to [@Nilanshrajput](https://github.com/Nilanshrajput) for adding this dataset.
annotations_creators:
- 专家生成
language_creators:
- 其他
language:
- en
license:
- cc-by-sa-3.0
multilinguality:
- 单语言
size_categories:
- 10K<n<100K
source_datasets:
- 扩展版|自然问题(Natural Questions)
task_categories:
- 问答
task_ids:
- 开放域问答(open-domain QA)
pretty_name: NQ-Open
dataset_info:
config_name: nq_open
features:
- name: question
dtype: string
- name: answer
sequence: string
splits:
- name: train
num_bytes: 6651236
num_examples: 87925
- name: validation
num_bytes: 313829
num_examples: 3610
download_size: 4678245
dataset_size: 6965065
configs:
- config_name: nq_open
data_files:
- split: train
path: nq_open/train-*
- split: validation
path: nq_open/validation-*
default: true
# nq_open 数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集概述](#dataset-summary)
- [支持的任务与排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据样例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [数据集遴选依据](#curation-rationale)
- [源数据](#source-data)
- [注释](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [已知其他局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集管护者](#dataset-curators)
- [许可证信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献说明](#contributions)
## 数据集描述
- **主页:** https://efficientqa.github.io/
- **代码仓库:** https://github.com/google-research-datasets/natural-questions/tree/master/nq_open
- **相关论文:** https://www.aclweb.org/anthology/P19-1612.pdf
- **排行榜:** https://ai.google.com/research/NaturalQuestions/efficientqa
- **联系方式:** [邮件列表](efficientqa@googlegroups.com)
### 数据集概述
NQ-Open任务由Lee等人于2019年提出,是源自自然问题(Natural Questions)数据集的开放域问答基准测试任务。其目标为针对输入的英文问题预测对应的英文答案字符串,所有问题均可通过英文维基百科的内容得到解答。
### 支持的任务与排行榜
开放域问答;EfficientQA排行榜:https://ai.google.com/research/NaturalQuestions/efficientqa
### 语言
英语(`en`)
## 数据集结构
### 数据样例
{
"question": "names of the metropolitan municipalities in south africa",
"answer": [
"Mangaung Metropolitan Municipality",
"Nelson Mandela Bay Metropolitan Municipality",
"eThekwini Metropolitan Municipality",
"City of Tshwane Metropolitan Municipality",
"City of Johannesburg Metropolitan Municipality",
"Buffalo City Metropolitan Municipality",
"City of Ekurhuleni Metropolitan Municipality"
]
}
### 数据字段
- `question` - 输入的开放域问题
- `answer` - 该问题的可选答案列表
### 数据划分
- 训练集:87925条样本
- 验证集:3610条样本
## 数据集构建
### 数据集遴选依据
[需补充更多信息]
### 源数据
#### 初始数据收集与标准化
自然问题(Natural Questions)数据集包含源自谷歌搜索聚合查询的问题(Kwiatkowski等,2019)。为构建该数据集的开放域版本,我们仅保留带有简短答案的问题,并丢弃配套的证据文档。由于包含较多Token的答案往往更偏向抽取式片段而非标准规范答案,因此我们会移除Token数超过5的答案。
#### 源语言创作者是谁?
[需补充更多信息]
### 注释
#### 注释流程
[需补充更多信息]
#### 注释人员是谁?
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据集使用注意事项
### 数据集的社会影响
[需补充更多信息]
### 偏差讨论
在该多样化的问答样本集上进行评估至关重要,因为现有所有数据集均存在固有偏差,这对带有学习型检索模块的开放域问答(QA)系统而言存在隐患。在自然问题(Natural Questions)数据集中,提问者本身并不知晓答案,这精准贴合了真实信息检索类问题的分布特征。然而,注释人员需独立寻找正确答案,这一过程需要借助自动工具,因此可能会引入一定程度上偏向工具输出结果的偏差。
### 已知其他局限性
[需补充更多信息]
## 附加信息
### 数据集管护者
[需补充更多信息]
### 许可证信息
所有自然问题(Natural Questions)数据集均采用[CC BY-SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/)许可证发布。
### 引用信息
@article{doi:10.1162/tacl\_a\_00276,
author = {Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav},
title = {Natural Questions: A Benchmark for Question Answering Research},
journal = {Transactions of the Association for Computational Linguistics},
volume = {7},
number = {},
pages = {453-466},
year = {2019},
doi = {10.1162/tacl\_a\_00276},
URL = {
https://doi.org/10.1162/tacl_a_00276
},
eprint = {
https://doi.org/10.1162/tacl_a_00276
},
abstract = { We present the Natural Questions corpus, a question answering data set. Questions consist of real anonymized, aggregated queries issued to the Google search engine. An annotator is presented with a question along with a Wikipedia page from the top 5 search results, and annotates a long answer (typically a paragraph) and a short answer (one or more entities) if present on the page, or marks null if no long/short answer is present. The public release consists of 307,373 training examples with single annotations; 7,830 examples with 5-way annotations for development data; and a further 7,842 examples with 5-way annotated sequestered as test data. We present experiments validating quality of the data. We also describe analysis of 25-way annotations on 302 examples, giving insights into human variability on the annotation task. We introduce robust metrics for the purposes of evaluating question answering systems; demonstrate high human upper bounds on these metrics; and establish baseline results using competitive methods drawn from related literature. }
}
@inproceedings{lee-etal-2019-latent,
title = "Latent Retrieval for Weakly Supervised Open Domain Question Answering",
author = "Lee, Kenton and
Chang, Ming-Wei and
Toutanova, Kristina",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1612",
doi = "10.18653/v1/P19-1612",
pages = "6086--6096",
abstract = "Recent work on open domain question answering (QA) assumes strong supervision of the supporting evidence and/or assumes a blackbox information retrieval (IR) system to retrieve evidence candidates. We argue that both are suboptimal, since gold evidence is not always available, and QA is fundamentally different from IR. We show for the first time that it is possible to jointly learn the retriever and reader from question-answer string pairs and without any IR system. In this setting, evidence retrieval from all of Wikipedia is treated as a latent variable. Since this is impractical to learn from scratch, we pre-train the retriever with an Inverse Cloze Task. We evaluate on open versions of five QA datasets. On datasets where the questioner already knows the answer, a traditional IR system such as BM25 is sufficient. On datasets where a user is genuinely seeking an answer, we show that learned retrieval is crucial, outperforming BM25 by up to 19 points in exact match."
}
### 贡献说明
感谢[@Nilanshrajput](https://github.com/Nilanshrajput) 为本数据集添加支持。
提供机构:
google-research-datasets
原始信息汇总
数据集概述
基本信息
- 数据集名称: NQ-Open
- 语言: 英语 (
en) - 许可证: CC BY-SA 3.0
- 多语言性: 单语种
- 数据集大小: 10K<n<100K
- 源数据集: 扩展自 Natural Questions
任务类型
- 任务类别: 问答系统
- 任务ID: 开放领域问答
数据集结构
- 配置名称: nq_open
- 特征:
question: 问题,数据类型为字符串answer: 答案,数据类型为字符串序列
- 数据分割:
- 训练集: 87925个样本,6651236字节
- 验证集: 3610个样本,313829字节
- 下载大小: 4678245字节
- 数据集大小: 6965065字节
数据文件
- 配置名称: nq_open
- 数据文件:
- 训练集:
nq_open/train-* - 验证集:
nq_open/validation-*
- 训练集:
数据实例
json { "question": "names of the metropolitan municipalities in south africa", "answer": [ "Mangaung Metropolitan Municipality", "Nelson Mandela Bay Metropolitan Municipality", "eThekwini Metropolitan Municipality", "City of Tshwane Metropolitan Municipality", "City of Johannesburg Metropolitan Municipality", "Buffalo City Metropolitan Municipality", "City of Ekurhuleni Metropolitan Municipality" ] }
数据字段
question: 输入的开放领域问题answer: 问题的可能答案列表
数据分割
- 训练集: 87925个样本
- 验证集: 3610个样本
搜集汇总
数据集介绍
构建方式
NQ-Open数据集源自Natural Questions数据集,经过精心筛选与处理,专注于开放域问答任务。构建过程中,仅保留了具有简短答案的问题,并剔除了原始数据中的证据文档。为确保答案的简洁性与规范性,答案长度超过五个词的条目被舍弃。这一过程旨在提供一个高质量的开放域问答基准,适用于评估问答系统的性能。
特点
NQ-Open数据集的核心特点在于其开放域问答的定位,所有问题均可通过英文维基百科的内容进行解答。数据集包含87925条训练样本和3610条验证样本,结构简洁,包含问题与答案两个主要字段。此外,数据集采用CC BY-SA 3.0许可,确保了其广泛的应用与共享。
使用方法
NQ-Open数据集适用于开放域问答任务的研究与开发,尤其适合用于训练和评估问答模型。用户可通过加载数据集中的问题与答案字段,构建和优化问答系统。数据集的简洁结构和大规模样本使其成为研究和实践的理想选择,尤其在需要处理开放域问题的场景中。
背景与挑战
背景概述
NQ-Open数据集由Lee等人于2019年引入,作为开放域问答(Open Domain Question Answering, QA)的基准测试,源自Natural Questions数据集。该数据集的核心研究问题是通过输入的英文问题预测相应的英文答案,所有问题均可通过英文维基百科的内容进行回答。NQ-Open的创建旨在推动开放域问答系统的发展,特别是在处理真实信息需求问题时,提供了一个高质量的基准。该数据集的发布对问答系统研究领域产生了深远影响,尤其是在评估系统在多样性问题上的表现方面。
当前挑战
NQ-Open数据集在构建过程中面临多项挑战。首先,数据集的来源是Google搜索的聚合查询,这要求对原始数据进行筛选和规范化,以确保问题和答案的质量。其次,由于开放域问答系统的复杂性,如何有效处理和消除数据中的偏见成为一个重要问题。此外,尽管数据集提供了高质量的训练和验证样本,但在实际应用中,系统仍需应对用户提问的多样性和复杂性,这对模型的泛化能力提出了更高要求。
常用场景
经典使用场景
NQ-Open数据集在开放域问答(Open Domain Question-Answering, ODQA)领域中具有经典应用场景。该数据集通过提供大量的英文问题及其对应的简短答案,为研究者构建和评估开放域问答系统提供了丰富的资源。研究者可以利用该数据集训练模型,使其能够从英文维基百科中自动检索并生成准确的答案,从而解决用户在信息检索过程中遇到的实际问题。
解决学术问题
NQ-Open数据集解决了开放域问答系统中常见的学术研究问题,特别是在处理用户真实信息需求时的答案生成与检索问题。通过提供高质量的问答对,该数据集帮助研究者克服了传统信息检索系统(如BM25)在处理复杂问题时的局限性,推动了基于学习的检索方法的发展。其意义在于为开放域问答系统提供了更为真实和多样化的评估基准,促进了该领域的技术进步。
衍生相关工作
NQ-Open数据集的发布催生了一系列相关研究工作,特别是在开放域问答系统的检索与阅读理解方面。例如,Lee等人提出的“Latent Retrieval for Weakly Supervised Open Domain Question Answering”方法,通过联合学习检索器和阅读器,显著提升了开放域问答系统的性能。此外,该数据集还为其他研究者提供了基准,推动了更多基于学习的检索方法和多任务学习模型的开发与应用。
以上内容由遇见数据集搜集并总结生成


