quickb-kb
收藏Hugging Face2025-04-25 更新2025-04-26 收录
下载链接:
https://huggingface.co/datasets/Nuf-hugginface/quickb-kb
下载链接
链接失效反馈官方服务:
资源简介:
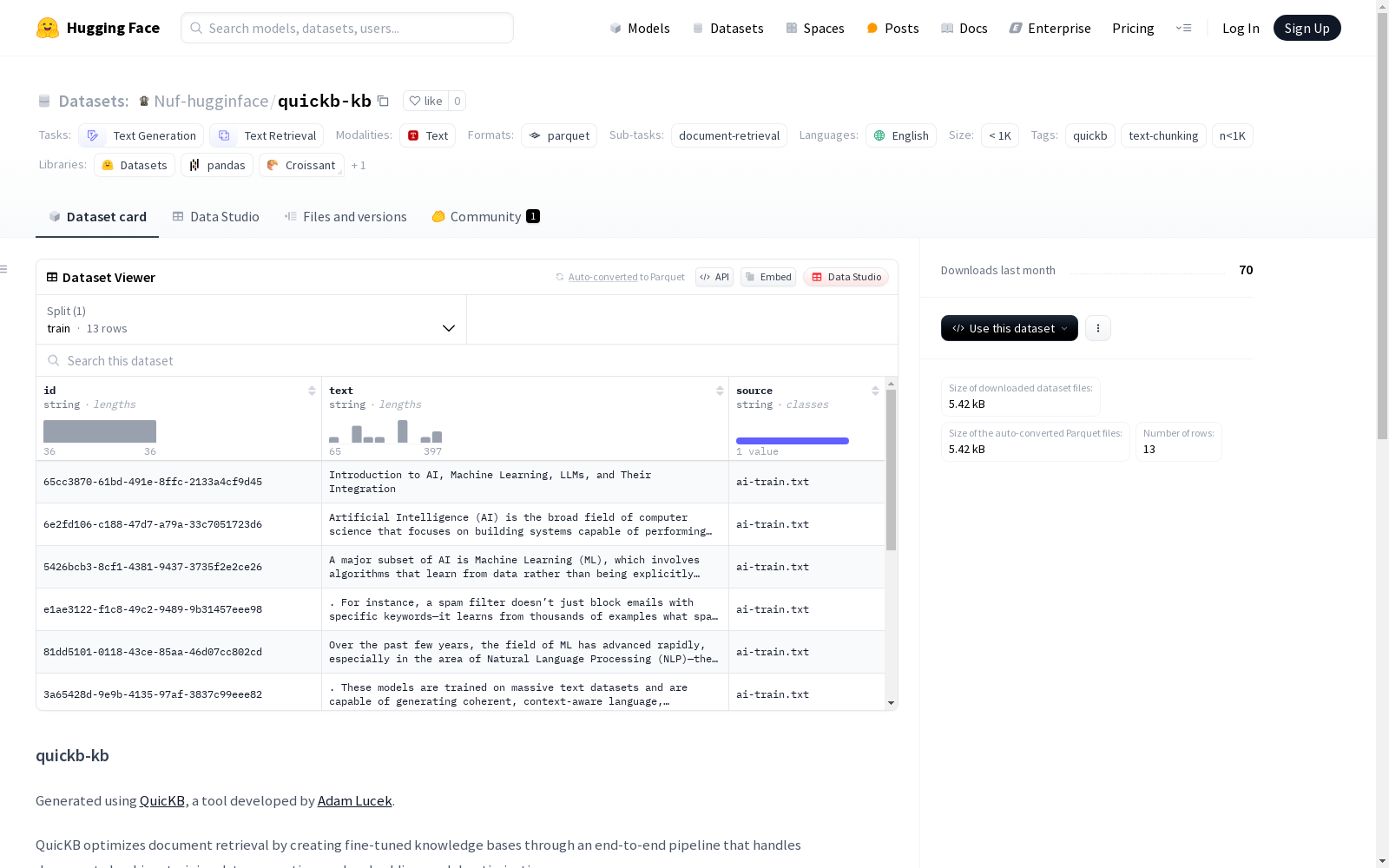
quickb-kb数据集是通过QuicKB工具生成的,该工具通过端到端的管道处理文档分块、训练数据生成和嵌入模型优化,以优化文档检索。数据集包含13个文本块,平均每个块包含34.8个单词。数据集结构包括文本块内容、源文件路径和每个块的唯一标识符。
创建时间:
2025-04-24
搜集汇总
数据集介绍
构建方式
quickb-kb数据集采用QuicKB工具构建,该工具由Adam Lucek开发,专注于优化文档检索流程。通过端到端的处理管道,实现了文档分块、训练数据生成以及嵌入模型优化的全流程自动化。具体分块配置采用递归令牌分块器(RecursiveTokenChunker),设置分块大小为400字符,无重叠区域,并依据多种分隔符进行智能切分,确保文本语义的连贯性。数据源经过精细处理,最终生成13个文本块,平均每块包含34.8个单词,体现了高效的信息压缩能力。
特点
该数据集以轻量级知识库为核心特色,专为文本检索与生成任务设计。其文本块结构清晰,每个条目包含原始内容、来源文件路径及唯一标识符,便于追踪数据溯源。分块策略通过多级分隔符(如段落、句子及空格)实现语义单元的自然划分,同时保留分隔符以维持文本原始结构。数据集规模虽小(<1K),但经过优化嵌入模型处理,能有效支撑小样本学习场景,为研究高效检索算法提供了理想实验素材。
使用方法
使用quickb-kb时,可通过HuggingFace库直接加载,适用于文本检索与生成模型的微调或评估。数据集的text字段可直接作为检索系统的输入,结合source字段实现跨文档关联分析,id字段则支持精确的样本定位。研究者可利用其分块特性探索段落级语义表示,或将其作为基准测试集验证检索模型的零样本性能。对于嵌入模型训练,建议结合QuicKB工具链进行端到端优化,以充分发挥该知识库的细粒度信息检索优势。
背景与挑战
背景概述
quickb-kb数据集诞生于文档检索技术快速发展的时代背景下,由研究者Adam Lucek基于其开发的QuicKB工具构建而成。该工具通过端到端的流程优化知识库构建,涵盖文档分块、训练数据生成和嵌入模型优化等关键环节。数据集采用递归令牌分块技术,以400字符为分块单位,旨在为文本生成和检索任务提供精细化的知识单元。作为轻量级知识库的代表,其13个文本块的结构体现了对小规模但高质量数据的追求,反映了当前信息检索领域对精确性和效率的双重要求。
当前挑战
在领域问题层面,quickb-kb需解决文档检索中语义粒度与检索效率的平衡难题,如何确保400字符的分块既能保持上下文完整性又避免信息冗余成为核心挑战。构建过程中面临分块策略的优化困境,包括分隔符选择对语义连贯性的影响、零重叠分块导致的上下文断裂风险。小规模数据特性虽提升处理效率,但要求分块算法具备更强的语义捕捉能力,以弥补数据量不足的局限。递归分块机制虽能适应多样文本结构,但对技术标点及复杂格式的敏感度仍需持续优化。
常用场景
经典使用场景
在自然语言处理领域,quickb-kb数据集以其优化的文本分块技术,为文档检索任务提供了高效的数据支持。该数据集通过递归令牌分块器(RecursiveTokenChunker)将文档分割为语义连贯的文本块,每个块大小固定为400字符,且无重叠,确保了检索的精确性和效率。这种分块方式特别适合处理大规模文本数据,如学术论文、技术文档等,使得后续的文本生成和检索任务能够基于更细粒度的语义单元进行。
实际应用
在实际应用中,quickb-kb数据集可广泛应用于智能问答系统、知识库构建以及个性化推荐系统。例如,企业可以利用该数据集优化内部文档检索流程,快速定位关键信息;教育机构则可通过其分块技术构建高效的学术资源检索平台。其轻量化的设计(总块数仅13个)也使其成为小规模原型开发的理想选择。
衍生相关工作
基于quickb-kb数据集,研究者们开发了多种文档检索和文本生成的衍生工作。例如,Adam Lucek的QuicKB工具进一步扩展了该数据集的应用范围,支持更复杂的嵌入模型优化。此外,一些研究聚焦于分块策略的改进,提出了动态分块和语义分块的新方法,这些工作均以quickb-kb为基准数据集进行验证。
以上内容由遇见数据集搜集并总结生成


