DGT-GL
收藏Hugging Face2025-12-19 更新2025-12-20 收录
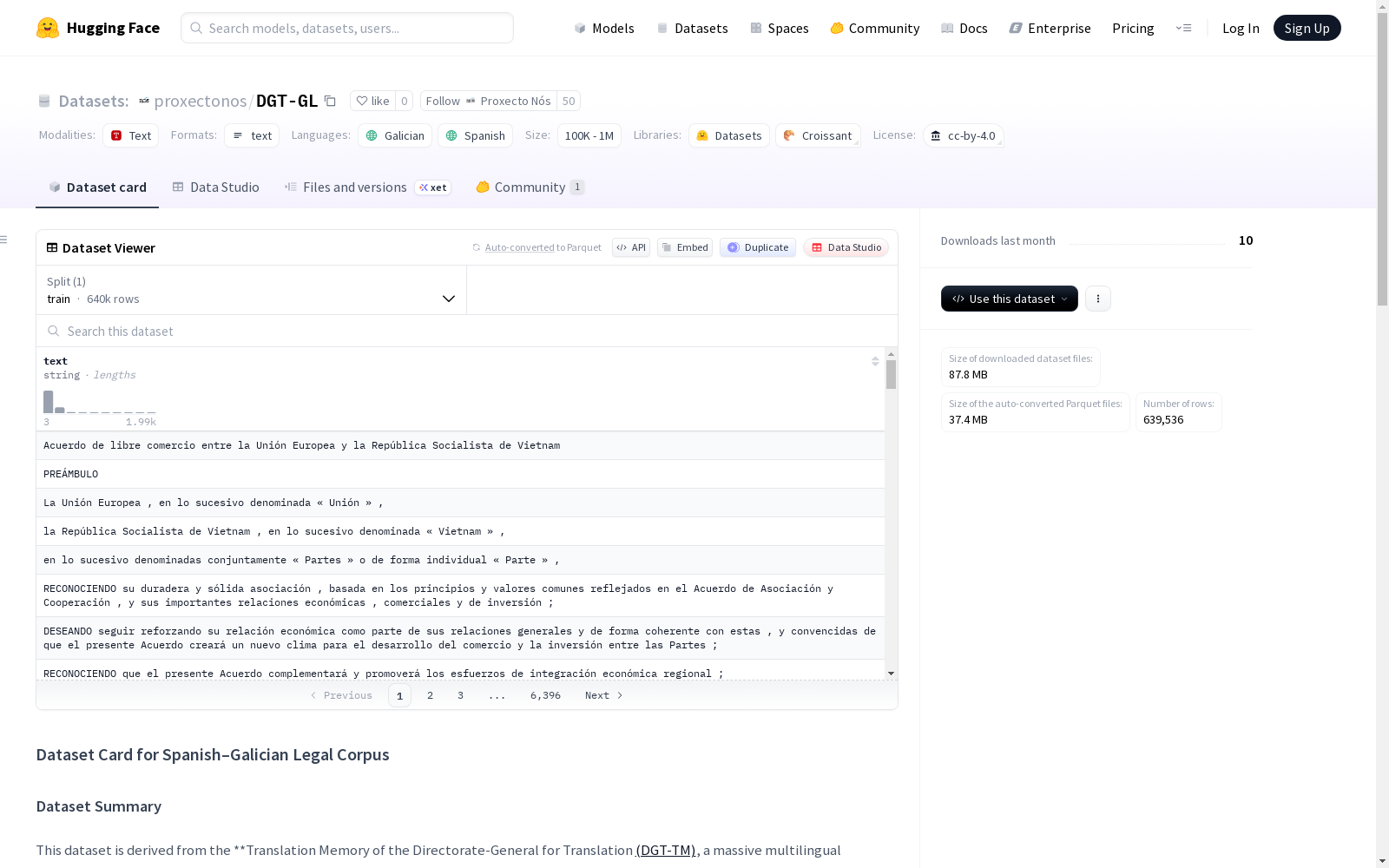
下载链接:
https://huggingface.co/datasets/proxectonos/DGT-GL
下载链接
链接失效反馈官方服务:
资源简介:
该数据集源自欧洲委员会的DGT-TM翻译记忆库,通过自动转译和翻译技术将葡萄牙语转换为加利西亚语,形成一个西班牙语-加利西亚语的平行语料库,专注于法律文本。数据集包含约32万条对齐的句子对,经过转译、本地化、编码错误检查、去重、过滤和标准化等处理步骤以确保语料质量。支持机器翻译、双语词典归纳、评估和跨语言NLP等任务。
创建时间:
2025-12-15
原始信息汇总
数据集卡片:西班牙语-加利西亚语法律语料库
数据集摘要
本数据集源自欧盟委员会创建的翻译总局翻译记忆库(DGT-TM)。原始语料库包含以24种官方语言对齐的《欧盟法律(Acquis Communautaire)》。 结果是一个专注于法律文本的西班牙语-加利西亚语平行语料库,包含约32万个对齐的句子对。 虽然加利西亚语未包含在原始版本中,但葡萄牙语包含在内。利用自动音译和翻译技术,葡萄牙语片段被改编为加利西亚语。此改编利用了文本处理流程和Apertium中的音译和本地化工具。生成的文本随后被规范化,确保了语言一致性并已准备好用于模型开发。
数据集创建
- Apertium pt-gl:使用符号规则将原始葡萄牙语片段翻译成加利西亚语。
- 音译和本地化:使用port2gal,通过处理所有剩余标签(针对词汇表外单词)来改进Apertium的输出,这些单词要么被音译为西班牙语正字法,要么被本地化为更常见的加利西亚语单词。
- 编码错误:扫描整个文本以查找编码错误,确保其为utf-8编码。
- 去重:对过滤后的数据集进行去重,以移除冗余的句子对。
- Pyplexity:使用pyplexity过滤可能包含非语言内容的文本。
- 规范化:此处呈现的最终加利西亚语文本经过(语言学)规范化,以符合加利西亚语的自治标准。
支持的任务与基准
- 机器翻译(MT):训练和评估西班牙语 ↔ 加利西亚语的机器翻译系统。
- 双语词典归纳:为资源稀缺语言对构建词典和术语表。
- 评估:在法律领域语料库中对翻译质量进行基准测试。
- 跨语言自然语言处理:支持多语言嵌入和语义对齐等任务。
语言
- 西班牙语-加利西亚语
数据集结构
- 格式:平行文本片段(对齐的句子)
- 领域:法律文本(欧盟立法)
- 大小:约32万行
使用案例
- 为资源稀缺语言加利西亚语训练机器翻译模型。
- 创建双语词典和术语表。
- 在专业法律领域评估翻译系统。
- 支持跨语言迁移和代表性不足语言的研究。
局限性
- 领域特定:主要是法律文本,可能无法推广到日常语言。
- 自动改编的加利西亚语片段可能包含音译或翻译伪影。
资金来源
本工作由数字化和公共职能部资助,资金来自欧盟 – NextGenerationEU,属于“Desarrollo de Modelos ALIA”项目框架内。该“Desarrollo de Modelos ALIA”项目的发布由数字化和公共职能部以及复苏、转型和韧性计划资助 – 资金来自欧盟 – NextGenerationEU。
搜集汇总
数据集介绍
构建方式
在欧盟法律文本的多语言对齐背景下,DGT-GL数据集通过创新的跨语言转换策略构建而成。其基础源自欧盟委员会发布的DGT翻译记忆库,该库涵盖了24种官方语言的立法文本。针对加利西亚语未包含于原始资源的情况,研究团队首先利用葡萄牙语与加利西亚语的亲缘性,采用Apertium符号化规则进行初步翻译转换。随后通过port2gal工具进行深度本地化处理,对未登录词实施音译转写或词汇替换,以贴近加利西亚语常用表达。所有文本经过编码校验、去重过滤及非语言内容清洗后,最终按照加利西亚语自治标准进行语言学规范化,形成约32万句对的高质量法律领域平行语料。
特点
该数据集最显著的特征在于其专业领域聚焦性,全部语料均来自欧盟法律体系,为法律机器翻译研究提供了珍贵资源。作为低资源语言对的代表,西班牙语-加利西亚语的平行文本规模达到32万句对,在同类资源中具有突出优势。语料构建过程中融合了规则翻译与统计本地化技术,既保持法律文本的术语一致性,又兼顾加利西亚语的语言规范。数据集经过多重质量控制流程,包括编码标准化、文本去重和语言学过滤,确保语料清洁度与可用性。这种专业领域与语言技术深度结合的特色,使其成为研究法律文本跨语言转换的理想实验平台。
使用方法
在机器翻译系统开发领域,该数据集可直接用于训练西班牙语与加利西亚语之间的双向翻译模型。研究者可采用标准神经机器翻译架构,将平行句对划分为训练集、验证集和测试集,评估模型在法律文本上的翻译性能。对于双语词典构建任务,可通过对齐句对提取高频术语对应关系,建立领域专用词汇映射表。在跨语言自然语言处理研究中,该语料可用于训练双语词向量或跨语言预训练模型,探究语言间的语义对齐规律。使用时应充分考虑其法律文本领域的特殊性,建议与其他通用领域语料结合使用以提升系统泛化能力,同时注意自动转换可能存在的语言偏差问题。
背景与挑战
背景概述
在计算语言学和机器翻译领域,低资源语言对的平行语料库构建一直是推动语言技术民主化的核心议题。DGT-GL数据集由西班牙加利亚自治区的研究团队于近年创建,其基础源自欧盟委员会翻译总司(DGT)的多语言翻译记忆库,该库收录了欧盟立法文件《共同体既有法律》(Acquis Communautaire)的24种官方语言对齐文本。研究团队通过自动音译与翻译技术,将库中的葡萄牙语文本适配为加利西亚语,最终形成一个包含约32万句对的西班牙语-加利西亚语法律领域平行语料库。这一工作不仅填补了加利西亚语在高质量法律文本资源上的空白,也为低资源语言的机器翻译模型训练与评估提供了关键数据支撑,对促进区域性语言在数字环境中的保存与发展具有显著影响力。
当前挑战
DGT-GL数据集旨在解决法律领域低资源语言对的机器翻译挑战,其核心难题在于如何在缺乏原生平行语料的情况下,通过跨语言适配技术生成高质量、领域专用的对齐文本。构建过程中面临多重挑战:首先,加利西亚语未包含于原始DGT语料库,需借助葡萄牙语作为中介语言进行转换,这一过程涉及复杂的符号规则翻译与音译处理,易引入词汇歧义或语法偏差;其次,法律文本具有高度的术语专业性和句式规范性,自动转换可能产生语义失真或风格不一致的片段;此外,数据清洗环节需有效剔除编码错误、重复条目及非语言内容,确保语料的纯净性与语言学规范性,这对后续模型训练的可靠性构成严峻考验。
常用场景
经典使用场景
在机器翻译领域,DGT-GL数据集为西班牙语与加利西亚语之间的法律文本翻译提供了关键资源。该数据集源自欧盟委员会的翻译记忆库,专注于法律领域,包含约32万句对齐的平行语料。其经典使用场景在于训练和评估针对低资源语言对的机器翻译系统,特别是在法律这一专业领域内,为模型开发提供了高质量的基准数据。通过自动转换和语言规范化处理,该数据集确保了语料的一致性与可用性,支持研究人员构建高效的翻译模型。
解决学术问题
DGT-GL数据集有效解决了低资源语言对在机器翻译研究中的语料匮乏问题。加利西亚语作为一种资源相对有限的语言,长期以来缺乏大规模、高质量的专业领域平行文本。该数据集通过将葡萄牙语语料自动适配为加利西亚语,并结合语言规范化技术,为学术研究提供了可靠的法律文本资源。这不仅促进了低资源语言机器翻译技术的发展,还为跨语言自然语言处理任务,如双语词典归纳和语义对齐,奠定了数据基础,推动了语言技术领域的均衡进步。
衍生相关工作
围绕DGT-GL数据集,衍生了一系列经典研究工作,主要集中在低资源语言机器翻译和跨语言自然语言处理领域。例如,研究人员利用该数据集训练了专门的西班牙语-加利西亚语神经机器翻译模型,并在法律文本翻译任务中评估其性能。此外,该数据集还被用于开发双语词嵌入模型和语义对齐工具,支持如文本分类、信息检索等下游任务。这些工作不仅提升了加利西亚语的语言技术水平,也为其他低资源语言提供了可借鉴的方法论和实验框架。
以上内容由遇见数据集搜集并总结生成


