LightOnOCR-bbox-mix-0126
收藏Hugging Face2026-01-21 更新2026-01-22 收录
下载链接:
https://huggingface.co/datasets/lightonai/LightOnOCR-bbox-mix-0126
下载链接
链接失效反馈官方服务:
资源简介:
LightOnOCR-bbox-mix-0126是一个大规模OCR训练数据集,包含布局信息。该数据集通过蒸馏方法构建,使用强大的视觉-语言模型生成自然顺序的全页转录(包含Markdown、LaTeX数学公式和HTML表格)。数据集设计用于训练端到端OCR/文档理解模型,输出干净、人类可读的文本。数据集包含PDFA文档的注释,但不包含源PDF文件。每行数据对应一个页面,包括自然阅读顺序的文本转录、结构标记(标题、列表、表格)和数学公式(LaTeX),以及轻量级元数据。数据集适用于训练OCR模型和研究OCR对科学标记的鲁棒性,但存在语言覆盖不均和模型生成错误等限制。
创建时间:
2026-01-16
原始信息汇总
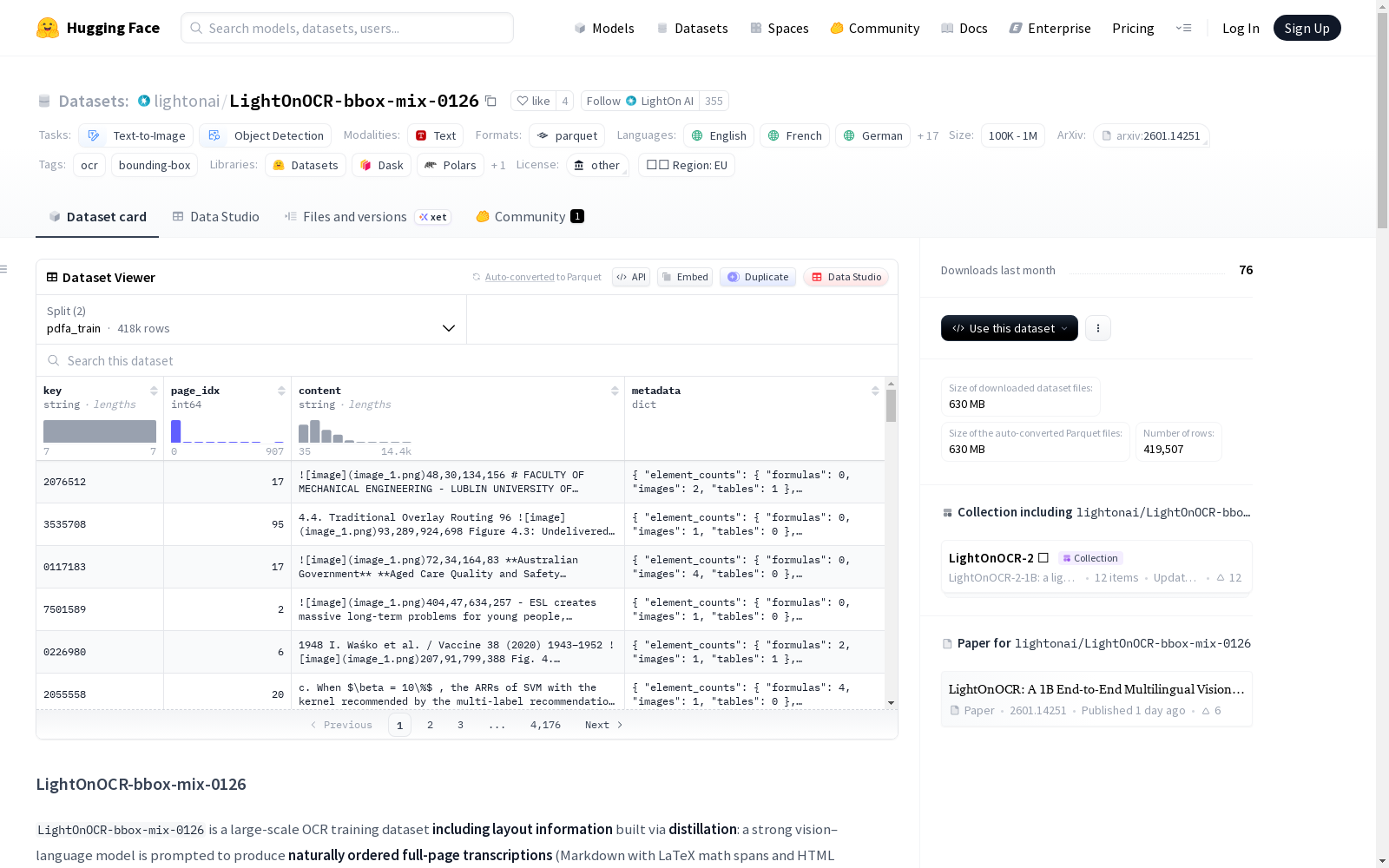
LightOnOCR-bbox-mix-0126 数据集概述
数据集基本信息
- 数据集名称:LightOnOCR-bbox-mix-0126
- 发布者:lightonai
- 许可证:other(具体使用受上游来源条款约束)
- 任务类别:文本到图像、目标检测
- 语言:英语、法语、德语、西班牙语、意大利语、日语、俄语、波兰语、荷兰语、中文、葡萄牙语、保加利亚语、土耳其语、乌尔都语、印地语、泰语、阿拉伯语、斯瓦希里语、希腊语、越南语
- 标签:OCR、边界框
- 规模类别:100K < n < 1M
数据集描述
LightOnOCR-bbox-mix-0126 是一个大规模OCR训练数据集,包含布局信息,通过蒸馏方式构建:使用一个强大的视觉-语言模型从渲染的文档页面生成自然顺序的全页转录(包含LaTeX数学公式和HTML表格的Markdown文本)。该数据集旨在为端到端OCR/文档理解模型提供监督,这些模型旨在输出干净、人类可读且格式一致的文本。
此存储库发布的是用于LightOnOCR-2-1B训练混合的PDFA衍生注释子集。不分发源PDF文件;仅提供文本目标(及相关元数据)。源文档可以从pixparse/pdfa-eng-wds恢复。
数据内容
每个数据行对应单个页面,包含:
- 自然阅读顺序的文本转录
- 结构(标题、列表、表格)和数学公式(数学公式块内的LaTeX)的标记
- 由标准化/验证流程生成的轻量级元数据
数据格式与特征
数据集包含以下特征:
key:源PDF的唯一标识符page_idx:用于转录的PDF文档的源页码content:标准化转录目标(包含LaTeX数学公式块和HTML表格的Markdown文本)metadata:元数据结构element_counts:元素计数结构formulas:转录中LaTeX分隔的公式数量images:转录中图像占位符数量tables:转录中HTML表格数量
token_length:转录的令牌长度(使用LightOnOCR-2-1B-0126分词器模型)
数据划分与规模
- 划分:
pdfa_train:训练集,包含417,507个样本,大小约1,108,203,340字节pdfa_validation:验证集,包含2,000个样本,大小约5,304,577字节
- 总数据集大小:约1,113,507,917字节
- 下载大小:约630,049,538字节
生成与处理
- 教师模型:使用最先进的视觉-语言模型教师生成注释(详见LightOnOCR-2论文)。
- 目标格式:Markdown格式,包含:
- 限制在数学公式块内的LaTeX数学公式
- 相关时包含边界框信息坐标的标准化图像占位符
- 以无样式的最小化HTML格式表示的表格
- 标准化与清理:应用统一的标准化流程,包括:
- 文本清理:移除虚假的Markdown代码围栏/标记;统一空格。
- 去重/过滤:计算标准化文本的哈希值并过滤常见故障模式(如循环式重复)。
- LaTeX验证:强制格式不变量(LaTeX限制在数学公式块内)并可选检查KaTeX兼容性。
- 边界框:蒸馏过程中,教师模型偶尔会发出图形边界框坐标。这些坐标从主要的OCR目标中移除,但保留为图像定位的单独监督信号。
预期用途
- 训练/微调输出自然阅读顺序文本的端到端OCR视觉-语言模型
- 研究OCR对科学标记(数学公式、参考文献、结构化文本)的鲁棒性
- 基准测试格式稳定性/标准化技术
不适用场景
- 重建或重新分发原始PDF文件
- 未经进一步验证的高风险应用
局限性
- 目标是模型生成的,可能包含偶尔的幻觉或格式错误,尤其是在极其复杂的布局上。
- 语言覆盖范围在欧洲语言内容上最强;在底层来源中代表性不足的文字上性能可能有所不同。
许可与使用条款
PDFA衍生部分(来自PDFA / SafeDocs / CC-MAIN-2021-31-PDF-UNTRUNCATED)
此数据集包含源自PDFA / SafeDocs语料库(CC-MAIN-2021-31-PDF-UNTRUNCATED)的PDF文档的衍生注释。该数据集的PDFA衍生部分根据上游条件提供:用户必须遵守Common Crawl的许可证和使用条款以及Digital Corpora项目的使用条款。
相关资源
- 论文:https://arxiv.org/pdf/2601.14251
- 模型:https://huggingface.co/lightonai/LightOnOCR-2-1B
- 源代码PDF:https://huggingface.co/datasets/pixparse/pdfa-eng-wdspixparse/pdfa-eng-wds
搜集汇总
数据集介绍
构建方式
在光学字符识别领域,构建高质量的训练数据是提升模型性能的关键。LightOnOCR-bbox-mix-0126数据集通过知识蒸馏技术构建,利用先进的视觉-语言模型作为教师模型,从渲染的文档页面中生成自然阅读顺序的完整页面转录。转录内容采用Markdown格式,并包含LaTeX数学公式和HTML表格的结构化标记。原始转录经过统一的规范化处理流程,包括文本清理、去重过滤以及LaTeX验证,以消除不一致性并确保格式统一,从而为端到端OCR模型提供稳定可靠的监督信号。
特点
该数据集在文档理解任务中展现出显著的多模态特性。其核心特点在于提供了包含布局信息的自然阅读顺序转录,覆盖了数学公式、图像和表格等多种文档元素。数据集支持包括英语、法语、德语、中文在内的多种语言,具有较强的跨语言适应性。此外,数据集附带了轻量级元数据,如元素计数和文本长度,便于进行数据分析和模型训练中的样本筛选。尽管数据集不包含原始PDF文件,但其转录目标旨在输出清晰、人类可读的标准化文本格式。
使用方法
该数据集主要应用于训练和微调端到端的光学字符识别视觉-语言模型,旨在输出符合自然阅读顺序的文本。研究人员可利用其研究OCR模型对科学标记(如数学公式、参考文献和结构化文本)的鲁棒性,或用于评估格式稳定性与规范化技术。在使用时,需通过HuggingFace平台加载数据集,并依据提供的元数据信息进行预处理和样本选择。用户应遵守上游数据源的使用条款,并注意该数据集不适用于原始PDF的重建或高风险应用场景。
背景与挑战
背景概述
LightOnOCR-bbox-mix-0126数据集由LightOnAI研究团队于2024年构建,旨在为端到端光学字符识别与文档理解模型提供大规模、高质量的监督数据。该数据集通过蒸馏技术生成,利用先进的视觉-语言模型从渲染的文档页面中提取自然阅读顺序的全文转录,并整合了布局信息,如数学公式的LaTeX表示和表格的HTML结构。其核心研究问题聚焦于提升OCR模型在处理复杂文档结构时的准确性与鲁棒性,特别是在科学文献等富含多模态元素的场景中。该数据集的发布显著推动了文档智能领域的发展,为后续模型如LightOnOCR-2-1B的训练提供了关键支持,并在多语言OCR任务中展现出广泛的应用潜力。
当前挑战
该数据集致力于解决文档智能领域中端到端OCR模型的训练挑战,即如何从包含复杂布局的文档中准确提取并结构化文本信息,同时保持数学公式、表格等元素的语义完整性。构建过程中的主要挑战包括:首先,蒸馏生成的目标文本可能存在幻觉或格式不一致,需通过归一化流水线进行清洗和验证;其次,多语言文档的覆盖范围不均衡,欧洲语言内容占主导,其他文字脚本的表现可能受限;此外,数据集中不包含原始PDF文件,仅提供文本标注,这限制了其在某些需要图像输入的研究中的应用。这些挑战要求研究者在模型训练与评估中采取额外的验证步骤,以确保数据的可靠性与泛化能力。
常用场景
经典使用场景
在文档智能领域,LightOnOCR-bbox-mix-0126数据集为端到端OCR模型的训练提供了关键支持。其核心应用场景在于训练视觉语言模型,以生成符合自然阅读顺序的文本转录,同时保留文档的布局结构信息,如数学公式的LaTeX表示和表格的HTML格式。通过蒸馏技术生成的标注数据,使得模型能够学习从渲染的文档页面中提取并规范化文本内容,特别适用于处理包含复杂科学标记的学术文献,从而提升OCR系统在多样化文档类型上的泛化能力。
衍生相关工作
基于LightOnOCR-bbox-mix-0126数据集,衍生出了多项经典研究工作,其中最突出的是LightOnOCR-2-1B模型的开发。该模型利用数据集的蒸馏标注进行训练,实现了端到端的文档转录与理解,并在OCR鲁棒性和格式稳定性方面取得显著改进。此外,数据集还促进了文档布局分析、数学表达式识别以及多模态语言模型的研究,为后续如pixparse/pdfa-eng-wds等数据集的构建提供了方法论参考,推动了整个文档智能领域的技术演进。
数据集最近研究
最新研究方向
在文档智能领域,光学字符识别技术正朝着端到端视觉语言模型的方向演进。LightOnOCR-bbox-mix-0126数据集凭借其大规模、多语言特性及布局标注信息,为前沿研究提供了关键支撑。当前研究热点集中于利用此类蒸馏生成的数据,训练能够输出自然阅读顺序文本的模型,尤其注重数学公式、表格等结构化内容的准确转录与格式化稳定性。该数据集推动了OCR模型在科学文档理解中的鲁棒性探索,同时其附带的边界框坐标信息为图像定位任务开辟了新的监督学习途径,显著提升了多模态文档分析的自动化水平。
以上内容由遇见数据集搜集并总结生成


