ccmatrix-en-ja
收藏Hugging Face2024-08-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Hoshikuzu/ccmatrix-en-ja
下载链接
链接失效反馈官方服务:
资源简介:
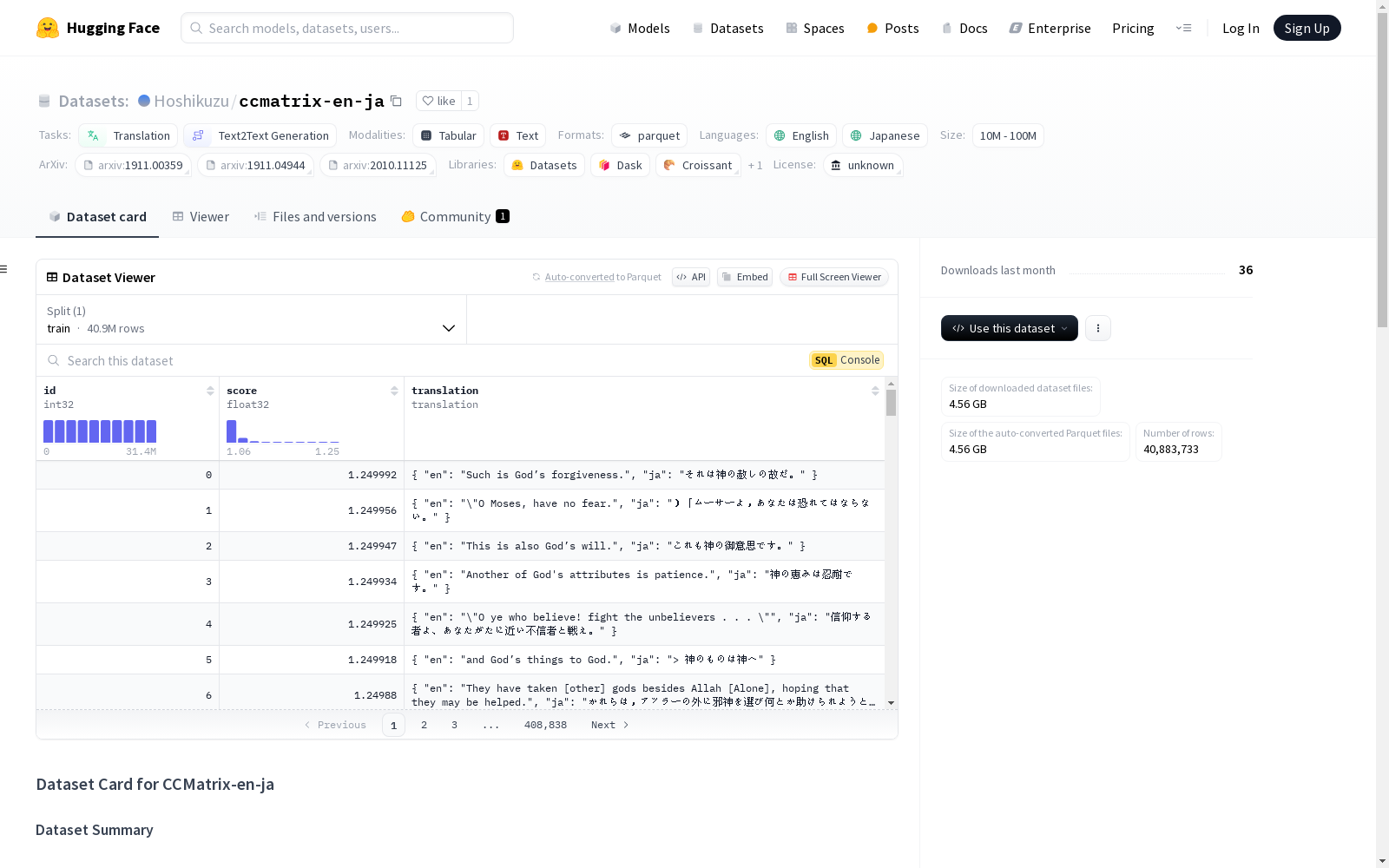
该语料库是从yhavinga/ccmatrix提取的日英对齐语料库。每个示例包含一个从0开始的整数id、一个分数和一个包含语言1和语言2文本的翻译字典。仅提供训练集分割。
创建时间:
2024-08-01
原始信息汇总
数据集卡片 for CCMatrix-en-ja
数据集概述
该语料库是从 yhavinga/ccmatrix 提取的,包含日语和英语对。
数据集结构
数据实例
例如: json { id: 0, score: 1.2499920129776, translation: { en: Such is God’s forgiveness., ja: それは神の赦しの故だ。 } }
数据字段
每个示例包含一个从0开始的整数id,一个分数,以及一个包含语言1和语言2文本的翻译字典。
数据分割
仅提供了一个 train 分割。
引用信息
请按照 yhavinga/ccmatrix 自述文件中描述的指示进行引用。以下内容摘自 yhavinga/ccmatrix:
重要提示:如果您使用此数据,请引用参考文献 [2][3]。
- CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data 作者:Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Jouli 和 Edouard Grave。
- CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB 作者:Holger Schwenk, Guillaume Wenzek, Sergey Edunov, Edouard Grave 和 Armand Joulin。
- Beyond English-Centric Multilingual Machine Translation 作者:Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, 和 Armand Joulin。
此 HuggingFace CCMatrix 数据集是围绕 OPUS 准备和托管的服务和文件的包装器:
- Parallel Data, Tools and Interfaces in OPUS 作者:Jörg Tiedemann。
搜集汇总
数据集介绍
构建方式
ccmatrix-en-ja数据集是从yhavinga/ccmatrix语料库中提取的,专注于英语和日语之间的平行句子对。该数据集的构建基于大规模网络爬取数据,通过先进的过滤和匹配技术,确保句子对的高质量和准确性。具体而言,数据来源于Common Crawl项目,经过预处理和语言对齐,最终生成了包含4088万条平行句对的训练集。
特点
ccmatrix-en-ja数据集的特点在于其规模庞大且质量高,涵盖了广泛的领域和语境。每条数据包含一个唯一的整数ID、一个表示句子对质量的分数,以及一个包含英语和日语翻译对的字典。数据集仅提供训练集,适用于机器翻译和文本生成任务。其语言对覆盖了英语和日语,为跨语言研究提供了丰富的资源。
使用方法
使用ccmatrix-en-ja数据集时,可通过Hugging Face的`datasets`库加载数据。用户只需调用`load_dataset`函数并指定数据集名称即可。若数据加载时间较长,可通过设置`streaming=True`启用流式加载功能。加载后的数据可直接用于训练机器翻译模型或进行其他自然语言处理任务。数据格式为JSON,每条记录包含ID、分数和翻译对,便于进一步处理和分析。
背景与挑战
背景概述
CCMatrix-en-ja数据集是基于CCMatrix项目的一个子集,专注于英语和日语之间的平行句对。该数据集由Facebook AI Research(FAIR)团队于2019年发布,旨在通过从互联网爬取的海量数据中提取高质量的平行语料,推动多语言机器翻译领域的研究。CCMatrix项目的主要研究人员包括Holger Schwenk、Guillaume Wenzek等,其核心研究问题是如何从非结构化的网络数据中自动挖掘并构建高质量的平行语料库。该数据集在多语言机器翻译、跨语言信息检索等领域具有重要影响力,为研究者提供了丰富的资源支持。
当前挑战
CCMatrix-en-ja数据集在解决多语言机器翻译问题时面临的主要挑战包括数据质量的不一致性和语言对的稀缺性。由于数据来源于互联网,其中可能包含噪声、错误翻译或不完整的句子,这对模型的训练和评估提出了更高的要求。此外,英语和日语之间的语言差异较大,包括语法结构、词汇表达和文化背景等方面,这增加了构建高质量平行语料库的难度。在数据集构建过程中,研究人员还需应对数据清洗、对齐和标注的复杂性,以确保最终数据的准确性和可用性。这些挑战不仅影响了数据集的构建效率,也对后续的模型性能提出了更高的要求。
常用场景
经典使用场景
在机器翻译领域,ccmatrix-en-ja数据集被广泛应用于训练和评估英语-日语双向翻译模型。其包含的大量高质量平行句子对为研究者提供了丰富的语料资源,尤其适用于神经机器翻译(NMT)模型的训练。通过该数据集,研究者能够构建更加精准和流畅的翻译系统,显著提升跨语言沟通的效率。
实际应用
在实际应用中,ccmatrix-en-ja数据集被广泛用于开发商业翻译工具、跨语言搜索引擎和多语言内容生成系统。例如,基于该数据集训练的翻译模型可以集成到在线翻译平台中,为用户提供实时、准确的英语-日语互译服务。此外,该数据集还被用于教育领域,支持语言学习工具的开发,帮助学生更高效地掌握双语能力。
衍生相关工作
ccmatrix-en-ja数据集衍生了许多经典研究工作,例如基于Transformer架构的神经机器翻译模型优化、低资源语言翻译增强技术以及多语言预训练模型的开发。相关研究如《CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB》和《Beyond English-Centric Multilingual Machine Translation》均以该数据集为基础,推动了机器翻译领域的理论创新和技术突破。
以上内容由遇见数据集搜集并总结生成


