EnglishDataBase
收藏github2021-12-01 更新2024-05-31 收录
下载链接:
https://github.com/Leezed525/EnglishDataBase
下载链接
链接失效反馈官方服务:
资源简介:
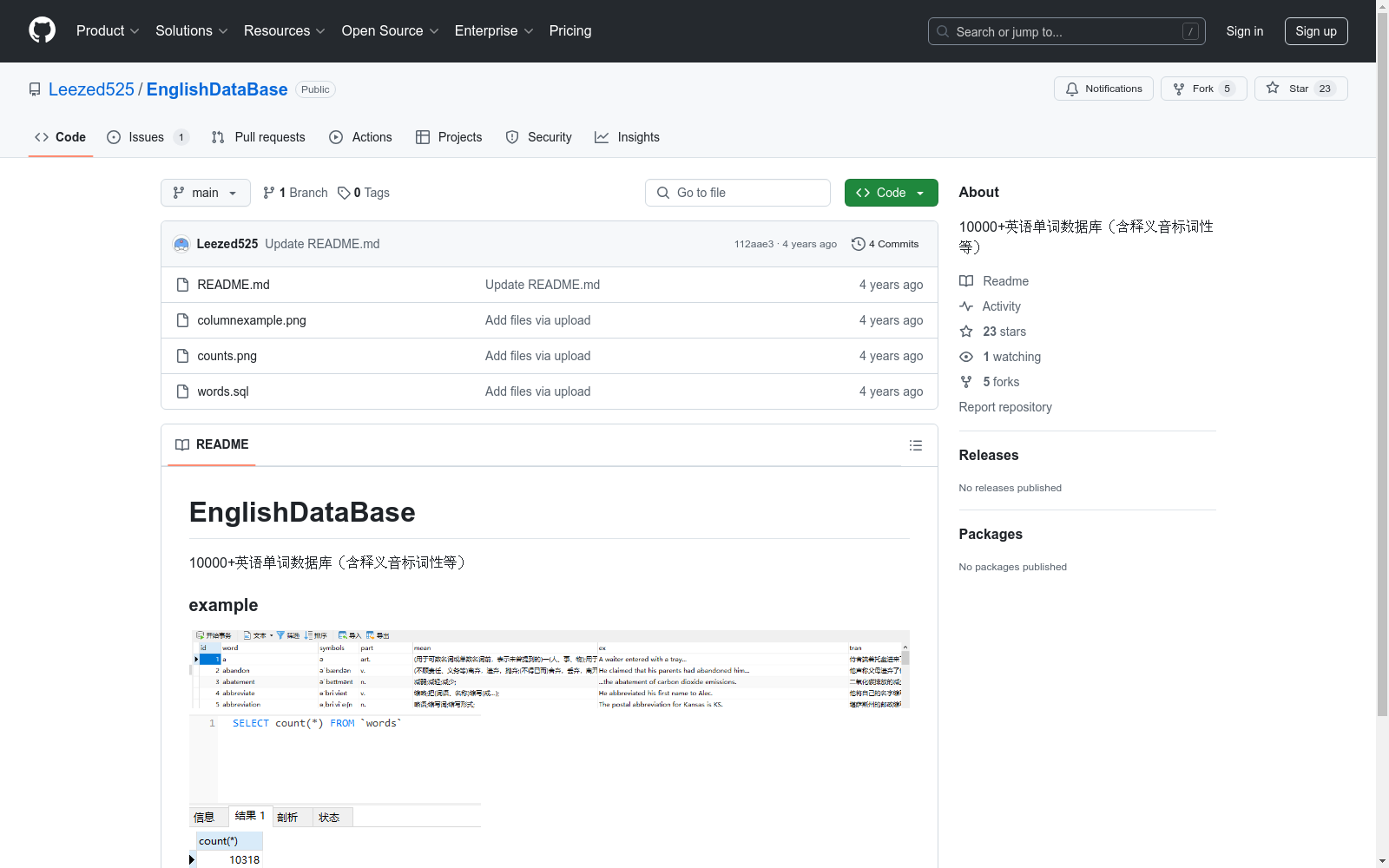
10000+英语单词数据库(含释义音标词性等)
A database of over 10,000 English words, including definitions, phonetic symbols, and parts of speech.
创建时间:
2021-12-01
原始信息汇总
EnglishDataBase
- 规模: 包含10000+英语单词
- 内容: 每个单词包含释义、音标、词性等信息
- 示例: 提供两个示例图像,展示数据集的部分内容和统计信息
搜集汇总
数据集介绍
构建方式
EnglishDataBase数据集的构建基于对大量英语单词的系统性收集与整理,涵盖了超过10000个常用词汇。每个单词均经过详细的标注,包括其释义、音标、词性等关键信息,确保数据的全面性与准确性。数据来源广泛,结合了权威词典与语言学研究成果,构建过程严格遵循语言学标准,确保了数据的高质量与可靠性。
特点
该数据集的核心特点在于其丰富的词汇覆盖与多维度的信息标注。每个单词不仅包含基础释义,还提供了音标与词性等语言学特征,便于用户进行深入的语言学研究或语言学习。数据集的规模适中,既保证了广泛的应用场景,又避免了数据冗余。此外,数据的结构化存储方式使得其易于集成到各类自然语言处理任务中。
使用方法
EnglishDataBase数据集适用于多种语言学研究与自然语言处理任务。用户可通过直接访问数据集文件,获取所需的词汇信息,并将其应用于词汇分析、语言模型训练或英语学习工具的开发。数据集以结构化格式存储,支持多种编程语言的数据读取与处理。对于研究人员与开发者而言,该数据集提供了便捷的API接口,便于快速集成到现有系统中,提升开发效率。
背景与挑战
背景概述
EnglishDataBase是一个包含超过10,000个英语单词的数据库,涵盖了单词的释义、音标和词性等详细信息。该数据集的创建旨在为语言学习、自然语言处理(NLP)以及相关领域的研究提供基础数据支持。尽管具体的创建时间和主要研究人员信息未在README中明确提及,但其广泛的应用场景表明其在英语学习和NLP领域具有重要影响力。通过提供丰富的词汇信息,EnglishDataBase为语言模型的训练、词汇分析以及教育工具的开发提供了宝贵的资源。
当前挑战
EnglishDataBase面临的挑战主要体现在两个方面。首先,在解决领域问题方面,尽管数据集提供了丰富的词汇信息,但其在词汇覆盖范围、释义的准确性以及音标的标准化方面仍存在改进空间。特别是在处理多义词、俚语或新兴词汇时,数据集的完整性和时效性可能受到限制。其次,在构建过程中,如何确保数据的准确性和一致性是一个关键挑战。词汇的释义和音标可能因地区或语境的不同而有所差异,这要求数据集构建者具备高度的语言学知识和数据处理能力,以确保数据的可靠性和广泛适用性。
常用场景
经典使用场景
EnglishDataBase数据集广泛应用于英语教学和语言学研究领域。该数据集包含超过10000个英语单词的详细信息,如释义、音标和词性等,为语言学习者提供了一个全面的词汇学习资源。教育工作者可以利用该数据集设计课程内容,帮助学生系统地掌握英语词汇。
实际应用
在实际应用中,EnglishDataBase数据集被广泛用于开发语言学习应用程序和在线词典工具。其丰富的词汇信息为智能翻译系统、语音识别技术以及自然语言处理算法提供了基础数据支持,显著提升了这些技术的准确性和实用性。
衍生相关工作
基于EnglishDataBase数据集,许多经典的语言学研究工作得以展开。例如,研究人员利用该数据集开发了基于深度学习的词汇预测模型,并在自然语言处理领域取得了显著成果。此外,该数据集还催生了多款高效的语言学习工具,进一步推动了语言教育技术的创新与发展。
以上内容由遇见数据集搜集并总结生成


