dataset__countdown__num_range-3__bf_scored
收藏Hugging Face2025-06-13 更新2025-06-14 收录
下载链接:
https://huggingface.co/datasets/TAUR-dev/dataset__countdown__num_range-3__bf_scored
下载链接
链接失效反馈官方服务:
资源简介:
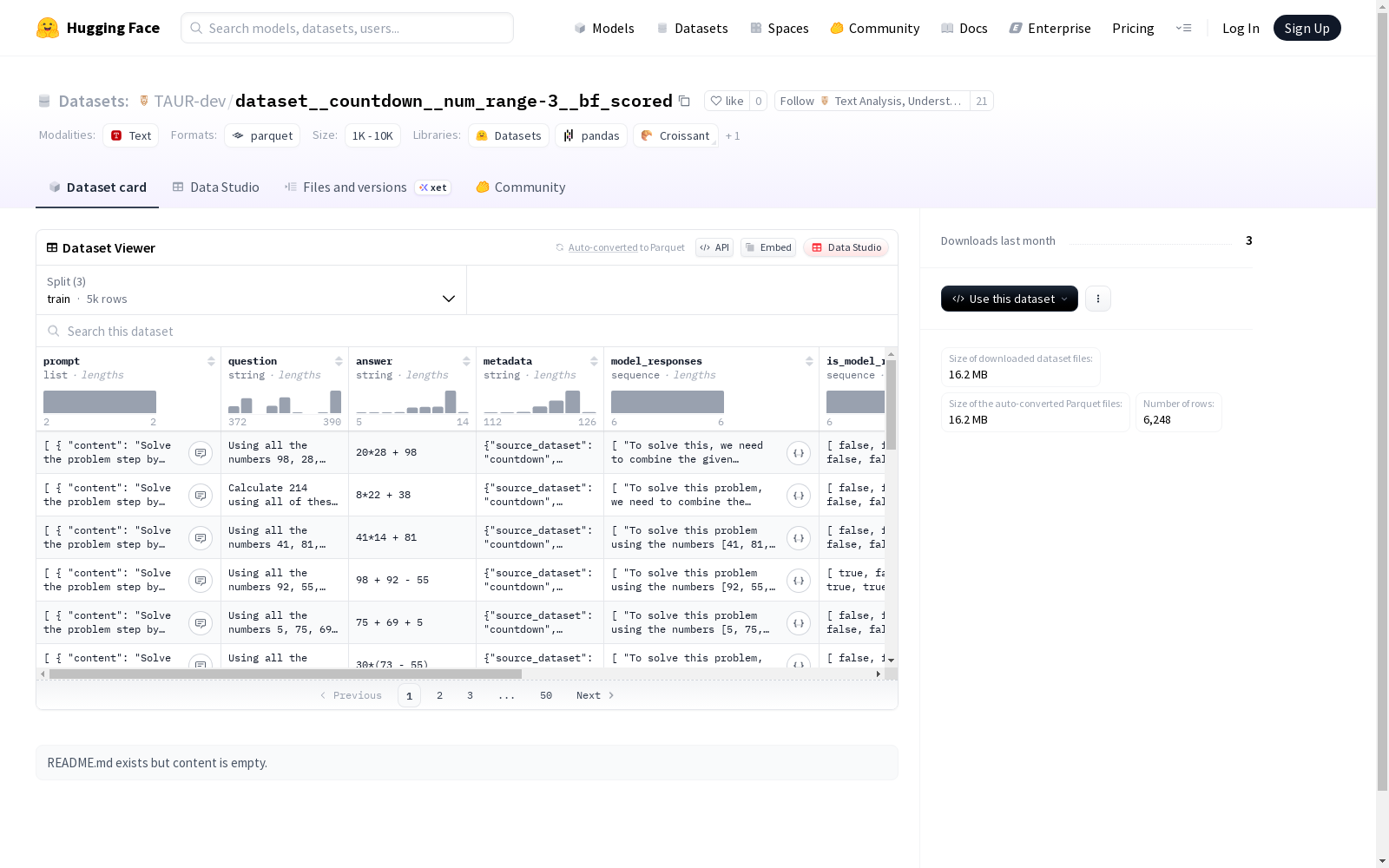
这个数据集是一个对话数据集,包含了对话的上下文(prompt)、问题(question)、答案(answer)、元数据(metadata)、模型的响应(model_responses)以及模型响应的正确性评估(is_model_response_correct)。数据集分为训练集、验证集和测试集,每个集合都包含了25个示例。
创建时间:
2025-06-13
搜集汇总
数据集介绍
构建方式
在人工智能与自然语言处理领域,数据集的质量直接影响模型评估的可靠性。该数据集通过精心设计的流程构建,首先定义问题生成规则,基于数字范围约束创建多样化提示,随后利用自动化脚本生成问答对,并引入模型响应验证机制,确保数据的一致性与准确性。构建过程中严格划分训练、验证与测试子集,保障了数据的结构化和可用性。
特点
该数据集具备多维度特征,核心在于其结构化设计,包含提示内容、问题、答案及元数据等字段,支持序列化模型响应与正确性标注。其独特之处在于融合了最终答案和推理过程的双重验证,增强了数据深度。规模上涵盖近六千样本,划分为训练、验证和测试集,平衡了数据量与评估需求,适用于复杂语言模型的分析任务。
使用方法
数据集主要用于评估语言模型的推理与响应能力,用户可加载标准格式数据,通过提示和问题输入模型,比对生成响应与标注答案。使用方法包括解析JSON结构,利用正确性标签进行性能量化,或结合元数据深入分析错误模式。其划分清晰的子集支持交叉验证,为模型优化提供可靠基准。
背景与挑战
背景概述
在人工智能推理能力快速发展的背景下,dataset__countdown__num_range-3__bf_scored数据集应运而生,专注于评估模型在受限数值范围内的数学推理与问题解决能力。该数据集由专业研究团队构建,核心研究问题在于测试模型执行多步算术运算和逻辑推理的准确性,特别是在面对复杂计数任务时的表现。通过提供结构化的提示-问题-答案三元组,该数据集为推进计算推理领域的发展提供了重要基准,显著促进了模型在数学逻辑理解和执行方面的进步。
当前挑战
该数据集旨在解决数学问题求解中的模型推理挑战,包括处理多步算术操作和确保最终答案的精确性。构建过程中的挑战涉及生成多样化的数值问题实例,同时维护数据的一致性和质量;准确标注模型响应的正确性,并解析其推理步骤的合理性也是一大难点,需确保评估指标能可靠反映模型的真实能力。
常用场景
经典使用场景
在算术推理评估领域,该数据集通过设计特定范围的数字倒计时问题,为大型语言模型的数学逻辑能力测试提供了标准化基准。其结构化的问题与答案对能够系统检验模型在多步运算、符号推理及数值准确性方面的表现,成为衡量模型数学智能的核心工具之一。
解决学术问题
该数据集有效解决了人工智能研究中算术推理能力量化评估的难题,为模型在受限数字范围内的精确计算、逻辑链条构建以及错误模式分析提供了数据支撑。其意义在于建立了可复现的评估框架,推动了符号推理与数值计算结合的研究方向,对提升模型的可解释性与可靠性具有重要影响。
衍生相关工作
基于该数据集的结构,多项研究扩展了其在多步推理、对抗性样本检测和模型自我修正机制方面的应用。例如,有工作将其与符号引擎结合构建混合推理系统,也有研究利用其错误响应分析模型幻觉现象,推动了推理可靠性及评估方法学的进一步发展。
以上内容由遇见数据集搜集并总结生成


