【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
Sequential-NIAH
收藏arXiv2025-04-09 更新2025-04-09 收录
下载链接:
https://anonymous.4open.science/r/Sequential-NIAH-Benchmark-88B7
下载链接
链接失效反馈官方服务:
资源简介:
Sequential-NIAH数据集是由腾讯优图实验室创建的,旨在评估大型语言模型处理长文本上下文并从中提取顺序信息的能力。该数据集包含三种类型的针生成管道:合成针、真实针和开放域问答针,涵盖了从8K到128K令牌长度的上下文。它由14,000个样本组成,其中2,000个用于测试。数据集通过将顺序针插入到长文本中,以评估模型在理解和提取长文本中顺序信息方面的性能。
提供机构:
腾讯优图实验室
创建时间:
2025-04-07
搜集汇总
数据集介绍
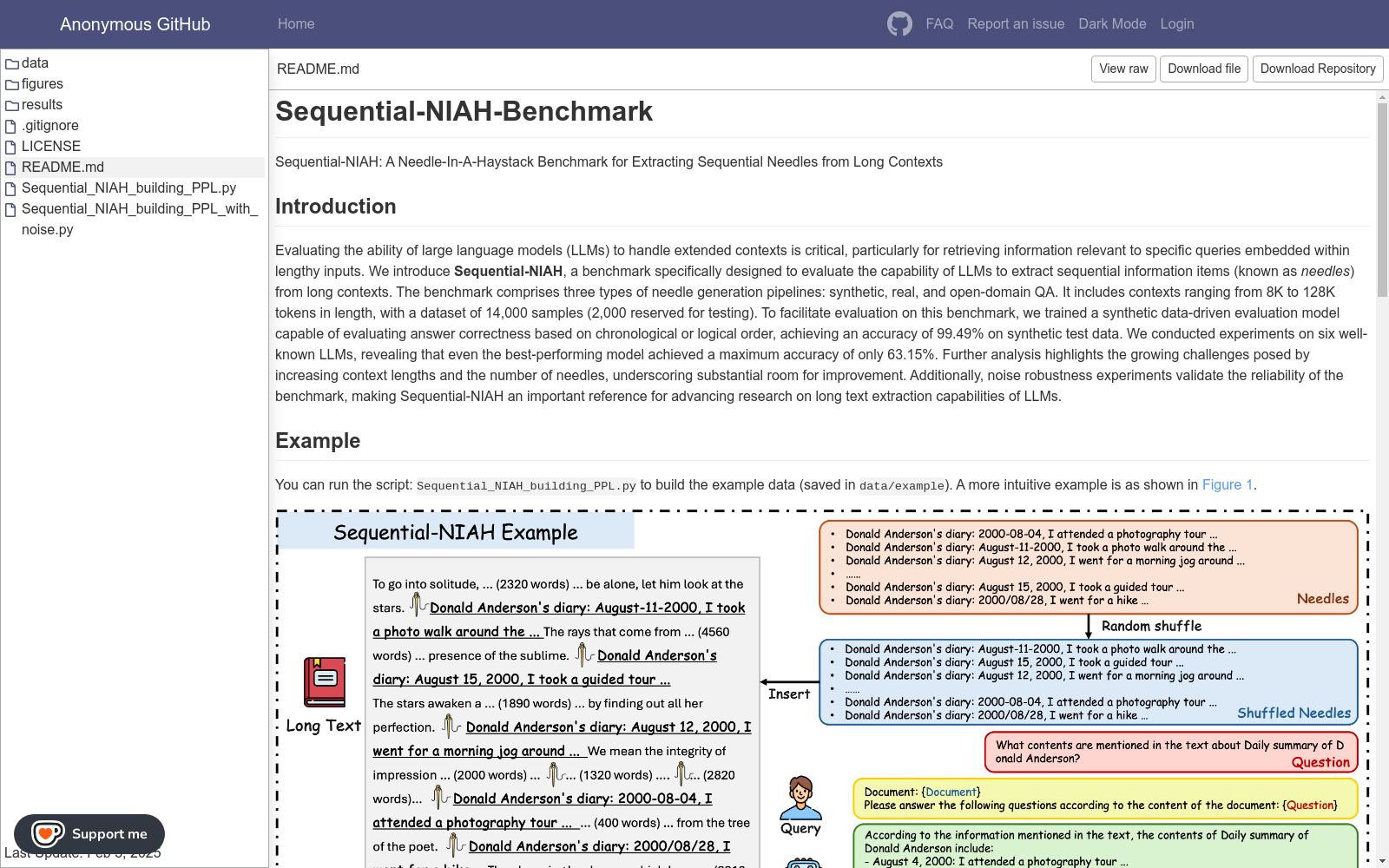
构建方式
Sequential-NIAH数据集的构建采用了多阶段合成流程,通过三种不同的针状信息生成管道(合成针、真实针和开放域问答针)来创建具有时序或逻辑顺序的问答对。合成针通过预定义的模板生成虚构实体的时序事件;真实针则从时序知识图谱(如ICEWS和FEG)中提取真实事件;开放域问答针则筛选自私有问答资源库中具有明确逻辑顺序的问答对。随后,这些针状信息被随机打乱并插入到从真实长文本语料库(LongData-Corpus)中抽取的8K至128K tokens不等的长文本中,形成最终的测试样本。
特点
该数据集的核心特点在于其专注于评估大语言模型从长文本中提取时序或逻辑顺序信息的能力。其独特价值体现在:1)覆盖三种不同来源的针状信息,确保评估的多样性;2)文本长度跨度大(8K-128K tokens),能全面测试模型的长文本处理能力;3)包含14,000个样本(含2,000测试样本),具有统计学意义;4)支持中英双语评估,满足跨语言研究需求。特别值得注意的是,该数据集通过精心设计的噪声分析模块,能够验证模型在信息位置扰动情况下的稳定性。
使用方法
使用该数据集时,研究者可通过标准化的评估流程测试模型性能:首先将长文本与打乱顺序的针状信息组合为输入,要求模型根据问题重构原始顺序的信息项。评估采用专门训练的评判模型(基于Qwen2.5-Instruct-32B微调),该模型能自动判断答案的正确性及顺序准确性,在测试集上达到99.49%的评判准确率。针对不同研究需求,可以分别测试模型在时序顺序(合成针/真实针)和逻辑顺序(开放域问答针)任务上的表现,或分析文本长度、针状信息数量等因素对模型性能的影响。
背景与挑战
背景概述
Sequential-NIAH是由腾讯优图实验室于2025年提出的一个基准测试数据集,旨在评估大语言模型(LLMs)从长上下文中提取顺序信息的能力。该数据集由合成针、真实针和开放域问答针三种类型组成,涵盖了从8K到128K令牌的不同长度上下文,共包含14,000个样本。Sequential-NIAH的提出填补了现有长上下文理解基准测试在顺序信息提取任务上的空白,为相关研究提供了重要的参考。该数据集的核心研究问题是评估模型在长上下文中检索并按时间或逻辑顺序排列信息的能力,对推动大语言模型在长文本理解领域的发展具有重要意义。
当前挑战
Sequential-NIAH面临的主要挑战包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,该数据集旨在解决从长文本中提取并按顺序排列信息的难题,这对模型的上下文理解、信息检索和逻辑推理能力提出了极高要求。实验表明,即使是性能最佳的模型在该任务上的准确率也仅为63.15%。在构建过程方面,研究人员需要设计多样化的针生成管道,确保数据真实性和任务复杂性;同时需要开发专门的评估模型,以应对顺序信息提取任务特有的评估挑战。此外,处理不同长度文本和数量不等的针信息也增加了数据集的构建难度。
常用场景
经典使用场景
Sequential-NIAH数据集专为评估大语言模型(LLMs)在长文本中提取时序或逻辑顺序信息的能力而设计。其经典使用场景包括从长达128K标记的文本中检索并排列具有明确时间或逻辑顺序的“针”(needles),例如从混杂的日记条目中按时间顺序整理事件,或从技术文档中还原步骤流程。该数据集通过合成、真实及开放领域QA三类数据管道,模拟了现实场景中信息检索的复杂性。
解决学术问题
该数据集解决了长文本信息检索中两大核心学术问题:一是模型在超长上下文中的细粒度信息定位能力,二是对时序/逻辑关系的理解与重建能力。通过引入乱序插入的“针”和严格顺序的参考答案,它量化了LLMs在信息完整性与顺序准确性上的表现差异,揭示了现有模型在长文本处理中普遍存在的顺序敏感性缺陷(最高准确率仅63.15%),为改进模型的长程依赖建模提供了明确方向。
衍生相关工作
该数据集推动了长文本评估范式的创新,直接启发了后续如NeedleBench等多针检索基准的构建。其提出的合成评估模型(准确率99.49%)被广泛应用于∞Bench等长上下文评测框架中。基于该数据集的分析结论,Gemini-1.5等模型改进了位置编码策略,而Qwen-2.5则优化了时序推理模块,显著提升了在128K上下文窗口中的顺序保持能力。
以上内容由遇见数据集搜集并总结生成


